1.背景简介
当我们在并发场景下,增加某个integer值的时,就涉及到多线程安全的问题,解决思路两个
- 将值增加的方法使用同步代码块同步
- 使用AtomicInteger,来逐步增加其值
这两种实现方式代码如下
import java.util.concurrent.atomic.AtomicInteger;
public class CASTest {
private static AtomicInteger countAI = new AtomicInteger(0);
private static int count = 0;
private static final int THREAD_COUNT = 8;
public static void main(String[] args) throws InterruptedException {
long start = System.currentTimeMillis();
Thread[] threads = new Thread[THREAD_COUNT];
for(int i = 0; i < THREAD_COUNT; i++) {
threads[i] = new Thread(){
@Override
public void run() {
for(int i = 0; i < 10000000; i++) {
// 测试1:使用同步代码块方法,耗时:2927ms
synAdd();
// 测试2:使用atomicInterger方式, 耗时:1860ms
// atomicAdd();
}
}
};
}
for(int i = 0; i < THREAD_COUNT; i++) {
threads[i].start();
}
for(int i = 0; i < THREAD_COUNT; i++) {
threads[i].join();
}
System.out.println("finish...耗时:" + (System.currentTimeMillis()-start) + "ms");
}
private static synchronized void synAdd() {
count++;
}
private static void atomicAdd() {
countAI.getAndAdd(1);
}
}
从测试结果可以看出,使用atomicAdd方法耗时: 1860ms, 使用synAdd方法耗时: 2927ms
为何使用AtomicInteger效率更高?以及AtomicInteger是如何实现的?本文将对cas进行进一步探索
2. java源码追踪
根据断点追踪countAI.getAndAdd(1);, 对栈如下
getAndAddInt:1034, Unsafe (sun.misc) getAndAdd:177, AtomicInteger (java.util.concurrent.atomic) atomicAdd:45, CASTest (com.youai.cas) access$000:5, CASTest (com.youai.cas) run:21, CASTest$1 (com.youai.cas)
进入到了关键核心方法 sun.misc.Unsafe#getAndAddInt
public final int getAndAddInt(Object o, long offset, int delta) {
int v;
do {
v = getIntVolatile(o, offset);
} while (!compareAndSwapInt(o, offset, v, v + delta));
return v;
}
在这个方法中,循环调用了sun.misc.Unsafe#compareAndSwapInt这个方法,这个方法的效果就是,判断对象o中,地址偏移量是offset这个地址内存中的int值是否和期望值v相等,如果相等,则用v + delta替换,并返回替换成功;否则不替换,并返回替换失败。需要循环的原因是因为getIntVolatile(o, offset);和compareAndSwapInt(o, offset, v, v + delta)这两步并不是原子原作,在执行前面一句后,目标地址中的值可能被其他线程给修改,所以如果失败需要重新获取目标地址中的最新值。
可以看到,在整个代码过程中,并没有强制加锁,减少线程切换阻塞等无效时间的消耗,而是采用了失败重试的机制,这也是乐观锁的一种实现。因为它的效率高。
cas能够实现,需要compareAndSwapInt这个操作等价于一个原子操作,那compareAndSwapInt是如何实现的呢?下次解答。
3. hotspot jvm源码追踪
/**
* Atomically update Java variable to <tt>x</tt> if it is currently
* holding <tt>expected</tt>.
