前言:
提示:我们不应该为了优化而优化,这有时会增加代码的复杂度。
这篇文章中的代码都在以下环境中进行性能测试。
- JMH version: 1.33(Java 基准测试框架)
- VM version: JDK 17, OpenJDK 64-Bit Server VM, 17+35-2724
通过这篇文章的测试,将发现以下几个操作的性能差异。
- 预先分配
HashMap的大小,提高 1/4 的性能。 - 优化
HashMap的key,性能相差 9.5 倍。 - 不使用
Enum.values()遍历,Spring也曾如此优化。 - 使用 Enum 代替
String常量,性能高出 1.5 倍。 - 使用高版本 JDK,基础操作有 2-5 倍性能差异。
1.预先分配 HashMap 的大小
HashMap 是 Java 中最为常用的集合之一,大多数的操作速度都非常快,但是 HashMap 在调整自身的容量大小时是很慢且难以自动优化,因此我们在定义一个 HashMap 之前,应该尽可能的给出它的容量大小。给出 size 值时要考虑负载因子,HashMap 默认负载因子是 0.75,也就是要设置的 size 值要除于 0.75。
相关文章:HashMap 源码分析解读
下面使用 JMH 进行基准测试,测试分别向初始容量为 16 和 32 的 HashMap 中插入 14 个元素的效率。
/**
* @author https://www.wdbyte.com
*/
@State(Scope.Benchmark)
@Warmup(iterations = 3,time = 3)
@Measurement(iterations = 5,time = 3)
public class HashMapSize {
@Param({"14"})
int keys;
@Param({"16", "32"})
int size;
@Benchmark
public HashMap<Integer, Integer> getHashMap() {
HashMap<Integer, Integer> map = new HashMap<>(size);
for (int i = 0; i < keys; i++) {
map.put(i, i);
}
return map;
}
}
HashMap 的初始容量是 16,负责因子 0.75,即最多插入 12 个元素,再插入时就要进行扩容,所以插入 14 个元素过程中需要扩容一次,但是如果 HashMap 初始化时就给了 32 容量,那么最多可以承载 32 * 0.75 = 24 个元素,所以插入 14 个元素时是不需要扩容操作的。
# JMH version: 1.33 # VM version: JDK 17, OpenJDK 64-Bit Server VM, 17+35-2724 Benchmark (keys) (size) Mode Cnt Score Error Units HashMapSize.getHashMap 14 16 thrpt 25 4825825.152 ± 323910.557 ops/s HashMapSize.getHashMap 14 32 thrpt 25 6556184.664 ± 711657.679 ops/s
可以看到在这次测试中,初始容量为32 的 HashMap 比初始容量为 16 的 HashMap 每秒可以多操作 26% 次,已经有 1/4 的性能差异了。
2.优化 HashMap 的 key
如果 HashMap 的 key 值需要用到多个 String 字符串时,把字符串作为某个类属性,然后使用这个类的实例作为 key 会比使用字符串拼接效率更高。
下面测试使用两个字符串拼接作为 key,和把两个字符串作为 MutablePair 类的属性引用,然后使用 MutablePair 对象作为 key 的运行效率差异。
/**
* @author https://www.wdbyte.com
*/
@State(Scope.Benchmark)
@Warmup(iterations = 3, time = 3)
@Measurement(iterations = 5, time = 3)
public class HashMapKey {
private int size = 1024;
private Map<String, Object> stringMap;
private Map<Pair, Object> pairMap;
private String[] prefixes;
private String[] suffixes;
@Setup(Level.Trial)
public void setup() {
prefixes = new String[size];
suffixes = new String[size];
stringMap = new HashMap<>();
pairMap = new HashMap<>();
for (int i = 0; i < size; ++i) {
prefixes[i] = UUID.randomUUID().toString();
