Spring Data JPA
Spring Data是Spring提供的操作数据的框架,Spring Data JPA是Spring Data的一个模块,通过Spring data 基于jpa标准操作数据的模块。
Spring Data的核心能力,就是基于JPA操作数据,并且可以简化操作持久层的代码。
它使用一个叫作Repository的接口类为基础,它被定义为访问底层数据模型的超级接口。而对于某种具体的数据访问操作,则在其子接口中定义。
Spring Data可以让我们只定义接口,只要遵循spring data的规范,就无需写实现类,不用写sql语句直接查询数据。
Repository
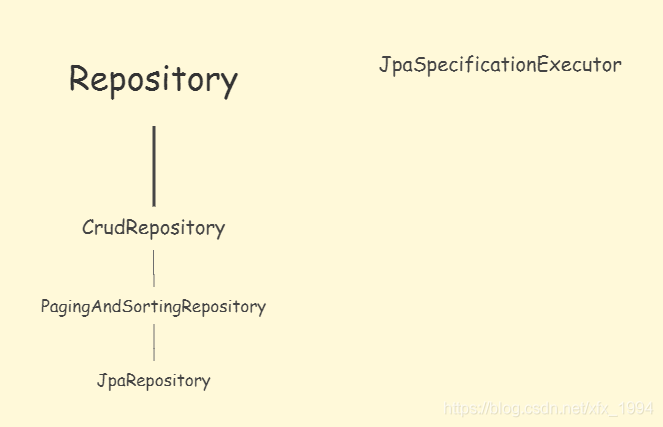
Repository
提供了findBy + 属性 方法
CrudRepository
继承了Repository 提供了对数据的增删改查
PagingAndSortRepository
继承了CrudRepository 提供了对数据的分页和排序,缺点是只能对所有的数据进行分页或者排序,不能做条件判断
JpaRepository: 继承了PagingAndSortRepository
开发中经常使用的接口,主要继承了PagingAndSortRepository,对返回值类型做了适配
JpaSpecificationExecutor
提供多条件查询
CrudRepository
CrudRepository继承Repository,添加了一组对数据的增删改查的方法

PagingAndSortingRepository
PagingAndSortingRepository继承CrudRepository,添加了一组分页排序相关的方法

JpaRepository
JpaRepository继承PagingAndSortingRepository,添加了一组JPA规范相关的方法。对继承父接口中方法的返回值进行了适配,因为在父类接口中通常都返回迭代器,需要我们自己进行强制类型转化。而在JpaRepository中,直接返回了List。
开发中最常用JpaRepository
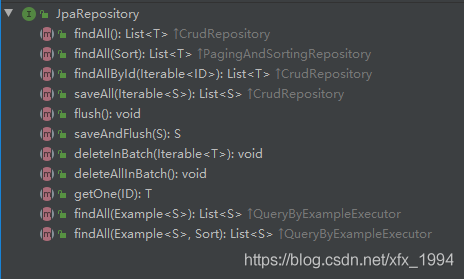
JpaSpecificationExecutor
这个接口比较特殊,单独存在,没有继承以上接口。主要提供了多条件查询的支持,并且可以在查询中添加分页和排序。因为这个接口单独存在,因此需要配合以上说的接口使用。

