本篇文章给大家带来了关于java的相关知识,其中主要整理了JVM的相关问题,包括了JVM内存区域划分、JVM类加载机制、VM的垃圾回收等等内容,下面一起来看一下,希望对大家有帮助。

推荐学习:《java视频教程》
一.JVM内存区域划分
JVM为什么要划分出这些区域呢?JVM内存是从操作系统里面申请过来的,而JVM就根据功能需求将这些划分成了一些小的模块,这样一块大的场地就可以划分成一些小的模块,然后每个模块就负责自己的功能就可以了,那接下来看看这些区域的功能到底是什么呢!
1.程序计数器
程序计数器是内存中最小的区域,这里面主要保存了下一条要执行的指令的地址在哪里(指令就是字节码,一般程序要运行,JVM就需要把字节码加载出来放到内存中,然后程序再把一条一条的指令从内存中取出来放到CPU上去执行,所以必须要记住当前执行到哪一条指令,以及下一条在哪里,因为CPU不是只给一个进程提供服务的,是给所有的进程都提供服务,是并发式的执行程序的,又因为操作系统是以线程为单位进行调度执行的,所以每个线程都要有自己的执行位置,也就是每一个线程都需要有一个程序计数器来记录位置!)
2.栈
栈里面存放的主要是局部变量和方法调用信息,只要涉及到新方法的调用,就会有"入栈"的操作,每执行完成一个方法,就会有"出栈"的操作,而且栈也是每个线程都有一份的
因此对于递归来说,一定要控制好递归条件,否则很有可能会出现栈溢出(StackOverflowException)异常的!
3.堆
堆是内存中空间最大的区域,而且堆是每个进程只有一份的,进程中的多个线程公用一个堆,里面主要存放着new出来的对象以及对象的成员变量,例如String s = new String()如果在方法里面这里的s就是局部变量是在栈上的,如果这个s是成员变量,就是在堆上的,而后面new String()是对象的本体,对象是在堆上的,这是容易混淆的地方,另外堆还有一个重要的点就是关于垃圾回收问题,这个后面再详细介绍!
4.方法区
方法区中存放的是"类对象",平常所写的.java代码经过编译器翻译过后就会变成.class(二进制字节码),然后.class就会被加载到内存中,也就被JVM构造成了类对象(加载的过程就是称为"类加载"),而这些类对象就会存放到方法区中,这里面就具体描述了类长啥样(类的名字,类的成员及其成员名成员类型,类的方法及其方法名方法类型,以及一些指令…另外类对象里面还存放了一个很重要的东西,就是静态成员,一般被static修饰的成员就成为了类属性,而普通的方法被称为实例属性,这是有很大差别的)!
二.JVM类加载机制
类加载其实是设计一个运行时环境的一个重要的功核心功能,这是非常重量级的,因此我这里也就简单介绍一下!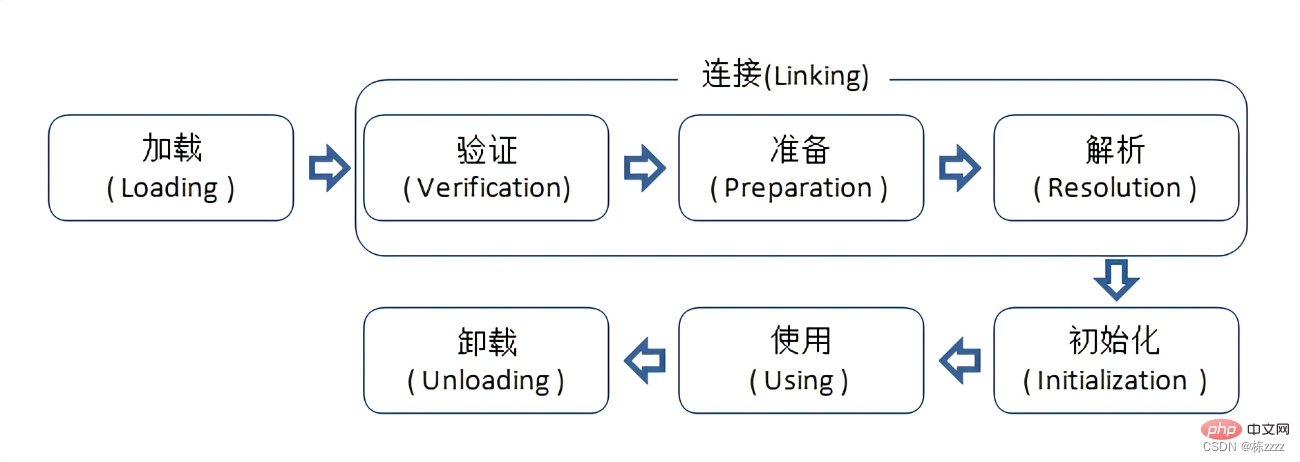
上述就是类加载的具体过程,最后面的Using和Unloading就是使用的过程就不介绍了,就介绍一下前面的三个大的步骤:
