本篇文章给大家带来了关于mysql的相关知识,其中主要介绍了关于InnoDB之MVCC原理的相关问题,MVCC即多版本并发控制,主要是为了提高数据库的并发性能,下面一起来看一下,希望对大家有帮助。

推荐学习:mysql视频教程
MVCC全称Multi-Version Concurrency Control,即多版本并发控制,主要是为了提高数据库的并发性能。同一行数据平时发生读写请求时,会上锁阻塞住。但MVCC用更好的方式去处理读—写请求,做到在发生读—写请求冲突时不用加锁。这个读是指的快照读,而不是当前读,当前读是一种加锁操作,是悲观锁。那它到底是怎么做到读—写不用加锁的,快照读和当前读是指什么?我们后面都会学到。
MySQL在REPEATABLE READ隔离级别下,是可以很大程度避免幻读问题的发生的,MySQL是怎么做到的?
版本链
我们知道,对于使用InnoDB存储引擎的表来说,它的聚簇索引记录中都包含两个必要的隐藏列(row_id并不是必要的,我们创建的表中有主键或者非NULL的UNIQUE键时都不会包含row_id列):
trx_id:每次一个事务对某条聚簇索引记录进行改动时,都会把该事务的事务id赋值给trx_id隐藏列。
roll_pointer:每次对某条聚簇索引记录进行改动时,都会把旧的版本写入到undo日志中,然后这个隐藏列就相当于一个指针,可以通过它来找到该记录修改前的信息。
为了说明这个问题,我们创建一个演示表:
CREATE TABLE `teacher` (
`number` int(11) NOT NULL,
`name` varchar(100) DEFAULT NULL,
`domain` varchar(100) DEFAULT NULL,
PRIMARY KEY (`number`)) ENGINE=InnoDB DEFAULT CHARSET=utf8
登录后复制然后向这个表里插入一条数据:
mysql> insert into teacher values(1, 'J', 'Java');Query OK, 1 row affected (0.01 sec)
登录后复制现在里的数据就是这样的:
mysql> select * from teacher;
+--------+------+--------+
| number | name | domain |
+--------+------+--------+
| 1 | J | Java |
+--------+------+--------+
1 row in set (0.00 sec)
登录后复制假设插入该记录的事务id为60,那么此刻该条记录的示意图如下所示:

假设之后两个事务id分别为80、120的事务对这条记录进行UPDATE操作,操作流程如下:
| Trx80 | Trx120 |
|---|---|
| begin | |
| begin | |
| update teacher set name=‘S’ where number=1; | |
| update teacher set name=‘T’ where number=1; | |
| commit | |
| update teacher set name=‘K’ where number=1; | |
| update teacher set name=‘F’ where number=1; | |
| commit |
每次对记录进行改动,都会记录一条undo日志,每条undo日志也都有一个roll_pointer属性(INSERT操作对应的undo日志没有该属性,因为该记录并没有更早的版本),可以将这些undo日志都连起来,串成一个链表,所以现在的情况就像下图一样:

对该记录每次更新后,都会将旧值放到一条undo日志中,就算是该记录的一个旧版本,随着更新次数的增多,所有的版本都会被roll_pointer属性连接成一个链表,我们把这个链表称之为版本链,版本链的头节点就是当前记录最新的值。另外,每个版本中还包含生成该版本时对应的事务id。于是可以利用这个记录的版本链来控制并发事务访问相同记录的行为,那么这种机制就被称之为多版本并发控制(Mulit-Version Concurrency Control MVCC)。
ReadView
对于使用READ UNCOMMITTED隔离级别的事务来说,由于可以读到未提交事务修改过的记录,所以直接读取记录的最新版本就好了。
对于使用SERIALIZABLE隔离级别的事务来说,InnoDB使用加锁的方式来访问记录。
对于使用READ COMMITTED和REPEATABLE READ隔离级别的事务来说,都必须保证读到已经提交了的事务修改过的记录,也就是说假如另一个事务已经修改了记录但是尚未提交,是不能直接读取最新版本的记录的,核心问题就是:READ COMMITTED和REPEATABLE READ隔离级别在不可重复读和幻读上的区别,这两种隔离级别关键是需要判断一下版本链中的哪个版本是当前事务可见的。
为此,InnoDB提出了一个ReadView的概念,这个ReadView中主要包含4个比较重要的内容:
m_ids:表示在生成ReadView时当前系统中活跃的读写事务的事务id列表。
min_trx_id:表示在生成ReadView时当前系统中活跃的读写事务中最小的事务id,也就是m_ids中的最小值。
