注:学习本篇的前提是要会插入排序,数据结构与算法——排序算法-插入排序
插入排序存在的问题
简单的插入排序可能存在的问题。
如数组 arr = {2,3,4,5,6,1} 这时需要插入的数 1(最小),过程是:
展示的是要移动 1 这个数,的过程,由于在最后,需要前面的所有数都往后移动一位
{2,3,4,5,6,6}
{2,3,4,5,5,6}
{2,3,4,4,5,6}
{2,3,3,4,5,6}
{2,2,3,4,5,6}
{1,2,3,4,5,6}
结论:当需要插入的数是较小的数时,后移的次数明显增多,对效率有影响。
简单介绍
希尔排序(Shell's Sort)是希尔(Donald Shell)于 1959 年提出的一种排序算法。
希尔排序也是一种 插入排序(Insertion sort),是将整个无序列分割成若干小的子序列分别进行插入排序的方法,它是简单插入排序经过改进后的一个 更高效的版本,也称为 缩小增量排序。时间复杂度 O(n^(1.3—2)
关于插入排序请看 数据结构与算法——排序算法-插入排序
基本思想
希尔排序把记录按 下标的一定增量分组,对每组使用 直接插入排序算法 排序,随着 增量逐渐减少,每组包含的关键词越来越多(要排序的数),当增量减至 1 时,整个文件被分成一组,算法便终止。
光看上面的描述,对于首次接触的人来说,不知道是啥意思,举个例子,认真思考下面的说明:
- 原始数组:以下数据元素颜色相同为一组

- 初始增量为:
gap = length/2这里为gap = 10 / 2 = 5(length 是数组的大小)
那么意味着整个数组被分为 5 组。分别为 [8,3][9,5][1,4][7,6][2,0]
先看明白这里的增量为 5 ,就会分成 5 组。[8,3] 这一组来说,对比看下图,它的意思是:从 8 开始,下标增加 5 既对应的数是 3,所以他们分为一组
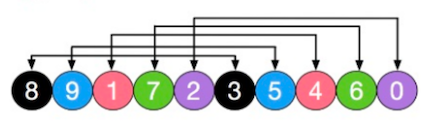
- 对上面的这 5 组分别进行 直接插入排序 ,也就是每一组分为有序列 和 无序列,例如
[8,3]这组,8 为有序列倒数第一个数 3为无序列第一个数。
结果如下图:可以看到,像 3、5、6 这些小的元素被调整到了前面。

然后缩小增量 gap = 5 / 2 = 2,则数组被分为 2 组 [3,1,0,9,7] 和 [5,6,8,4,2]
- 对以上 2 组再分别进行 直接插入排序,即每一组分为有序列 和 无序列,例如
[3,1,0,9,7]这组,3为有序列的倒数第一个数1为无序列第一个数。
结果如下图:可以看到,此时整个组数的有序程度更进一步。

然后再缩小增量 gap = 2 / 2 = 1,则整个数组被当成一组,再进行一次直接插入排序,即每一组分为有序列 和 无序列,0 为有序列的倒数第一个数 2为无序列第一个数。由于基本上是有序的了,所以少了很多次的调整。
动图:

经过上面的解析,应该对希尔排序有了初步的认识,为了更深入理解它的实现过程以及原理,下面通过代码进行演示。
代码实现
场景:有一群小牛,考试成绩分布是 {8,9,1,7,2,3,5,4,6,0},请从小到大排序。