1.Loading(加载)
在loading阶段就会先找到对应的.class文件,然后打开并读取(根据字节流).class文件,同时初步生成一个类对象,这个和完成的类加载(class Loading)是不相同的,不要弄混淆了!
class文件的具体格式(如果要实现一个Java编译器就得按照这样的格式来构造,实现JVM就得按照这个格式来进行加载!):
观察这个格式就可以看到.class文件就把.java文件中的核心信息都表述进去了,只不过组织格式上发生了转变,所以loading环节就会把读取到的信息,初步填写到类对象中
2.Linking(连接)
连接一般就是建立好多个实体之间的联系
2.1.Verification(验证)
Verification就是一个校验的过程,主要就是验证读到的内容是不是和规范中规定的格式完全匹配,如果发现读到的数据格式不符合规范,就会类加载失败,并且抛出异常!
2.2.Preparation(准备)
Preparation阶段是正式为定义的变量(静态变量,就是static修饰的变量)分配内存并设置类变量初始值的阶段,就会给每个静态变量分配内存,并且设置为0值!
2.3.Resolution(解析)
Resolution阶段是Java虚拟机将常量池内的符号引用替换为直接引用的过程,也就是初始化常量的过程,.class文件中常量是集中放置的,每个常量会有一个编号,而在.class文件中的结构体里初始情况就只是记录的编号,然后就可以根据这个编号找到对应的内容,再填充到类对象中!
3.Initialization(初始化)
Initialization阶段就是真正的对类对象进行初始化(根据写的代码),尤其是针对静态成员
4.典型的面试题
class A {
public A(){
System.out.println("A的构造方法");
}
{
System.out.println("A的构造代码块");
}
static {
System.out.println("A的静态代码块");
}}class B extends A{
public B(){
System.out.println("B的构造方法");
}
{
System.out.println("B的构造代码块");
}
static {
System.out.println("B的静态代码块");
}}public class Test extends B{
public static void main(String[] args) {
new Test();
new Test();
}}登录后复制可以自己先尝试写一下输出的结果
做这样的题就需要把握几个大的原则:
类加载阶段就会进行静态代码块的执行,要想创建实例,势必要先进行类加载
静态代码块只是类加载阶段执行一次,其他阶段都不会再执行
构造方法和构造代码块每次实例化都会执行,而且构造代码块会在构造方法前面执行~~
父类执行在前,子类执行在后!