* @return <tt>true</tt> if successful
*/
public final native boolean compareAndSwapInt(Object o, long offset,
int expected,
int x);
可以看到compareAndSwapInt这个方法被native修饰,具体实现在需要参考c/c++代码:
从openjdk源码追踪到compareAndSwapInt的实现在hotspot/src/share/vm/prims/unsafe.cpp这文件中, 具体对应方法如下:
UNSAFE_ENTRY(jboolean, Unsafe_CompareAndSwapInt(JNIEnv *env, jobject unsafe, jobject obj, jlong offset, jint e, jint x))
UnsafeWrapper("Unsafe_CompareAndSwapInt");
oop p = JNIHandles::resolve(obj);
jint* addr = (jint *) index_oop_from_field_offset_long(p, offset);
return (jint)(Atomic::cmpxchg(x, addr, e)) == e; //此处调用了Atomic::cmpxchg方法
UNSAFE_END
Unsafe_CompareAndSwapInt方法进一步调用了Atomic::cmpxchg方法,由于Atomic::cmpxchg方法和平台有关,我们此时关注linux下的实现,hotspot/src/os_cpu/linux_x86/vm/atomic_linux_x86.inline.hpp,具体方法如下:
inline jint Atomic::cmpxchg (jint exchange_value, volatile jint* dest, jint compare_value) {
int mp = os::is_MP();
__asm__ volatile (LOCK_IF_MP(%4) "cmpxchgl %1,(%3)"
: "=a" (exchange_value)
: "r" (exchange_value), "a" (compare_value), "r" (dest), "r" (mp)
: "cc", "memory");
return exchange_value;
}
此方法是一个c++内联汇编的方法,我们着重关注cmpxchgl这个汇编指令:
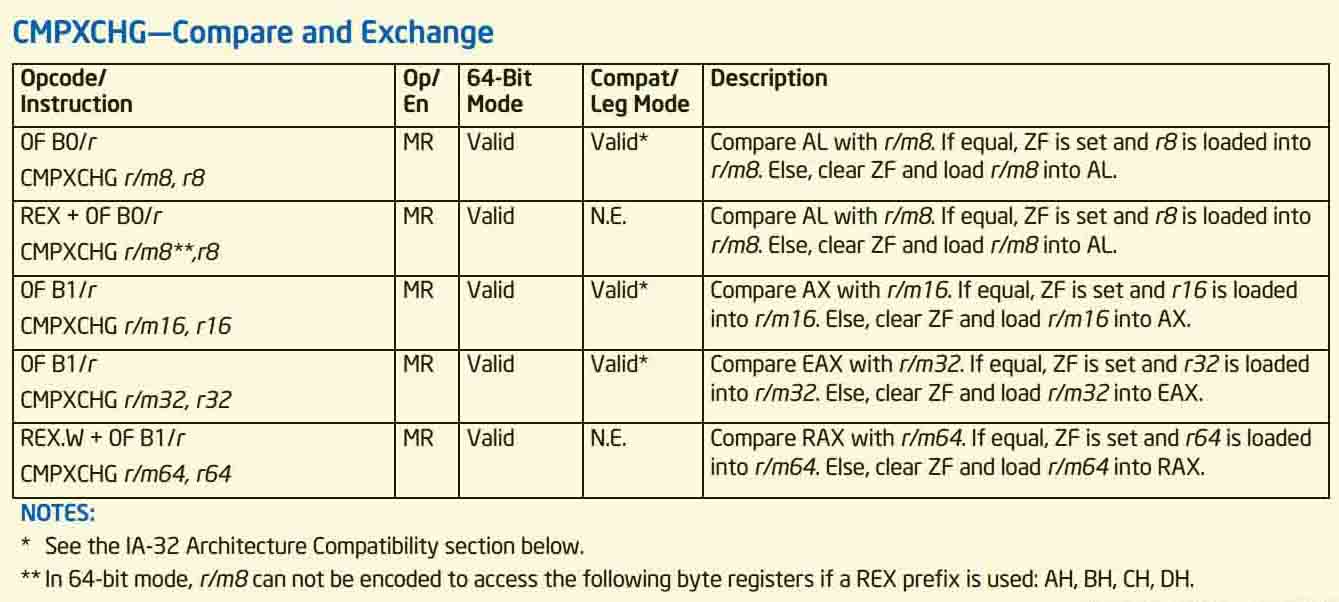
This instruction can be used with a LOCK prefix to allow the instruction to be executed atomically. To simplify the interface to the processor's bus, the destination operand receives a write cycle without regard to the result of the comparison. The destination operand is written back if the comparison fails; otherwise, the source operand is written into the destination. (The processor never produces a locked read without also producing a locked write.)