对于希尔排序时,对有序序列在 插入 时,有以下两种方式:
- 交换法:容易理解,速度相对较慢 (初学者用来理解的)
- 移动法:不太容易理解,速度相对较快 (这个才算是真正的希尔排序)
先实现交换法,然后再优化成移动法。比较容易。但是我个人感觉,如果你学好了插入排序,移动法更容易理解。
特别注意
1.希尔排序,是一种插入排序,插入排序算法使用了的是移动法,上面基本思想也算是是用的移动法,但是基本思想是一个样的,什么移动法、交换法的只是一个数据移动方式。(这里先讲解交换法,便于理解)
2.希尔排序,对插入排序的改进,先分组,这里分组是通过增量步长和相关算法,来达到在循环中直接获取到这一个组的元素
3.直接排序的基本思想一定要记得,最重要的两个变量:无序列表中的第一个值,与有序列表中的最后一个值开始比较
/**
* 推到的方式来演示每一步怎么做,然后找规律
*/
@Test
public void processDemo() {
int arr[] = {8, 9, 1, 7, 2, 3, 5, 4, 6, 0};
System.out.println("原始数组:" + Arrays.toString(arr));
processShellSort(arr);
}
public void processShellSort(int[] arr) {
// 按照笔记中的基本思想,一共三轮
// 第 1 轮:初始数组 [8, 9, 1, 7, 2, 3, 5, 4, 6, 0]
// 将 10 个数字分成了 5 组( length / 2),增量也是 5,需要对 5 组进行排序
// 外层循环,并不是循环 5 次,只是这里巧合了。
// 一定要记得,希尔排序:先分组,在对每组进行插入排序
for (int i = 5; i < arr.length; i++) {
// 第 1 组:[8,3] , 分别对应原始数组的下标 0,5
// 第 2 组:[9,5] , 分别对应原始数组的下标 1,6
// ...
// 内层循环对 每一组 进行直接排序操作
// i = 5 ;j = 0, j-=5 = 0 - 5 = -5,跳出循环,arr[j] = 8 ,这是对第 1 组进行插入排序
// i = 6 ;j = 1, j-=5 = 1 - 5 = -4,跳出循环,arr[j] = 9 , 这是对第 2 组进行插入排序
// i = 7 ;j = 2, j-=5 = 2 - 5 = -3,跳出循环,arr[j] = 1 ,这是对第 3 组进行插入排序
// i = 8 ;j = 3, j-=5 = 3 - 5 = -2,跳出循环,arr[j] = 7 ,这是对第 4 组进行插入排序
// i = 9 ;j = 4, j-=5 = 4 - 5 = -1,跳出循环,arr[j] = 2 ,这是对第 5 组进行插入排序
for (int j = i - 5; j >= 0; j -= 5) {
// 如果当前元素大于加上步长后的那个元素,就交换
if (arr[j] > arr[j + 5]) {
int temp = arr[j];
arr[j] = arr[j + 5];
arr[j + 5] = temp;
}
}
}
System.out.println("第 1 轮排序后:" + Arrays.toString(arr));
// 第 2 轮:上一轮排序后的数组:[3, 5, 1, 6, 0, 8, 9, 4, 7, 2]
// 将 10 个数字分成了 2 组(上一次的增量 5 / 2),增量也为 2,需要对 2 组进行排序
for (int i = 2; i < arr.length; i++) {
// 第 1 组:[3,1,0,9,7] , 分别对应原始数组的下标 0,2,4,6,8
// 第 2 组:[5,6,8,4,2] , 分别对应原始数组的下标 1,3,5,7,9
// 内层循环对 每一组 进行直接排序操作
// i = 2 ;j = 0, j-=2 = 0 - 2 = -2,arr[j] = 3 ,跳出循环,
// 这是对第 1 组中的 3,1 进行比较,1 为无序列表中的比较元素,3 为有序列表中的最后一个元素,3 > 1,进行交换
// 交换后的数组:[1, 5, 3, 6, 0, 8, 9, 4, 7, 2]
// 第 1 组:[1,3,0,9,7]
// i = 3 ;j = 1, j-=2 = 1 - 2 = -1,arr[j] = 5 ,跳出循环
// 这是对第 2 组中的 5,6 进行比较,6 为无序列表中的比较元素,5 为有序列表中的最后一个元素,5 < 6,不进行交换
// 交换后的数组:[1, 5, 3, 6, 0, 8, 9, 4, 7, 2] , 没有交换
// 第 2 组:[5,6,8,4,2]
// i = 4 ;j = 2, j-=2 = 2 - 2 = 0,arr[j] = 3 ,
// 这是对第 1 组中的 3,0 进行比较,0 为无序列表中的比较元素,3 为有序列表中的最后一个元素,3 > 0,进行交换
// 交换后的数组:[1, 5, 0, 6, 3, 8, 9, 4, 7, 2],
// 第 1 组:[1,0,3,9,7]
// 由于 2 - 2 = 0,此时 j = 0,满足条件,继续循环 i = 4 :j = 0, j-=2 = 0 - 2 = -2,arr[j] = 1 ,跳出循环
// 这是对第 1 组中的有序列表中的剩余数据进行交换,1,0, 1>0 ,他们进行交换(这里也就是完成有序列的一个排序)
// 第 1 组:[0,1,3,9,7]
//虽然有可能本次的排序完成了但是排序循环还是会循环下去,直到循环结束,后面的移动法会解决该问题
//以此类推
for (int j = i - 2; j >= 0; j -= 2) {
if (arr[j] > arr[j + 2]) {
int temp = arr[j];