程序是从main开始执行的,main的Test的方法,因此要执行main就需要先加载Test类
只有涉及到这个类了,类里面的东西才会被加载
输出结果:
A的静态代码块
B的静态代码块
A的构造代码块
A的构造方法
B的构造代码块
B的构造方法
A的构造代码块
A的构造方法
B的构造代码块
B的构造方法
登录后复制5.双亲委派模型
这个东西是类加载中的一个环节,处于Loading阶段(比较靠前的部分),双亲委派模型描述的就是JVM中的类加载器,如何根据类的全限定名(java.lang.String)找到.class文件的过程。这里的类加载器是JVM专门提供的对象,主要负责进行类加载,所以找文件的过程也是由类加载器来负责的,.class文件可能放置的位置有很多,有的要放到JDK目录里面,有的放到项目目录里面,还有的在其他特定的位置里面,因此JVM提供了多个类加载器,每个类加载器负责一个片区,而默认的类加载器主要有3个:
BootStrapClassLoader:负责加载标准库中的类(String,ArrayList,Random,Scanner…)
ExtensionClassLoader:负责加载JDK扩展的类(现在很少用到)
ApplicationClassLoader:负责加载当前项目目录中的类
另外程序员还可以自定义类加载器,来加载其他目录中的类,Tomcat就自定义了类加载器,用来专门加载webapps里面的.class
双亲委派模型就描述了这个找目录的过程,也就是上述类加载器是如何配合的
考虑找一下java.lang.String:
程序启动,就会先进入ApplicationClassLoader类加载器
ApplicationClassLoader类加载器就会检查下,它的父加载器是否已经加载过了,如果没有,就调用父 类加载器ExtensionClassLoader
ExtensionClassLoader类加载器就会检查下,它的父加载器是否已经加载过了,如果没有,就调用父 类加载器BootStrapClassLoader
BootStrapClassLoader类加载器也会检查下,它的父加载器是否已经加载过了,然后发现没有父亲,于是就扫描自己负责的目录
然后java.lang.String这个类就在标准库中能找到,然后后续就由BootStrapClassLoader加载器负责后续的加载过程,查找环节就结束了!

考虑找一下自己写的Test类:
程序启动,就会先进入ApplicationClassLoader类加载器
ApplicationClassLoader类加载器就会检查下,它的父加载器是否已经加载过了,如果没有,就调用父 类加载器ExtensionClassLoader
ExtensionClassLoader类加载器就会检查下,它的父加载器是否已经加载过了,如果没有,就调用父 类加载器BootStrapClassLoader
BootStrapClassLoader类加载器也会检查下,它的父加载器是否已经加载过了,然后发现没有父亲,于是就扫描自己负责的目录,没扫描到,就会回到子加载器中继续扫描
ExtensionClassLoader扫描自己负责的目录,也没有扫描到,再回到子加载器中继续扫描
ApplicationClassLoader也扫描自己负责的目录,自己写的类就在自己的项目目录下,因此就能找到,然后后续的类加载就由ApplicationClassLoad完成,此时查找目录的环节就结束了~~(另外如果ApplicationClassLoader也没有找到们就会抛出ClassNotFoundException异常)

这一套查找规则就称为双亲委派模型,那为啥JVM要这样设计呢,理由就是一旦程序员自己写的类和全限定类名重复了,也能够成功加载标准库中的类,而不是自己写的类!!!
另外如果是自定义的类加载器,要不要遵守这个双亲委派模型呢?
答案是可以遵守也可以不遵守,主要看需求,例如Tomcat加载webapp中的类,就没有遵守,因为遵守了上面的类加载器也是不可能找到的!
三.JVM的垃圾回收
JVM中的垃圾回收机制(GC),一般在写代码的时候,经常就会涉及到申请内存,例如创建一个变量,new一个对象,调用一个方法,加载类…而申请内存的时机一般是明确的(需要保存某个或某些数据就需要申请内存),但是释放内存的时机,却是不那么清楚的,释放的早了也不行(如果还是要使用的,结果已经被释放了这就让其无内存可用了,就让这些数据"无处可去"),释放的晚了也不行(释放晚了,大量的囤积很有可能让可用内存逐渐变少,很有可能会出现内存泄漏问题,就是无内存可以使用),因此内存的释放要恰到好处才好!
