说明
在处理文本的时候,第一步往往是将字符串进行分词,得到一个个关键词。苹果从很早就开始支持中文分词了,而且我们几乎人人每天都会用到,回想一下,在使用手机时,长按一段文字,往往会选中按住位置的一个词语,这里就是一个分词的绝佳用例,而iOS自带的分词效果非常棒,大家可以自己平常注意观察一下,基本对中文也有很好的效果。而这个功能也开放了API供开发者调用,我试用了一下,很好用!
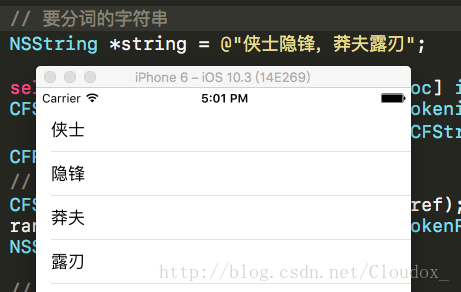
效果如下:
实现
其实苹果给出了完整的API,想要全面了解的可以直接看文档:CFStringTokenizer Reference
这里说说简单的一个实现:
// 要分词的字符串
NSString *string = @"侠士隐锋,莽夫露刃";
self.keywords = [[NSMutableArray alloc] init];
CFStringTokenizerRef ref = CFStringTokenizerCreate(NULL, (__bridge CFStringRef)string, CFRangeMake(0, string.length), kCFStringTokenizerUnitWord, NULL);// 创建分词器
CFRange range;// 当前分词的位置
// 获取第一个分词的范围
CFStringTokenizerAdvanceToNextToken(ref);
range = CFStringTokenizerGetCurrentTokenRange(ref);
// 循环遍历获取所有分词并记录到数组中
NSString *keyWord;
while (range.length>0) {
keyWord = [string substringWithRange:NSMakeRange(range.location, range.length)];
[self.keywords addObject:keyWord];
CFStringTokenizerAdvanceToNextToken(ref);
range = CFStringTokenizerGetCurrentTokenRange(ref);
}
其实逻辑很简单:创建分词器–>一个个地一次获取分词后的每个词的起始位置和长度,从而取出词。
示例里我用列表显示每个分词,比较清楚,列表的实现就不说明了,可以直接看工程代码。
值得一提的是,其分词速度很快,甚至一些网络词汇比如“木有”,一些成语等等都能够识别出,能看出这是分词的什么吗:

示例工程:https://github.com/Cloudox/OXStringTokenizerDemo
本地下载:http://xiazai.uoften.com/201706/yuanma/OXStringTokenizerDemo(uoften.com).rar
总结
以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作能带来一定的帮助,如果有疑问大家可以留言交流,谢谢大家对靠谱客的支持。
最后
以上就是现实香氛最近收集整理的关于iOS中自带超强中文分词器的实现方法的全部内容,更多相关iOS中自带超强中文分词器内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复