首先什么是注解?@Override就是注解,它的作用是:
1、检查是否正确的重写了父类中的方法。
2、标明代码,这是一个重写的方法。
1、体现在于:检查子类重写的方法名与参数类型是否正确;检查方法private/final/static等不能被重写。实际上@Override对于应用程序并没有实际影响,从它的源码中可以出来。
2、主要是表现出代码的可读性。
作为Android开发中熟知的注解,Override只是注解的一种体现,更多时候,注解还有以下作用:
降低项目的耦合度。
自动完成一些规律性的代码。
自动生成java代码,减轻开发者的工作量。
一、注解基础快读
1、元注解
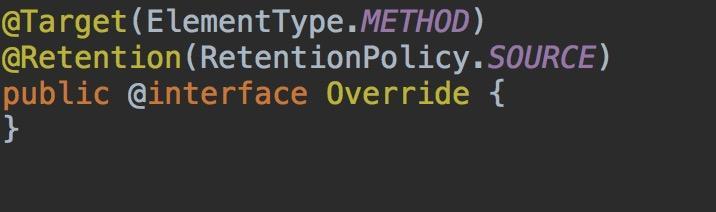
元注解是由java提供的基础注解,负责注解其它注解,如上图Override被@Target和@Retention修饰,它们用来说明解释其它注解,位于sdk/sources/android-25/java/lang/annotation路径下。
元注解有:
@Retention:注解保留的生命周期
@Target:注解对象的作用范围。
@Inherited:@Inherited标明所修饰的注解,在所作用的类上,是否可以被继承。
@Documented:如其名,javadoc的工具文档化,一般不关心。
@Retention
Retention说标明了注解被生命周期,对应RetentionPolicy的枚举,表示注解在何时生效:
SOURCE:只在源码中有效,编译时抛弃,如上面的
@Override。CLASS:编译class文件时生效。
RUNTIME:运行时才生效。
如下图,com.android.support:support-annotations中的Nullable注解,会在编译期判断,被注解的参数是否会空,具体后续分析。

@Target
Target标明了注解的适用范围,对应ElementType枚举,明确了注解的有效范围。
TYPE:类、接口、枚举、注解类型。
FIELD:类成员(构造方法、方法、成员变量)。
METHOD:方法。
PARAMETER:参数。
CONSTRUCTOR:构造器。
LOCAL_VARIABLE:局部变量。
ANNOTATION_TYPE:注解。
PACKAGE:包声明。
TYPE_PARAMETER:类型参数。
TYPE_USE:类型使用声明。
如上图所示,@Nullable可用于注解方法,参数,类成员,注解,包声明中,常用例子如下所示:
/**
* Nullable表明
* bind方法的参数target和返回值Data可以为null
*/
@Nullable
public static Data bind(@Nullable Context target) { //do someThing and return
return bindXXX(target);
}
@Inherited
注解所作用的类,在继承时默认无法继承父类的注解。除非注解声明了 @Inherited。同时Inherited声明出来的注,只对类有效,对方法/属性无效。
如下方代码,注解类@AInherited声明了Inherited ,而注解BNotInherited 没有,所在在它们的修饰下:
类Child继承了父类Parent的
@AInherited,不继承@BNotInherited;重写的方法
testOverride()不继承Parent的任何注解;
testNotOverride()因为没有被重写,所以注解依然生效。
@Retention(RetentionPolicy.RUNTIME)
@Inherited public @interface AInherited {
String value();
}
@Retention(RetentionPolicy.RUNTIME)
public @interface BNotInherited {
String value();
}
@AInherited("Inherited")
@BNotInherited("没Inherited")
public class Parent {
@AInherited("Inherited")
@BNotInherited("没Inherited")
public void testOverride(){
}
@AInherited("Inherited")
@BNotInherited("没Inherited")