而垃圾回收的本职是靠运行时环境额外做了很多的工作来完成释放内存操作的,这让程序员的心智负担大大降低了,但是垃圾回收也是有劣势的:①消耗额外的开销(消耗资源耕更多了);②可能会影响程序的流畅运行(垃圾回收会经常引入STW问题(Stop The World))
下面就具体来看一下是怎么回收的:
1.找垃圾/判定垃圾
而当下有两个主流的方案:
1.1.基于引用计数
这不是Java中采取的方案,这是Python及其他语言的方案,因此这里就简单介绍一下,就不过多介绍了~
而引用计数的具体思路就是针对每个对象,都会额外引入一小块内存,来保存这个对象有多少个引用指向它
而这样的引用计数存在两个缺陷:
- 空间利用率比较低!!!,每个new的对象都需要搭配一个计数器,假设一个计数器4个字节,如果对象本身比较大(几百个字节),那么这个计数器就无所谓,而一旦这个对象本身就比较小(4个字节),那么再多出来4个字节,就相当于空间利用率就浪费了一倍,因此空间利用率会比较低~
- 有循环引用的问题
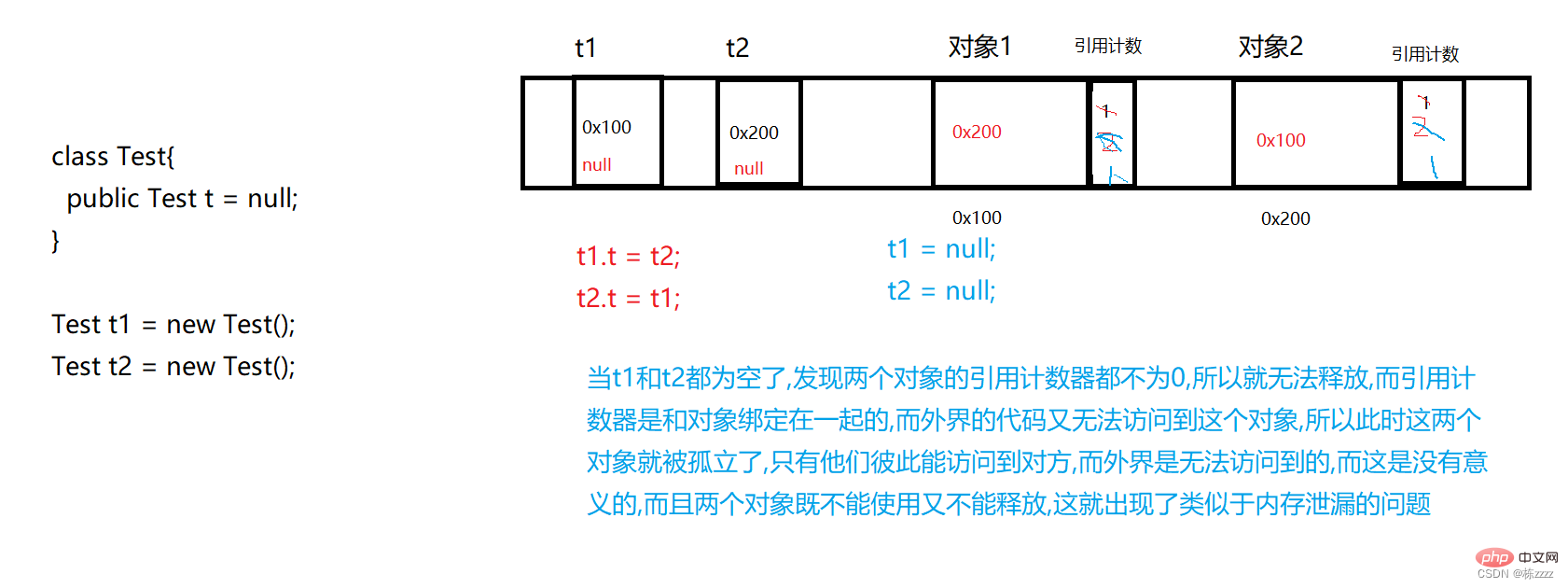
因此使用引用计数也是会有大量的问题出现的,而想Python,PHP之类的语言也不是只使用引用计数器就完成GC的,也是配合了一些其他的机制来完成的!