max_trx_id:表示生成ReadView时系统中应该分配给下一个事务的id值。注意max_trx_id并不是m_ids中的最大值,事务id是递增分配的。比方说现在有id为1,2,3这三个事务,之后id为3的事务提交了。那么一个新的读事务在生成ReadView时,m_ids就包括1和2,min_trx_id的值就是1,max_trx_id的值就是4。
creator_trx_id:表示生成该ReadView的事务的事务id。
有了这个ReadView,这样在访问某条记录时,只需要按照下边的步骤判断记录的某个版本是否可见:
- 如果被访问版本的trx_id属性值与ReadView中的creator_trx_id值相同,意味着当前事务在访问它自己修改过的记录,所以该版本可以被当前事务访问。
- 如果被访问版本的trx_id属性值小于ReadView中的min_trx_id值,表明生成该版本的事务在当前事务生成ReadView前已经提交,所以该版本可以被当前事务访问。
- 如果被访问版本的trx_id属性值大于或等于ReadView中的max_trx_id值,表明生成该版本的事务在当前事务生成ReadView后才开启,所以该版本不可以被当前事务访问。
- 如果被访问版本的trx_id属性值在ReadView的min_trx_id和max_trx_id之间(min_trx_id <= trx_id < max_trx_id),那就需要判断一下trx_id属性值是不是在m_ids列表中,如果在,说明创建ReadView时生成该版本的事务还是活跃的,事务还没提交,该版本不可以被访问;如果不在,说明创建ReadView时生成该版本的事务已经被提交,该版本可以被访问。
- 如果某个版本的数据对当前事务不可见的话,那就顺着版本链找到下一个版本的数据,继续按照上边的步骤判断可见性,依此类推,直到版本链中的最后一个版本。如果最后一个版本也不可见的话,那么就意味着该条记录对该事务完全不可见,查询结果就不包含该记录。
在MySQL中,READ COMMITTED和REPEATABLE READ隔离级别的的一个非常大的区别就是它们生成ReadView的时机不同。
我们还是以表teacher为例,假设现在表teacher中只有一条由事务id为60的事务插入的一条记录,接下来看一下READ COMMITTED和REPEATABLE READ所谓的生成ReadView的时机不同到底不同在哪里。
READ COMMITTED每次读取数据前都生成一个ReadView
假设现在系统里有两个事务id分别为80、120的事务在执行:
# Transaction 80
set session transaction isolation level read committed;
begin
update teacher set name='S' where number=1;
update teacher set name='T' where number=1;
登录后复制此刻,表teacher中number为1的记录得到的版本链表如下所示:

假设现在有一个使用READ COMMITTED隔离级别的事务开始执行:
set session transaction isolation level read committed;
# 使用READ COMMITTED隔离级别的事务
begin;
# SELECE1:Transaction 80、120未提交
SELECT * FROM teacher WHERE number = 1; # 得到的列name的值为'J'
登录后复制这个SELECE1的执行过程如下:
在执行SELECT语句时会先生成一个ReadView,ReadView的m_ids列表的内容就是[80, 120],min_trx_id为80,max_trx_id为121,creator_trx_id为0。
然后从版本链中挑选可见的记录,最新版本的列name的内容是’T’,该版本的trx_id值为80,在m_ids列表内,根据步骤4不符合可见性要求,根据roll_pointer跳到下一个版本。
下一个版本的列name的内容是’S’,该版本的trx_id值也为80,也在m_ids列表内,根据步骤4也不符合要求,继续跳到下一个版本。
下一个版本的列name的内容是’J’,该版本的trx_id值为60,小于ReadView 中的min_trx_id值,根据步骤2判断这个版本是符合要求的。
之后,我们把事务id为80的事务提交一下,然后再到事务id为120的事务中更新一下表teacher 中number为1的记录:
set session transaction isolation level read committed;
# Transaction 120
begin
update teacher set name='K' where number=1;
update teacher set name='F' where number=1;
登录后复制此刻,表teacher 中number为1的记录的版本链就长这样:
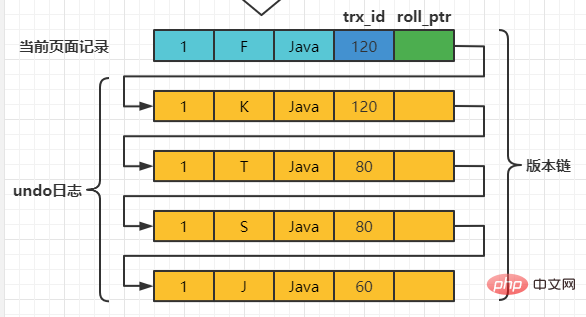
然后再到刚才使用READ COMMITTED隔离级别的事务中继续查找这个number 为1的记录,如下:
# 使用READ COMMITTED隔离级别的事务
begin;