public void testNotOverride(){
}
}
/**
* Child继承了Parent的AInherited注解
* BNotInherited因为没有@Inherited声明,不能被继承
*/public class Child extends Parent {
/**
* 重写的testOverride不继承任何注解
* 因为Inherited不作用在方法上
*/
@Override
public void testOverride() {
}
/**
* testNotOverride没有被重写
* 所以注解AInherited和BNotInherited依然生效。
*/}
2、自定义注解
2.1 运行时注解
了解了元注解后,看看如何实现和使用自定义注解。这里我们简单介绍下运行时注解RUNTIME,编译时注解CLASS留着后面分析。
首先,创建一个注解遵循: public @interface 注解名 {方法参数},如下方@getViewTo注解:
@Target({ElementType.FIELD})@Retention(RetentionPolicy.RUNTIME)public @interface getViewTo { int value() default -1;
}
然后如下方所示,我们将注解描述在Activity的成员变量mTv和mBtn中,在App运行时,通过反射将findViewbyId得到的控件,注入到mTv和mBtn中。
是不是很熟悉,有点ButterKnife的味道?当然,ButterKnife比这个高级多,毕竟反射多了影响效率,不过我们明白了,可以通过注解来注入和创建对象,这样可以在一定程度节省代码量。
public class MainActivity extends AppCompatActivity { @getViewTo(R.id.textview) private TextView mTv; @getViewTo(R.id.button) private Button mBtn; @Override
protected void onCreate(Bundle savedInstanceState) { super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main); //通过注解生成View;
getAllAnnotationView();
} /**
* 解析注解,获取控件
*/
private void getAllAnnotationView() { //获得成员变量
Field[] fields = this.getClass().getDeclaredFields(); for (Field field : fields) { try { //判断注解
if (field.getAnnotations() != null) { //确定注解类型
if (field.isAnnotationPresent(GetViewTo.class)) { //允许修改反射属性
field.setAccessible(true);
GetViewTo getViewTo = field.getAnnotation(GetViewTo.class); //findViewById将注解的id,找到View注入成员变量中
field.set(this, findViewById(getViewTo.value()));
}
}
} catch (Exception e) {
}
}
}
}
2.2 编译时注解
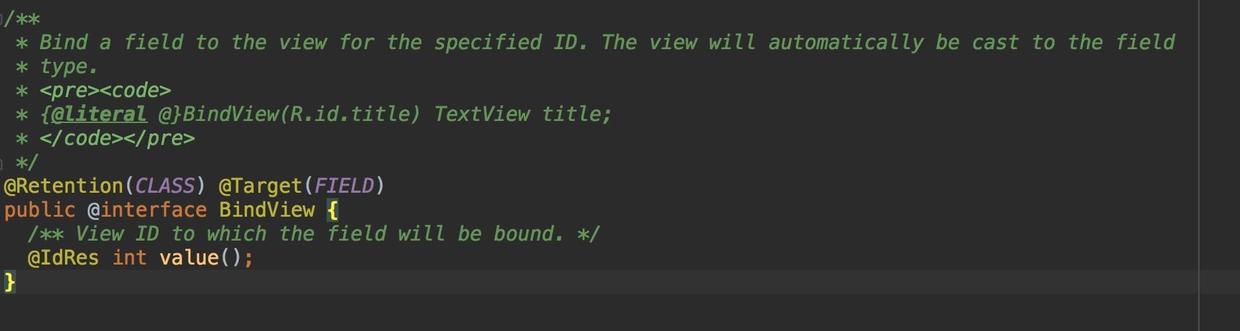
运行时注解RUNTIME如上2.1所示,大多数时候实在运行时使用反射来实现所需效果,这很大程度上影响效率,如果BufferKnife的每个View注入不可能如何实现。实际上,ButterKnife使用的是编译时注解CLASS,如下图X2.2,是ButterKnife的@BindView注解,它是一个编译时注解,在编译时生成对应java代码,实现注入。
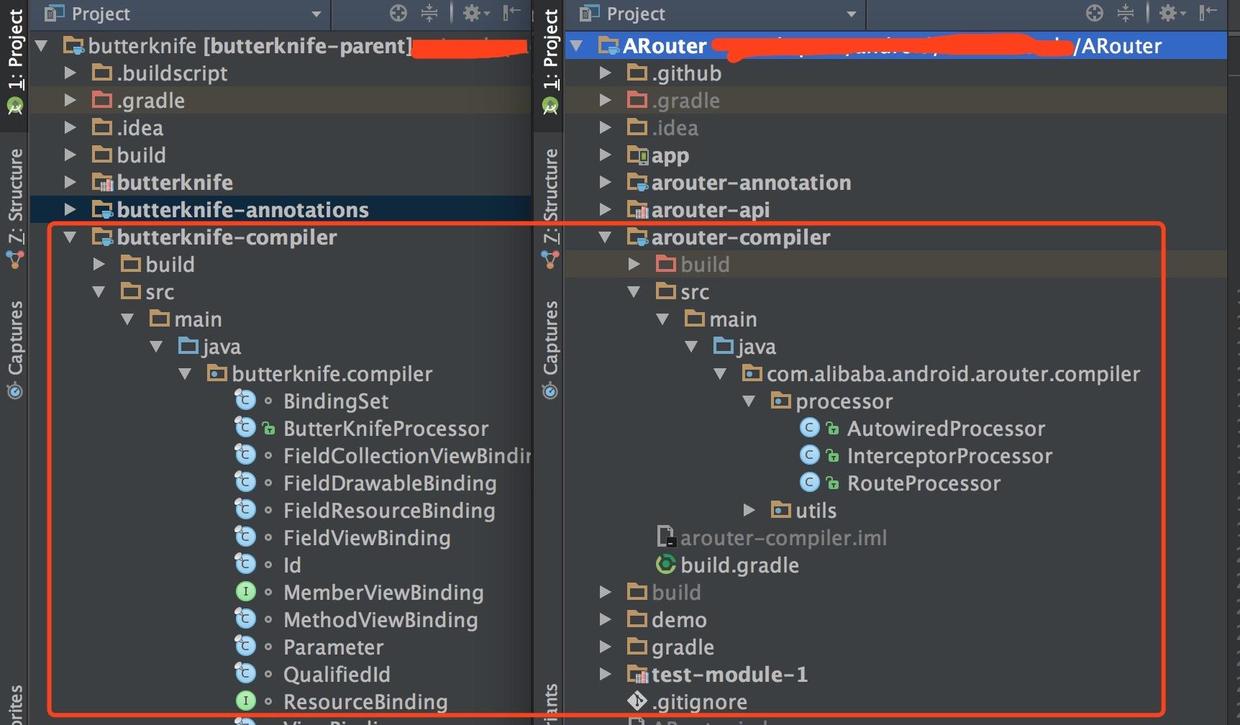
说到编译时注解,就不得不说注解处理器 AbstractProcessor,如果你有注意,一般第三方注解相关的类库,如bufferKnike、ARouter,都有一个Compiler命名的Module,如下图X2.3,这里面一般都是注解处理器,用于编译时处理对应的注解。