1.2.基于可达性分析
可达性分析是Java所采取的方案,可达性分析是通过一些额外的线程,定期针对整个内存空间的对象进行扫描,有一些起始位置(GCRoots),然后就类似于深度优先遍历一样(可以想象成是一棵树),把可以访问到的对象都标记一边(带有标记的对象就是可达的对象),而没有被标记的对象,就是不可达的对象,也就是垃圾,应该被释放掉!
这里的GCRoots(从这些位置开始遍历):
- 栈上的局部变量;
- 常量池中的引用指向的对象;
- 方法区中的静态成员指向的对象;
因此可达性分析的优点就是解决了引用计数的缺点:空间利用率低,循环引用;而可达性分析的缺点也很明显:系统开销大,遍历一次可能比较慢~
因此找垃圾也是很简单的,核心就是确认这个对象未来是否还会使用,看还有没有引用指向它,应不应该释放掉!
2.释放垃圾
既然已经明确了什么是垃圾,接下来就要回收垃圾了,而回收垃圾有三种基本策略,下面来看一下!
2.1.标记-请除

这里的标记就是可达性分析的过程,而清除就是释放内存,假设上面是一块内存,而打钩的区域代表是垃圾,此时如果直接释放掉,虽然内存是还给系统了,但是释放掉的内存是离散的,不是连续的,而这样带来的问题就是"内存碎片",空闲的内存可能会有很多,假设加起来一共是1G,而此时想要申请500MB的空间,按理是可以申请到的,但在这里是有可能申请失败的(因为要申请的500MB是连续的内存,每次申请的内存都是连续的内存空间,而这里的1G可能是多个碎片加起来的),因此这样的问题其实是非常影响程序运行的
2.2.复制算法
由于上面的标记-清除策略可能会带来内存碎片的问题,因此引入了复制算法来解决这一问题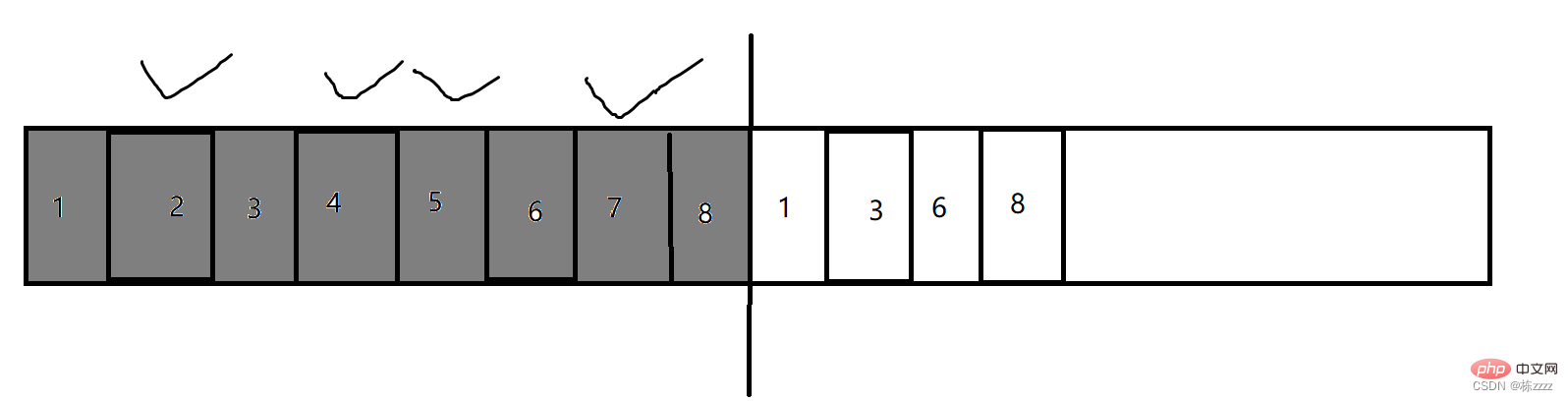
上面是一块内存,复制算法的策略就是内存使用一半,丢一半,不全部使用,在使用的一般里面把不是垃圾的拷贝到另一半(这个拷贝是JVM内部处理好的,不用纠结),然后把前面使用的全部内存都释放掉,这样内存碎片的问题就迎刃而解了!