suffixes[i] = UUID.randomUUID().toString();
stringMap.put(prefixes[i] + ";" + suffixes[i], i);
// use new String to avoid reference equality speeding up the equals calls
pairMap.put(new MutablePair(prefixes[i], suffixes[i]), i);
}
}
@Benchmark
@OperationsPerInvocation(1024)
public void stringKey(Blackhole bh) {
for (int i = 0; i < prefixes.length; i++) {
bh.consume(stringMap.get(prefixes[i] + ";" + suffixes[i]));
}
}
@Benchmark
@OperationsPerInvocation(1024)
public void pairMap(Blackhole bh) {
for (int i = 0; i < prefixes.length; i++) {
bh.consume(pairMap.get(new MutablePair(prefixes[i], suffixes[i])));
}
}
}
测试结果:
# JMH version: 1.33 # VM version: JDK 17, OpenJDK 64-Bit Server VM, 17+35-2724 Benchmark Mode Cnt Score Error Units HashMapKey.pairMap thrpt 25 89295035.436 ± 6498403.173 ops/s HashMapKey.stringKey thrpt 25 9410641.728 ± 389850.653 ops/s
可以发现使用对象引用作为 key 的性能,是使用 String 拼接作为 key 的性能的 9.5 倍。
3.不使用 Enum.values() 遍历
我们通常会使用 Enum.values() 进行枚举类遍历,但是这样每次调用都会分配枚举类值数量大小的数组用于操作,这里完全可以缓存起来,以减少每次内存分配的时间和空间消耗。
/**
* 枚举类遍历测试
*
* @author https://www.wdbyte.com
*/
@State(Scope.Benchmark)
@Warmup(iterations = 3, time = 3)
@Measurement(iterations = 5, time = 3)
@BenchmarkMode(Mode.AverageTime)
@OutputTimeUnit(TimeUnit.MILLISECONDS)
public class EnumIteration {
enum FourteenEnum {
a,b,c,d,e,f,g,h,i,j,k,l,m,n;
static final FourteenEnum[] VALUES;
static {
VALUES = values();
}
}
@Benchmark
public void valuesEnum(Blackhole bh) {
for (FourteenEnum value : FourteenEnum.values()) {
bh.consume(value.ordinal());
}
}
@Benchmark
public void enumSetEnum(Blackhole bh) {
for (FourteenEnum value : EnumSet.allOf(FourteenEnum.class)) {
bh.consume(value.ordinal());
}
}
@Benchmark
public void cacheEnums(Blackhole bh) {
for (FourteenEnum value : FourteenEnum.VALUES) {
bh.consume(value.ordinal());
}
}
}
运行结果:
# JMH version: 1.33 # VM version: JDK 17, OpenJDK 64-Bit Server VM, 17+35-2724 Benchmark Mode Cnt Score Error Units EnumIteration.cacheEnums thrpt 25 15623401.567 ± 2274962.772 ops/s EnumIteration.enumSetEnum thrpt 25 8597188.662 ± 610632.249 ops/s EnumIteration.valuesEnum thrpt 25 14713941.570 ± 728955.826 ops/s
很明显使用缓存后的遍历速度是最快的,使用 EnumSet 遍历效率是最低的,这很好理解,数组的遍历效率是大于哈希表的。
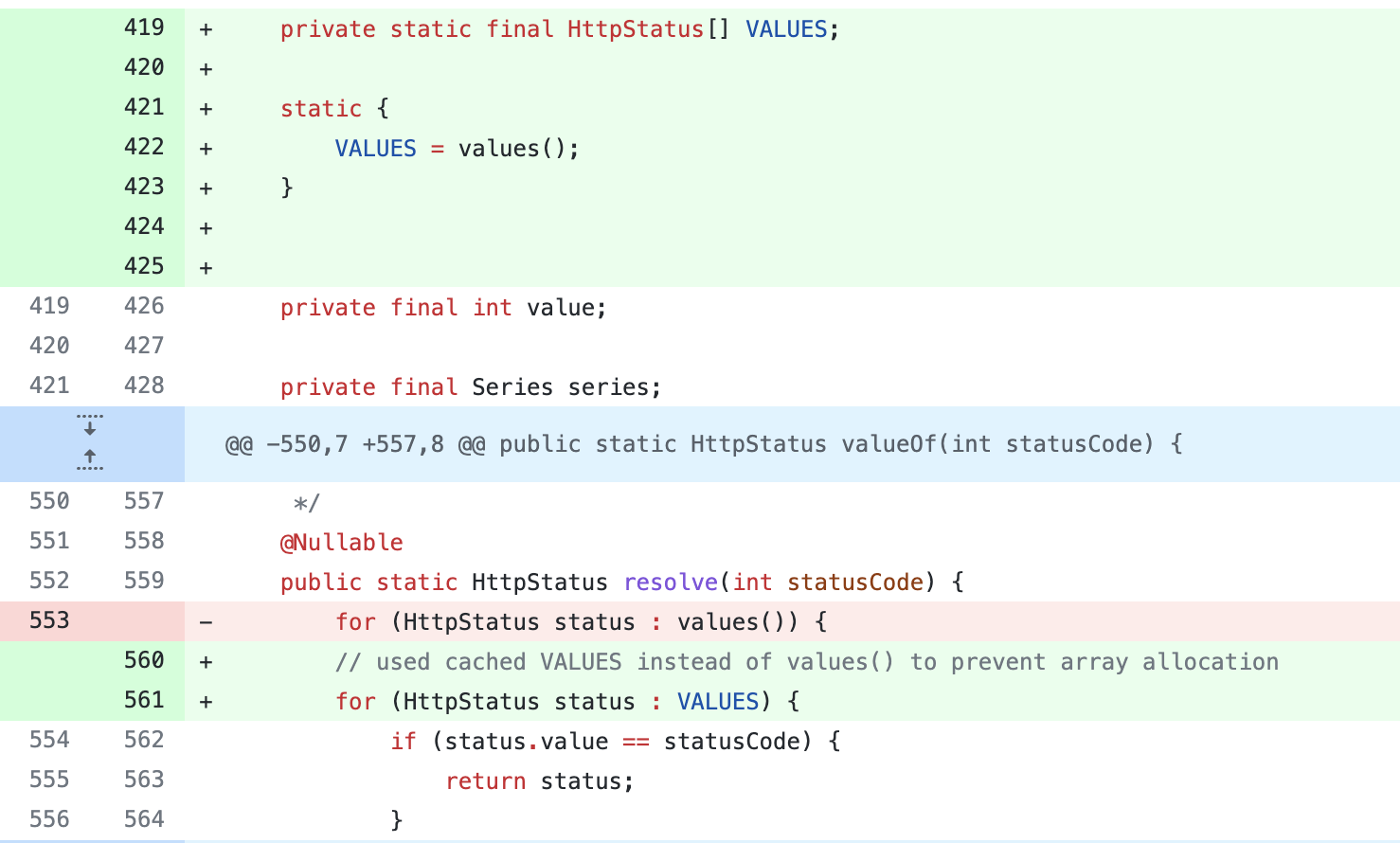