# SELECE1:Transaction 80、120未提交
SELECT * FROM teacher WHERE number = 1; # 得到的列name的值为'J'
# SELECE2:Transaction 80提交、120未提交
SELECT * FROM teacher WHERE number = 1; # 得到的列name的值为'T'
登录后复制这个SELECE2 的执行过程如下:
- 在执行SELECT语句时会又会单独生成一个ReadView,该ReadView的m_ids列表的内容就是[120](事务id为80的那个事务已经提交了,所以再次生成快照时就没有它了),min_trx_id为120,max_trx_id为121,creator_trx_id为0。
- 然后从版本链中挑选可见的记录,从图中可以看出,最新版本的列name的内容是’F’,该版本的trx_id值为120,在m_ids列表内,根据步骤4不符合可见性要求,根据roll_pointer跳到下一个版本。
- 下一个版本的列name 的内容是’K’,该版本的trx_id值为120,也在m_ids列表内,根据步骤4不符合可见性要求,根据roll_pointer跳到下一个版本。
- 下一个版本的列name的内容是’T’,该版本的trx_id值为80,小于ReadView中的min_trx_id值120,表明生成该版本的事务在当前事务生成ReadView前已经提交,所以这个版本是符合要求的,最后返回给用户的版本就是这条列name为’‘T’'的记录。
以此类推,如果之后事务id为120的记录也提交了,再次在使用READCOMMITTED隔离级别的事务中查询表teacher中number值为1的记录时,得到的结果就是’F’了,具体流程我们就不分析了。
总结一下就是:使用READCOMMITTED隔离级别的事务在每次查询开始时都会生成一个独立的ReadView。
REPEATABLE READ —— 在第一次读取数据时生成一个ReadView
对于使用REPEATABLE READ隔离级别的事务来说,只会在第一次执行查询语句时生成一个ReadView,之后的查询就不会重复生成了。我们还是用例子看一下是什么效果。
假设现在系统里有两个事务id分别为80、120的事务在执行:
# Transaction 80
begin
update teacher set name='S' where number=1;
update teacher set name='T' where number=1;
登录后复制此刻,表teacher中number为1的记录得到的版本链表如下所示:
假设现在有一个使用REPEATABLE READ隔离级别的事务开始执行:
# 使用REPEATABLE READ隔离级别的事务
begin;
# SELECE1:Transaction 80、120未提交
SELECT * FROM teacher WHERE number = 1; # 得到的列name的值为'J'
登录后复制这个SELECE1的执行过程如下(与READ COMMITTED的过程一致):
在执行SELECT语句时会先生成一个ReadView,ReadView的m_ids列表的内容就是[80, 120],min_trx_id为80,max_trx_id为121,creator_trx_id为0。
然后从版本链中挑选可见的记录,最新版本的列name的内容是’T’,该版本的trx_id值为80,在m_ids列表内,根据步骤4不符合可见性要求,根据roll_pointer跳到下一个版本。
下一个版本的列name的内容是’S’,该版本的trx_id值也为80,也在m_ids列表内,根据步骤4也不符合要求,继续跳到下一个版本。
下一个版本的列name的内容是’J’,该版本的trx_id值为60,小于ReadView 中的min_trx_id值,根据步骤2判断这个版本是符合要求的。
之后,我们把事务id为80的事务提交一下,然后再到事务id为120的事务中更新一下表teacher 中number为1的记录:
# Transaction 80
begin
update teacher set name='K' where number=1;
update teacher set name='F' where number=1;
登录后复制此刻,表teacher 中number为1的记录的版本链就长这样:
然后再到刚才使用REPEATABLE READ隔离级别的事务中继续查找这个number为1的记录,如下:
# 使用REPEATABLE READ隔离级别的事务
begin;
# SELECE1:Transaction 80、120未提交
SELECT * FROM teacher WHERE number = 1; # 得到的列name的值为'J'
# SELECE2:Transaction 80提交、120未提交
SELECT * FROM teacher WHERE number = 1; # 得到的列name的值为'J'
登录后复制这个SELECE2的执行过程如下:
- 因为当前事务的隔离级别为REPEATABLE READ,而之前在执行SELECE1时已经生成过ReadView了,所以此时直接复用之前的ReadView,之前的ReadView的m_ids列表的内容就是[80, 120],min_trx_id为80,max_trx_id为121,creator_trx_id为0。