所以复制算法就有两个很大的问题:
- 内存空间利用率低(只使用了一般的内存);
- 如果要保留的对象多,要释放的对象少,那么复制的开销就很大;
2.3.标记-整理
这又是针对复制算法,再进一步做出改进!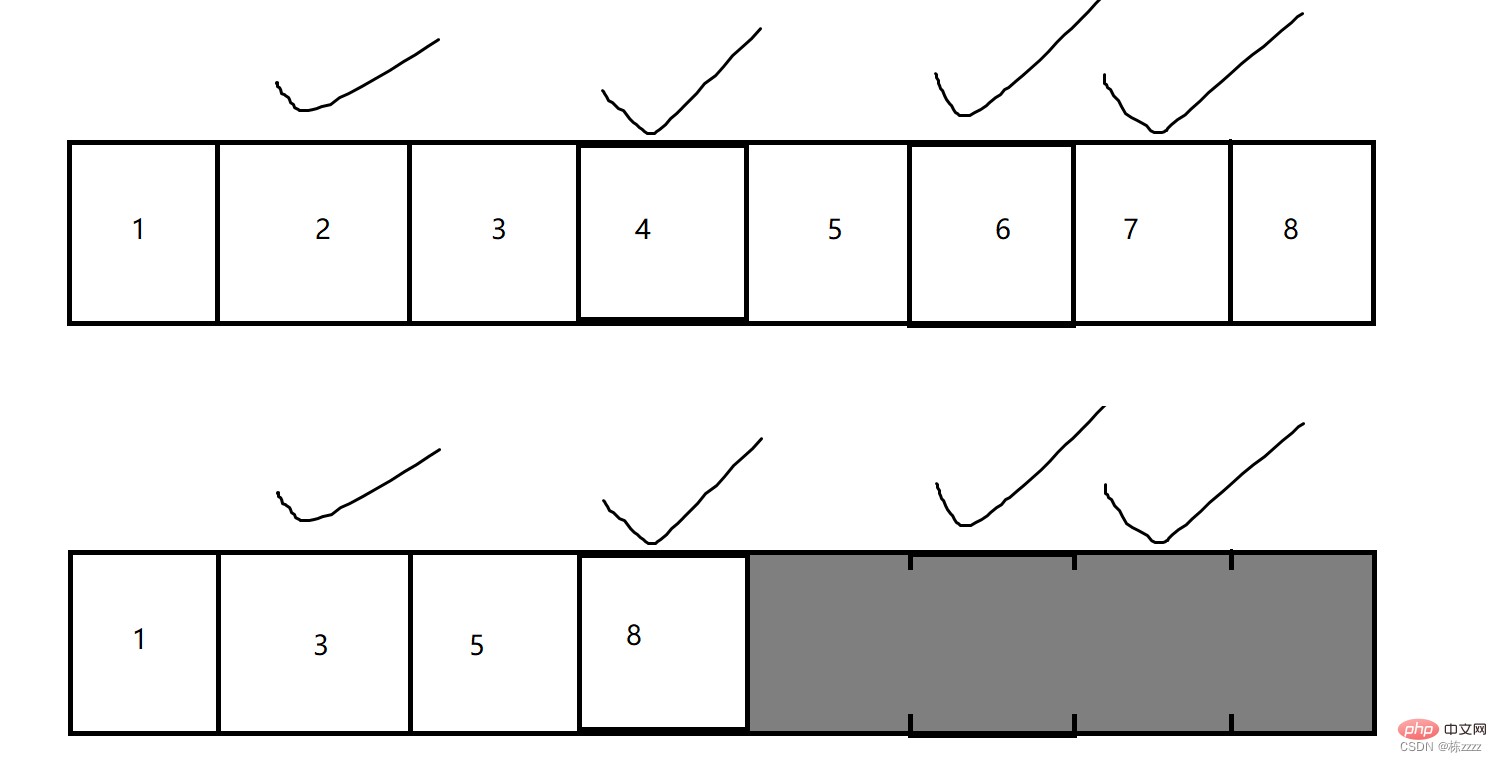
标记整理的策略就是将不是垃圾的内存整理到一起,然后释放掉后面的全部内存,就类似于顺序表删除中间元素的操作一样,有一个搬运的过程!