arr[j] = arr[j + 2];
arr[j + 2] = temp;
}
}
}
System.out.println("第 2 轮排序后:" + Arrays.toString(arr));
// 第 3 轮:上一轮排序后的数组:[0, 2, 1, 4, 3, 5, 7, 6, 9, 8]
// 将 10 个数字分成了 1 组(上一次的增量 2 / 2),增量也为 1,需要对 1 组进行排序
for (int i = 1; i < arr.length; i++) {
// 第 1 组:[0, 2, 1, 4, 3, 5, 7, 6, 9, 8]
// i = 1 :j = 0, j-=1 = 0 - 1 = -1,arr[j] = 0 ,跳出循环
// 0 为有序列表中的最后一个元素,2 为无须列表中要比较的元素。 0 < 2,不交换
// [0, 2 有序 <-> 无序, 1, 4, 3, 5, 7, 6, 9, 8]
// i = 2 :j = 1, j-=1 = 1 - 1 = o,arr[j] = 2 ,
// 2 为有序列表中的最后一个元素,1 为无序列表中要比较的元素, 2 > 1,交换
// 交换后:[0, 1, 2, 4, 3, 5, 7, 6, 9, 8]
// 由于不退出循环,还要比较有序列表中的数据,0 与 1 ,0 < 1 ,不交换,退出循环
//后面的以此类推,就是一个插入排序
for (int j = i - 1; j >= 0; j -= 1) {
if (arr[j] > arr[j + 1]) {
int temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
}
}
}
System.out.println("第 3 轮排序后:" + Arrays.toString(arr));
}
测试输出信息
原始数组:[8, 9, 1, 7, 2, 3, 5, 4, 6, 0]
第 1 轮排序后:[3, 5, 1, 6, 0, 8, 9, 4, 7, 2]
第 2 轮排序后:[0, 2, 1, 4, 3, 5, 7, 6, 9, 8]
第 3 轮排序后:[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
这里的两层循环一定明白是在做什么:
- 外层循环:不是控制组数,是为了内层循环 每一轮开始,都能 拿到某一组的无序列表第一个元素
arr[i]
难点:结束条件是数组长度,是为了能拿到数组中的所有元素,每增长一次,由于步长的因素,可能这一的元素就不是上一次的同一组了。
- 内层循环:拿到了这一组无序列表中第一个元素,只要减掉增量步长,就是有序列表中中的最后一个元素
arr[j](这里说的是 循环中的 int j = i - gap)
细品这里的含义,这就是 插入排序博客中 讲解的直接插入排序法的两个变量,不过之前讲解的算法是使用 移动法,这里使用了 交换法,每一轮开始,都从有序列表最后一个开始交换,直到这个有序列表的第一个元素(在此之前,这个组可能已经排序完成了),就退出循环。
从上述推导可以找到规律,只有每次的增量在变化,因此可以修改为如下方式
@Test
public void shellSortTest() {
int arr[] = {8, 9, 1, 7, 2, 3, 5, 4, 6, 0};
System.out.println("原始数组:" + Arrays.toString(arr));
shellSort(arr);
}
/**
* 根据前面的分析,得到规律,变化的只是增量步长,那么可以改写为如下方式
*/
public void shellSort(int[] arr) {
int temp = 0;
// 第 1 层循环:得到每一次的增量步长
for (int gap = arr.length / 2; gap > 0; gap /= 2) {
// 第 2 层和第 3 层循环,是对每一个增量中的每一组进行插入排序
for (int i = gap; i < arr.length; i++) {
for (int j = i - gap; j >= 0; j -= gap) {
if (arr[j] > arr[j + gap]) {
temp = arr[j];
arr[j] = arr[j + gap];
arr[j + gap] = temp;
}
}
}
System.out.println("增量为 " + gap + " 的这一轮排序后:" + Arrays.toString(arr));
}
}
测试输出
原始数组:[8, 9, 1, 7, 2, 3, 5, 4, 6, 0]
增量为 5 的这一轮排序后:[3, 5, 1, 6, 0, 8, 9, 4, 7, 2]
增量为 2 的这一轮排序后:[0, 2, 1, 4, 3, 5, 7, 6, 9, 8]
增量为 1 的这一轮排序后:[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
到这里其实希尔排序的思想就已经讲完了,只是目前的代码欠于优化,想必你们也觉得这个交换法有很多的不足,下面进行测试就一目了然了
大数据量耗时测试
/**
* 大量数据排序时间测试
*/
@Test
public void bulkDataSort() {
int max = 80_000;
// int max = 8;
int[] arr = new int[max];
for (int i = 0; i < max; i++) {
arr[i] = (int) (Math.random() * 80_000);
}
Instant startTime = Instant.now();
shellSort(arr);
// System.out.println(Arrays.toString(arr));