注解处理器(Annotation Processor)是javac的一个工具,它用来在编译时扫描和处理注解(Annotation)。你可以对自定义注解,并注册相应的注解处理器,用于处理你的注解逻辑。
如下所示,实现一个自定义注解处理器,至少重写四个方法,并且注册你的自定义Processor,详细可参考下方代码CustomProcessor。
@AutoService(Processor.class),谷歌提供的自动注册注解,为你生成注册Processor所需要的格式文件(
com.google.auto相关包)。init(ProcessingEnvironment env),初始化处理器,一般在这里获取我们需要的工具类。
getSupportedAnnotationTypes(),指定注解处理器是注册给哪个注解的,返回指定支持的注解类集合。
getSupportedSourceVersion() ,指定java版本。
process(),处理器实际处理逻辑入口。
@AutoService(Processor.class)public class CustomProcessor extends AbstractProcessor { /**
* 注解处理器的初始化
* 一般在这里获取我们需要的工具类
* @param processingEnvironment 提供工具类Elements, Types和Filer
*/
@Override
public synchronized void init(ProcessingEnvironment env){
super.init(env); //Element代表程序的元素,例如包、类、方法。
mElementUtils = env.getElementUtils(); //处理TypeMirror的工具类,用于取类信息
mTypeUtils = env.getTypeUtils(); //Filer可以创建文件
mFiler = env.getFiler(); //错误处理工具
mMessages = env.getMessager();
} /**
* 处理器实际处理逻辑入口
* @param set
* @param roundEnvironment 所有注解的集合
* @return
*/
@Override
public boolean process(Set<? extends TypeElement> annoations,
RoundEnvironment env) { //do someThing
} //指定注解处理器是注册给哪个注解的,返回指定支持的注解类集合。
@Override
public Set<String> getSupportedAnnotationTypes() {
Set<String> sets = new LinkedHashSet<String>(); //大部分class而已getName、getCanonicalNam这两个方法没有什么不同的。
//但是对于array或内部类等就不一样了。
//getName返回的是[[Ljava.lang.String之类的表现形式,
//getCanonicalName返回的就是跟我们声明类似的形式。
sets(BindView.class.getCanonicalName()); return sets;
} //指定Java版本,一般返回最新版本即可
@Override
public SourceVersion getSupportedSourceVersion() { return SourceVersion.latestSupported();
}
}
首先,我们梳理下一般处理器处理逻辑:
1、遍历得到源码中,需要解析的元素列表。
2、判断元素是否可见和符合要求。
3、组织数据结构得到输出类参数。
4、输入生成java文件。
5、错误处理。
然后,让我们理解一个概念:Element,因为它是我们获取注解的基础。
Processor处理过程中,会扫描全部Java源码,代码的每一个部分都是一个特定类型的Element,它们像是XML一层的层级机构,比如类、变量、方法等,每个Element代表一个静态的、语言级别的构件,如下方代码所示。
package android.demo; // PackageElement// TypeElementpublic class DemoClass { // VariableElement