这个方案空间利用率是高了,但是仍然没有办法解决复制/搬运元素开销大的问题!
上述的三种方案,虽然能够解决问题,但是都有各自的缺陷,因此实际上JVM中的实现,会把多种方案结合起来使用,也就是"分代回收"!!!
2.4分代回收
这里的分代就是针对对象来进行分类(根据对象的"年龄"进行分类,而这里的年龄表示一个对象熬过一轮GC的扫描,就称"长了一岁"),而针对不同年龄的对象,就采取不同的方案!!!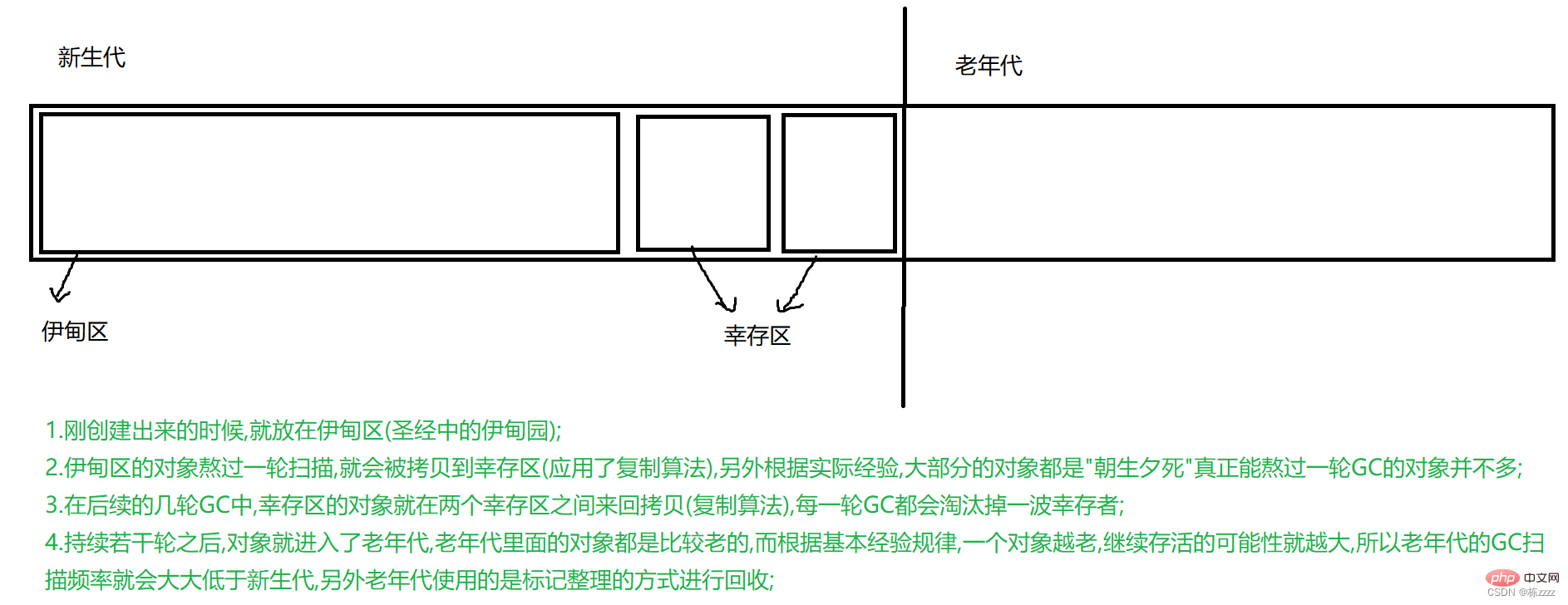
这就是整个分代回收的过程!