JpaRepository查询功能
Jpa方法命名规则
JpaRepository支持接口规范方法名查询。意思是如果在接口中定义的查询方法符合它的命名规则,就可以不用写实现,目前支持的关键字如下。
| Keyword | Sample | JPQL snippet |
|---|---|---|
| And | findByNameAndPwd | where name= ? and pwd =? |
| Or | findByNameOrSex | where name= ? or sex=? |
| Is,Equals | findById,findByIdEquals | where id= ? |
| Between | findByIdBetween | where id between ? and ? |
| LessThan | findByIdLessThan | where id < ? |
| LessThanEquals | findByIdLessThanEquals | where id <= ? |
| GreaterThan | findByIdGreaterThan | where id > ? |
| GreaterThanEquals | findByIdGreaterThanEquals | where id > = ? |
| After | findByIdAfter | where id > ? |
| Before | findByIdBefore | where id < ? |
| IsNull | findByNameIsNull | where name is null |
| isNotNull,NotNull | findByNameNotNull | where name is not null |
| Like | findByNameLike | where name like ? |
| NotLike | findByNameNotLike | where name not like ? |
| StartingWith | findByNameStartingWith | where name like ‘?%' |
| EndingWith | findByNameEndingWith | where name like ‘%?' |
| Containing | findByNameContaining | where name like ‘%?%' |
| OrderBy | findByIdOrderByXDesc | where id=? order by x desc |
| Not | findByNameNot | where name <> ? |
| In | findByIdIn(Collection<?> c) | where id in (?) |
| NotIn | findByIdNotIn(Collection<?> c) | where id not in (?) |
| True | findByAaaTue | where aaa = true |
| False | findByAaaFalse | where aaa = false |
| IgnoreCase | findByNameIgnoreCase | where UPPER(name)=UPPER(?) |
| top | findTop10 | top 10/where ROWNUM <=10 |
使用方法
使用时自定义接口继承JpaRepository,传入泛型,第一个参数为要操作的实体类,第二个参数为该实体类的主键类型
public interface SpuRepository extends JpaRepository<Spu, Long> {
Spu findOneById(Long id);
Page<Spu> findByCategoryIdOrderByCreateTimeDesc(Long cid, Pageable pageable);
Page<Spu> findByRootCategoryIdOrderByCreateTime(Long cid, Pageable pageable);
}
解析过程
1. Spring Data JPA框架在进行方法名解析时
会先把方法名多余的前缀截取掉,比如find,findBy,read,readBy,get,getBy,然后对剩下的部分进行解析。
2. 假设创建如下查询findByCategoryId()
框架在解析该方法时,首先剔除findBy,然后对剩下的属性进行解析,假设查询实体为Spu
(1) 先判断categoryId(根据POJO 规范,首字母变为小写)是否为查询实体的一个属性,如果是,则表示根据该属性进行查询;如果没有该属性,继续第二步;
(2) 从右往左截取第一个大写字母开头的字符串此处为Id),然后检查剩下的字符串是否为查询实体的一个属性,如果是,则表示根据该属性进行查询;
如果没有该属性,则重复第二步,继续从右往左截取;最后假设user为查询实体的一个属性;
(3) 接着处理剩下部分(CategoryId),先判断用户所对应的类型是否有categoryId属性,如果有,则表示该方法最终是根据"Spu.categoryId"的取值进行查询;
否则继续按照步骤2的规则从右往左截取。
(4) 可能会存在一种特殊情况,比如Spu包含一个categoryId 的属性,也有一个 rootCategoryId属性,此时会存在混淆。可以明确在属性之间加上"_" 以显式表达意图,比如 "findByRoot_CategoryId()"
3. 特殊参数
可以直接在方法的参数上加入分页或排序的参数,比如:
Page<Spu> findByCategoryId(Long cid, Pageable pageable); List<Spu> findByCategoryId(Long cid, Sort sort);
4. JPA的@NamedQueries
(1) 在实体类上使用@NamedQuery
@NamedQuery(name = "Spu.findByRootCategoryId",query = "select s from Spu s where s.rootCategoryId >= ?1")
(2) 在自己实现的DAO的Repository接口里面定义一个同名的方法,示例如下:
public List<Spu> findByRootCategoryId(Long rootCategoryId);
(3) 然后Spring会先找是否有同名的NamedQuery,如果有,那么就不会按照接口定义的方法来解析。
5. 使用@Query
在方法上标注@Query来指定本地查询
参数nativeQuery默认为false,nativeQuery=false时,value参数写的是JPQL,JPQL是用来操作model对象的
@Query(value="select s from Spu s where s.title like %?1" ) public List<Spu> findByTitle(String title);
nativeQuery=true时,value参数写的是原生sql
@Query(value="select * from spu s where s.title like %?1",nativeQuery=true ) public List<Spu> findByTitle(String title);
6. 使用@Param命名化参数
@Query(value = "select s from Spu s where s.title in (:titles)")
List<Spu> findByTitle(@Param("titles") List<String> titles);
JPA自定义Repository方法
如果不使用SpringData的方法,想要自己实现,该怎么办呢?
定义一个接口:声明要添加的, 并自实现的方法
提供该接口的实现类:类名需在要声明的 Repository 后添加 Impl, 并实现方法
声明 Repository 接口, 并继承 1) 声明的接口
注意:默认情况下, Spring Data 会在 base-package 中查找 "接口名Impl" 作为实现类. 也可以通过 repository-impl-postfix 声明后缀.
这张图是类与接口之间的关系

下面是具体的实现
包结构

类与接口之间的关系代码
public interface PersonRepositoiry extends JpaRepository<Person, Integer> ,PersonDao{
public interface PersonDao {
void test();
}
@Repository
public class PersonRepositoiryImpl implements PersonDao{
@PersistenceContext
private EntityManager em;
@Override
public void test() {
//只是用来测试
Person person = em.find(Person.class, 1);
System.out.println(person);
}
}
测试代码
@Test
public void testCustomerRepositoryMethod() {
personRepositoiry.test();
}
经过实践发现
XXXRepositoryImpl 与XXXRepository前面的名字必须相同,后面的也需要按照规则写
若将XXXRepositoryImpl与XXXRepository接口放在同意包下,XXXRepositoryImpl不需要添加@Repository注解,但是当XXXRepositoryImpl与XXXRepository接口不在同一包下,需要在在XXXRepositoryImpl类上加@Repository注解进行修饰
以上为个人经验,希望能给大家一个参考,也希望大家多多支持靠谱客。
最后
以上就是自然唇膏最近收集整理的关于基于JPA的Repository使用详解的全部内容,更多相关基于JPA内容请搜索靠谱客的其他文章。








发表评论 取消回复