可能你会觉得这里使用 values() 缓存和直接使用 Enum.values() 的效率差异很小,其实在某些调用频率很高的场景下是有很大区别的,在 Spring 框架中,曾使用 Enum.values() 这种方式在每次响应时遍历 HTTP 状态码枚举类,这在请求量大时造成了不必要的性能开销,后来进行了 values() 缓存优化。
下面是这次提交的截图:
4.使用 Enum 代替 String 常量
使用 Enum 枚举类代替 String 常量有明显的好处,枚举类强制验证,不会出错,同时使用枚举类的效率也更高。即使作为 Map 的 key 值来看,虽然 HashMap 的速度已经很快了,但是使用 EnumMap 的速度可以更快。
提示:不要为了优化而优化,这会增加代码的复杂度。
下面测试使用使用 Enum 作为 key,和使用 String 作为 key,在 map.get 操作下的性能差异。
/**
* @author https://www.wdbyte.com
*/
@State(Scope.Benchmark)
@Warmup(iterations = 3, time = 3)
@Measurement(iterations = 5, time = 3)
public class EnumMapBenchmark {
enum AnEnum {
a, b, c, d, e, f, g,
h, i, j, k, l, m, n,
o, p, q, r, s, t,
u, v, w, x, y, z;
}
/** 要查找的 key 的数量 */
private static int size = 10000;
/** 随机数种子 */
private static int seed = 99;
@State(Scope.Benchmark)
public static class EnumMapState {
private EnumMap<AnEnum, String> map;
private AnEnum[] values;
@Setup(Level.Trial)
public void setup() {
map = new EnumMap<>(AnEnum.class);
values = new AnEnum[size];
AnEnum[] enumValues = AnEnum.values();
SplittableRandom random = new SplittableRandom(seed);
for (int i = 0; i < size; i++) {
int nextInt = random.nextInt(0, Integer.MAX_VALUE);
values[i] = enumValues[nextInt % enumValues.length];
}
for (AnEnum value : enumValues) {
map.put(value, UUID.randomUUID().toString());
}
}
}
@State(Scope.Benchmark)
public static class HashMapState{
private HashMap<String, String> map;
private String[] values;
@Setup(Level.Trial)
public void setup() {
map = new HashMap<>();
values = new String[size];
AnEnum[] enumValues = AnEnum.values();
int pos = 0;
SplittableRandom random = new SplittableRandom(seed);
for (int i = 0; i < size; i++) {
int nextInt = random.nextInt(0, Integer.MAX_VALUE);
values[i] = enumValues[nextInt % enumValues.length].toString();
}
for (AnEnum value : enumValues) {
map.put(value.toString(), UUID.randomUUID().toString());
}
}
}
@Benchmark
public void enumMap(EnumMapState state, Blackhole bh) {
for (AnEnum value : state.values) {
bh.consume(state.map.get(value));
}
}
@Benchmark
public void hashMap(HashMapState state, Blackhole bh) {
for (String value : state.values) {
bh.consume(state.map.get(value));
}
}
}
运行结果:
# JMH version: 1.33
# VM version: JDK 17, OpenJDK 64-Bit Server VM, 17+35-2724Benchmark Mode Cnt Score Error Units
EnumMapBenchmark.enumMap thrpt 25 22159.232 ± 1268.800 ops/s