3.垃圾回收器
上面的找垃圾和释放垃圾都只是算法的思想,并不是真正的落地实现的过程,而真正实现上述算法模块的是"垃圾回收器",下面来介绍一些具体的垃圾回收器:
3.1.Serial收集器和Serial Old收集器
Serial收集器是给新生代提供的垃圾回收器,Serial Old收集器是给老年代提供的垃圾回收器,这两个收集器是串行收集的,而且在进行垃圾的扫描和释放的时候,业务线程要停止工作,所以这样的方式扫描的满,释放的也慢,而且也能产生严重的STW!
3.2.ParNew收集器,Parallel Scavenge收集器和Parallel Old收集器
ParNew收集器,Parallel Scavenge收集器都是提供给新生代的,Parallel Scavenge收集器比起ParNew收集器加了一些参数,可以控制STW的时间,就是多了一些更强的功能,Parallel Old收集器是提供给老年代的,这三个收集器都是并行收集的,就是引入了多线程的方式来解决扫描垃圾和释放垃圾的功能!
上面的这几个回收器都是历史遗留下来的,也就是比较老的垃圾回收方式,另外再介绍两个更新的垃圾回收器!
3.3.CMS收集器
CMS收集器设计的比较巧妙,其设计的初衷是尽可能让STW时间短,Java8使用的正是CMS收集器,下面简单介绍一下CMS收集器的过程:
- 初始标记:速度很快,会引起短暂的STW(只是找到GCRoots);
- 并发标记:速度很快,但是可以和业务线程并发执行,不会产生STW;
- 重新标记:在2业务代码可能会影响并发标记的结果(业务线程在执行,就有可能产生新的垃圾),因此这一步就是针对2的结果进行微调,虽然会引起STW,但只是微调,速度很快;
上面三步都是基于可达性分析! - 回收内存:也是和业务线程并发执行,不会产生STW,这是基于标记整理;
3.4.G1收集器
G1收集器是唯一一款全区域的垃圾回收器,从Java11开始使用的就是G1收集器,这个收集器是把整个内存,分成了很多小的区域Region,给这些Region进行了不同的标记,有的Region放新生代对象,有的Region放老年代对象,然后扫描的时候,就一次扫描若干个Region(不追求一轮GC就扫描完,需要分多次扫描),这样对于业务代码的影响也是最小的,
这两个新的收集器的核心思想就是化整为零,G1当下可以优化到让STW停顿时间小于1ms,这是完全可以接收的!上面就是关于JVM的一些学习了,这里的收集器主要还是了解为主,主要还是上面的垃圾回收思想很重要!!!
推荐学习:《java视频教程》
以上就是Java知识归纳之JVM详解的详细内容,更多请关注靠谱客其它相关文章!

最后
以上就是安详夕阳最近收集整理的关于Java知识归纳之JVM详解的全部内容,更多相关Java知识归纳之JVM详解内容请搜索靠谱客的其他文章。








发表评论 取消回复