private boolean mVariableType; // VariableElement
private VariableClassE m VariableClassE; // ExecuteableElement
public DemoClass () {
} // ExecuteableElement
public void resolveData (Demo data //TypeElement ) {
}
}
其中,Element代表的是源代码,而TypeElement代表的是源代码中的类型元素,例如类。然而,TypeElement并不包含类本身的信息。你可以从TypeElement中获取类的名字,但是你获取不到类的信息,例如它的父类。这种信息需要通过TypeMirror获取。你可以通过调用elements.asType()获取元素的TypeMirror。
1、知道了Element,我们就可以通过process 中的RoundEnvironment去获取,扫描到的所有元素,如下图X2.4,通过env.getElementsAnnotatedWith,我们可以获取被@BindView注解的元素的列表,其中validateElement校验元素是否可用。
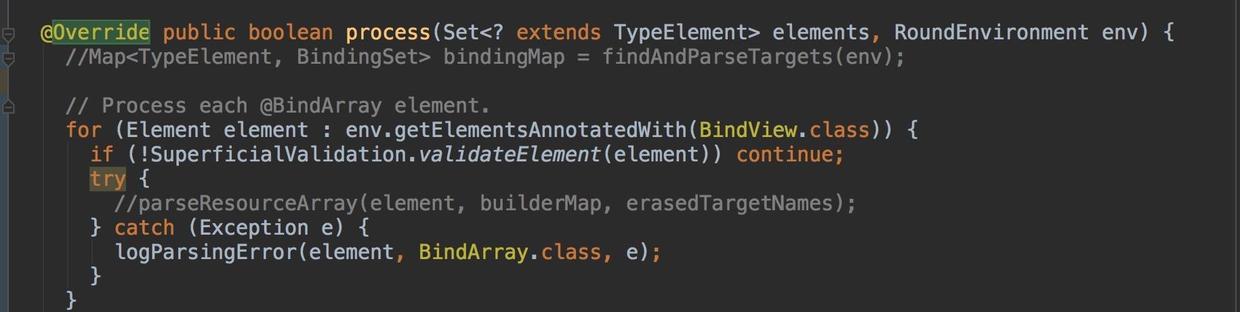
2、因为env.getElementsAnnotatedWith返回的,是所有被注解了@ BindView的元素的列表。所以有时候我们还需要走一些额外的判断,比如,检查这些Element是否是一个类:
@Override
public boolean process(Set<? extends TypeElement> an, RoundEnvironment env) { for (Element e : env.getElementsAnnotatedWith(BindView.class)) { // 检查元素是否是一个类
if (ae.getKind() != ElementKind.CLASS) {
...
}
}
...
}
3、javapoet (com.squareup:javapoet)是一个根据指定参数,生成java文件的开源库,有兴趣了解javapoet的可以看下javapoet——让你从重复无聊的代码中解放出来,在处理器中,按照参数创建出 JavaFile之后,通Filer利用javaFile.writeTo(filer);就可以生成你需要的java文件。
4、错误处理,在处理器中,我们不能直接抛出一个异常,因为在process()中抛出一个异常,会导致运行注解处理器的JVM崩溃,导致跟踪栈信息十分混乱。因此,注解处理器就有一个Messager类,一般通过messager.printMessage( Diagnostic.Kind.ERROR, StringMessage, element)即可正常输出错误信息。
至此,你的注解处理器完成了所有的逻辑。可以看出,编译时注解实在编译时生成java文件,然后将生产的java文件注入到源码中,在运行时并不会像运行时注解一样,影响效率和资源。
总结
我们就利用ButterKnife的流程,简单举例做个总结吧。
1、
@BindView在编译时,根据Acitvity生产了XXXActivity$$ViewBinder.java。2、Activity中调用的
ButterKnife.bind(this);,通过this的类名字,加$$ViewBinder,反射得到了ViewBinder,和编译处理器生产的java文件关联起来了,并将其存在map中缓存,然后调用ViewBinder.bind()。3、在ViewBinder的bind方法中,通过id,利用ButterKnife的
butterknife.internal.Utils工具类中的封装方法,将findViewById()控件注入到Activity的参数中。
好了,通过上面的流程,是不是把编译时注解的生成和使用连接起来了呢?
本文只是介绍了Android注解基础内容,解读实例代码的具体作用,更深入的关于Android注解内容可以阅读下面相关文章
最后
以上就是幸福钢笔最近收集整理的关于Android注解基础介绍快速入门与解读的全部内容,更多相关Android注解基础介绍快速入门与解读内容请搜索靠谱客的其他文章。








发表评论 取消回复