Instant endTime = Instant.now();
System.out.println("共耗时:" + Duration.between(startTime, endTime).toMillis() + " 毫秒");
}
多次测试输出
共耗时:10816 毫秒
共耗时:11673 毫秒
共耗时:11546 毫秒
由于是交换法的插入排序,时间耗时较久
移动法实现希尔排序
由于交换法上面测试速度也看到了,很慢。采用 数据结构与算法——排序算法-插入排序 中的移动法来对每组进行排序
/**
* 移动法希尔排序
*/
@Test
public void moveShellSortTest() {
int arr[] = {8, 9, 1, 7, 2, 3, 5, 4, 6, 0};
System.out.println("原始数组:" + Arrays.toString(arr));
moveShellSort(arr);
}
/**
* 插入排序采用移动法
*/
public void moveShellSort(int[] arr) {
// 第 1 层循环:得到每一次的增量步长
// 增量并逐步缩小增量
for (int gap = arr.length / 2; gap > 0; gap /= 2) {
/**
这里的内层循环,除了是获得每一组的值(按增量取),
移动法使用的是简单插入排序的算法 {@link InsertionSortTest#processSelectSort2(int[])}
唯一不同的是,这里的组前一个是按增量来计算的
*/
// 每一轮,都是针对某一个组的插入排序中:待排序的起点
for (int i = gap; i < arr.length; i++) {
int currentInsertValue = arr[i]; // 无序列表中的第一个元素
int insertIndex = i - gap; // 有序列表中的最后一个元素
while (insertIndex >= 0
&& currentInsertValue < arr[insertIndex]) {
// 比较的数比前一个数小,则前一个往后移动
arr[insertIndex + gap] = arr[insertIndex];
insertIndex -= gap;
}
// 对找到的位置插入值
arr[insertIndex + gap] = currentInsertValue;
}
System.out.println("增量为 " + gap + " 的这一轮排序后:" + Arrays.toString(arr));
}
}
测试输出信息
原始数组:[8, 9, 1, 7, 2, 3, 5, 4, 6, 0]
增量为 5 的这一轮排序后:[3, 5, 1, 6, 0, 8, 9, 4, 7, 2]
增量为 2 的这一轮排序后:[0, 2, 1, 4, 3, 5, 7, 6, 9, 8]
增量为 1 的这一轮排序后:[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
移动法-大数据量耗时测试
/**
* 移动法,大数据量测试速度
*/
@Test
public void moveBulkDataSort() {
int max = 80_000;
// int max = 8;
int[] arr = new int[max];
for (int i = 0; i < max; i++) {
arr[i] = (int) (Math.random() * 80_000);
}
Instant startTime = Instant.now();
moveShellSort(arr);
// System.out.println(Arrays.toString(arr));
Instant endTime = Instant.now();
System.out.println("共耗时:" + Duration.between(startTime, endTime).toMillis() + " 毫秒");
}
多次测试输出信息
共耗时:32 毫秒
共耗时:23 毫秒
共耗时:43 毫秒
共耗时:25 毫秒
可以看到,只需要几十毫秒了
算法分析
希尔排序是基于插入排序的一种算法, 在此算法基础之上增加了一个新的特性,提高了效率。希尔排序的时间的时间复杂度为O(
),希尔排序时间复杂度的下界是n*log2n。希尔排序没有快速排序算法快 O(n(logn)),因此中等大小规模表现良好,对规模非常大的数据排序不是最优选择。但是比O(
)复杂度的算法快得多。并且希尔排序非常容易实现,算法代码短而简单。 此外,希尔算法在最坏的情况下和平均情况下执行效率相差不是很多,与此同时快速排序在最坏的情况下执行的效率会非常差。专家们提倡,几乎任何排序工作在开始时都可以用希尔排序,若在实际使用中证明它不够快,再改成快速排序这样更高级的排序算法. 本质上讲,希尔排序算法是直接插入排序算法的一种改进,减少了其复制的次数,速度要快很多。 原因是,当n值很大时数据项每一趟排序需要移动的个数很少,但数据项的距离很长。当n值减小时每一趟需要移动的数据增多,此时已经接近于它们排序后的最终位置。 正是这两种情况的结合才使希尔排序效率比插入排序高很多。Shell算法的性能与所选取的分组长度序列有很大关系。只对特定的待排序记录序列,可以准确地估算关键词的比较次数和对象移动次数。想要弄清关键词比较次数和记录移动次数与增量选择之间的关系,并给出完整的数学分析,今仍然是数学难题。


以上就是java 排序算法之希尔算法的详细内容,更多关于java 希尔算法的资料请关注靠谱客其它相关文章!
最后
以上就是甜蜜宝马最近收集整理的关于java 排序算法之希尔算法的全部内容,更多相关java内容请搜索靠谱客的其他文章。








发表评论 取消回复