intel汇编指令的官方文档来看, cmpxchgl的作用是,比较ax寄存器中的值和期望值,如果相等,则将target值设置到目标对象上,否则不设置。特别得,在cmpxchgl指令前加上lock可以使得cmpxchgl操作成为一个原子操作。这也论证了sun.misc.Unsafe#compareAndSwapInt确是等价于一个原子操作
4. 手写一个cas实现
1. 通过汇编手写一个cas方法
看了intel的文档,cas原理并不复杂,可以通过汇编手写一个cas方法xchange:
.file "cmpandset.c" .text .globl xchange .type xchange, @function xchange: .LFB0: .cfi_startproc .cfi_def_cfa_offset 16 .cfi_offset 6, -16 .cfi_def_cfa_register 6 mov %esi, %eax lock cmpxchgl %edx, (%rdi) sete %al movzbl %al, %eax .L3: .cfi_def_cfa 7, 8 ret .cfi_endproc .LFE0: .size xchange, .-xchange .ident "GCC: (Ubuntu 7.5.0-3ubuntu1~18.04) 7.5.0" .section .note.GNU-stack,"",@progbits
2. 多线程条件下测试自行实现的cas方法
测试代码:
#include <stdio.h>
#include <pthread.h>
#include <sys/time.h>
#define THREAD_CNT 8
extern int xchange(int *ptr, int expect, int dest);
int a = 0;
void cmp_add(int* cnt, int adder);
long current_ms() {
struct timeval cur_time;
gettimeofday(&cur_time, NULL);
return cur_time.tv_sec * 1000 + cur_time.tv_usec / 1000;
}
void * sum(void *arg) {
for(int i = 0; i < 10000000; i++) {
cmp_add(&a, 1);
}
}
int main(int argc, char const *argv[])
{
long start = current_ms();
int result = xchange(&a, 13, 13);
printf("result=%dn", result);
pthread_t tids[THREAD_CNT];
for(int i = 0; i < THREAD_CNT; i++) {
pthread_create(&tids[i], NULL, sum, NULL);
}
// 等待
for(int i = 0; i < THREAD_CNT; i++) {
pthread_join(tids[i], NULL);
}
printf("result=%d, 耗时:%ldmsn", a, (current_ms() - start));
return 0;
}
void cmp_add(int* cnt, int adder) {
int tmp = 0;
do {
tmp = *cnt;
} while(xchange(cnt, tmp, tmp+adder) == 0);
}
输出结果为:
result=80000000, 耗时:8596ms
可见自行实现的cas方法在多线程场景下,同样是线程安全的。
3. cas与互斥锁方式的对比
测试代码:
#include <stdio.h>
#include <pthread.h>
#include <sys/time.h>
#include <semaphore.h>
#define THREAD_CNT 8
int a = 0;
sem_t add_mutex;
long current_ms() {
struct timeval cur_time;
gettimeofday(&cur_time, NULL);
return cur_time.tv_sec * 1000 + cur_time.tv_usec / 1000;
}
void * sum(void *arg) {
for(int i = 0; i < 10000000; i++) {
sem_wait(&add_mutex);
a++;
sem_post(&add_mutex);
}
}
int main(int argc, char const *argv[])
{
long start = current_ms();
sem_init(&add_mutex, 0, 1);
pthread_t tids[THREAD_CNT];
for(int i = 0; i < THREAD_CNT; i++) {
pthread_create(&tids[i], NULL, sum, NULL);
}
// 等待
for(int i = 0; i < THREAD_CNT; i++) {
pthread_join(tids[i], NULL);
}
printf("result=%d, 耗时:%ldmsn", a, (current_ms() - start));
sem_destroy(&add_mutex);
return 0;
}
输出结果:
result=80000000, 耗时:19353ms
4. 结论
在c中,cas耗时8596ms, 互斥锁耗时19353ms, cas的执行效率显著高于互斥锁
5. 思考
各语言各版本,执行时间如下,单位ms:
| 实现方式 | java | c |
|---|---|---|
| cas | 1860 | 8596 |
| 锁 | 2927 | 19353 |
- cas的方式效率比锁高
- 开启了jit后的java代码为何效率比c更高?留待后续对jit的研究吧
以上为个人经验,希望能给大家一个参考,也希望大家多多支持靠谱客。
最后
以上就是懵懂哑铃最近收集整理的关于基于java中cas实现的探索的全部内容,更多相关基于java中cas实现内容请搜索靠谱客的其他文章。








发表评论 取消回复