- 然后从版本链中挑选可见的记录,从图中可以看出,最新版本的列name的内容是’F’,该版本的trx_id值为120,在m_ids列表内,根据步骤4不符合可见性要求,根据roll_pointer跳到下一个版本。
- 下一个版本的列name的内容是’K’,该版本的trx_id值为120,也在m_ids列表内,根据步骤4不符合可见性要求,根据roll_pointer跳到下一个版本。
- 下一个版本的列name的内容是’T’,该版本的trx_id值为80,也在m_ids列表内,根据步骤4不符合可见性要求,根据roll_pointer跳到下一个版本。
- 下一个版本的列name的内容是’S’,该版本的trx_id值为80,也在m_ids列表内,根据步骤4不符合可见性要求,根据roll_pointer跳到下一个版本。
- 下一个版本的列name的内容是’J’,该版本的trx_id值为60,小于ReadView中的min_trx_id值80,表明生成该版本的事务在当前事务生成ReadView前已经提交,所以这个版本是符合要求的,最后返回给用户的版本就是这条列name为’‘J’'的记录。
也就是说两次SELECT查询得到的结果是重复的,记录的列值都是’’‘J’’’,这就是可重复读的含义。
如果我们之后再把事务id为120的记录提交了,然后再到刚才使用REPEATABLE READ隔离级别的事务中继续查找这个number为1的记录,得到的结果还是’J’,具体执行过程大家可以自己分析一下。
MVCC下的幻读现象和幻读解决
前面我们已经知道了,REPEATABLE READ隔离级别下MVCC可以解决不可重复读问题,那么幻读呢?MVCC是怎么解决的?幻读是一个事务按照某个相同条件多次读取记录时,后读取时读到了之前没有读到的记录,而这个记录来自另一个事务添加的新记录。
我们可以想想,在REPEATABLE READ隔离级别下的事务T1先根据某个搜索条件读取到多条记录,然后事务T2插入一条符合相应搜索条件的记录并提交,然后事务T1再根据相同搜索条件执行查询。结果会是什么?按照ReadView中的比较规则:
不管事务T2比事务T1是否先开启,事务T1都是看不到T2的提交的。请自行按照上面介绍的版本链、ReadView以及判断可见性的规则来分析一下。
但是,在REPEATABLE READ隔离级别下InnoDB中的MVCC可以很大程度地避免幻读现象,而不是完全禁止幻读。怎么回事呢?我们来看下面的情况:
| T1 | T2 |
|---|---|
| begin; | |
| select * from teacher where number=30; 无数据 | begin; |
| insert into teacher values(30, ‘X’, ‘Java’); | |
| commit; | |
| update teacher set domain=‘MQ’ where number=30; | |
| select * from teacher where number = 30; 有数据 |
嗯,怎么回事?事务T1很明显出现了幻读现象。在REPEATABLE READ隔离级别下,T1第一次执行普通的SELECT语句时生成了一个ReadView,之后T2向teacher表中新插入一条记录并提交。ReadView并不能阻止T1执行UPDATE或者DELETE语句来改动这个新插入的记录(由于T2已经提交,因此改动该记录并不会造成阻塞),但是这样一来,这条新记录的trx_id隐藏列的值就变成了T1的事务id。之后T1再使用普通的SELECT语句去查询这条记录时就可以看到这条记录了,也就可以把这条记录返回给客户端。因为这个特殊现象的存在,我们也可以认为MVCC并不能完全禁止幻读。
MVCC小结
从上边的描述中我们可以看出来,所谓的MVCC(Multi-Version ConcurrencyControl ,多版本并发控制)指的就是在使用READ COMMITTD、REPEATABLE READ这两种隔离级别的事务在执行普通的SELECT操作时访问记录的版本链的过程,这样子可以使不同事务的读-写、写-读操作并发执行,从而提升系统性能。
READ COMMITTD、REPEATABLE READ这两个隔离级别的一个很大不同就是:生成ReadView的时机不同,READ COMMITTD在每一次进行普通SELECT操作前都会生成一个ReadView,而REPEATABLE READ只在第一次进行普通SELECT操作前生成一个ReadView,之后的查询操作都重复使用这个ReadView就好了,从而基本上可以避免幻读现象。
我们之前说执行DELETE语句或者更新主键的UPDATE语句并不会立即把对应的记录完全从页面中删除,而是执行一个所谓的delete mark操作,相当于只是对记录打上了一个删除标志位,这主要就是为MVCC服务的。另外,所谓的MVCC只是在我们进行普通的SEELCT查询时才生效,截止到目前我们所见的所有SELECT语句都算是普通的查询,至于什么是个不普通的查询,后面就会讲到。
推荐学习:mysql视频教程
以上就是MySQL归纳总结InnoDB之MVCC原理的详细内容,更多请关注靠谱客其它相关文章!

最后
以上就是欢呼外套最近收集整理的关于MySQL归纳总结InnoDB之MVCC原理的全部内容,更多相关MySQL归纳总结InnoDB之MVCC原理内容请搜索靠谱客的其他文章。








发表评论 取消回复