EnumMapBenchmark.hashMap thrpt 25 14528.555 ± 1323.610 ops/s
很明显,使用 Enum 作为 key 的性能比使用 String 作为 key 的性能高出 1.5 倍。但是仍然要根据实际情况考虑是否使用 EnumMap 和 EnumSet。
5.使用高版本 JDK
String 类应该是 Java 中使用频率最高的类了,但是 Java 8 中的 String 实现相比高版本 JDK ,则占用空间更多,性能更低。
下面测试 String 转 bytes 和 bytes 转 String 在 Java 8 以及 Java 11 中的性能开销。
/**
* @author https://www.wdbyte.com
* @date 2021/12/23
*/
@State(Scope.Benchmark)
@Warmup(iterations = 3, time = 3)
@Measurement(iterations = 5, time = 3)
public class StringInJdk {
@Param({"10000"})
private int size;
private String[] stringArray;
private List<byte[]> byteList;
@Setup(Level.Trial)
public void setup() {
byteList = new ArrayList<>(size);
stringArray = new String[size];
for (int i = 0; i < size; i++) {
String uuid = UUID.randomUUID().toString();
stringArray[i] = uuid;
byteList.add(uuid.getBytes(StandardCharsets.UTF_8));
}
}
@Benchmark
public void byteToString(Blackhole bh) {
for (byte[] bytes : byteList) {
bh.consume(new String(bytes, StandardCharsets.UTF_8));
}
}
@Benchmark
public void stringToByte(Blackhole bh) {
for (String s : stringArray) {
bh.consume(s.getBytes(StandardCharsets.UTF_8));
}
}
}
测试结果:
# JMH version: 1.33
# VM version: JDK 1.8.0_151, Java HotSpot(TM) 64-Bit Server VM, 25.151-b12Benchmark (size) Mode Cnt Score Error Units
StringInJdk.byteToString 10000 thrpt 25 2396.713 ± 133.500 ops/s
StringInJdk.stringToByte 10000 thrpt 25 1745.060 ± 16.945 ops/s# JMH version: 1.33
# VM version: JDK 17, OpenJDK 64-Bit Server VM, 17+35-2724Benchmark (size) Mode Cnt Score Error Units
StringInJdk.byteToString 10000 thrpt 25 5711.954 ± 41.865 ops/s
StringInJdk.stringToByte 10000 thrpt 25 8595.895 ± 704.004 ops/s
可以看到在 bytes 转 String 操作上,Java 17 的性能是 Java 8 的 2.5 倍左右,而 String 转 bytes 操作,Java 17 的性能是 Java 8 的 5 倍。关于字符串的操作非常基础,随处可见,可见高版本的优势十分明显。
到此这篇关于Java 中的5个代码性能提升技巧的文章就介绍到这了,更多相关Java 代码性能提升技巧内容请搜索靠谱客以前的文章或继续浏览下面的相关文章希望大家以后多多支持靠谱客!
参考:
https://richardstartin.github.io/posts/5-java-mundane-performance-tricks
https://github.com/spring-projects/spring-framework/issues/26842
https://github.com/spring-projects/spring-framework/commit/7f1062159ee9926d5abed7cadc2b36b6b7fc242e
最后
以上就是敏感宝贝最近收集整理的关于Java 中的5个代码性能提升技巧的全部内容,更多相关Java 中内容请搜索靠谱客的其他文章。








发表评论 取消回复