怎么用Node爬取网页的数据并写入Excel文件?下面本篇文章通过一个实例来讲解一下用Node.js爬取网页的数据并生成Excel文件的方法,希望对大家有所帮助!

相信宝可梦是很多90后的童年回忆,身为程序员不止一次的也想做一款宝可梦游戏,但是做之前应该先要整理一下有多少宝可梦,他们的编号,名字,属性等信息整理出来,本期将用 Node.js 简单的实现一个从宝可梦网页数据的爬取,到把这些数据生成Excel文件,直至做接口读取Excel访问到这些数据。
爬取数据
既然是爬取数据,那我们先找一个有宝可梦图鉴数据的网页,如下图:

这个网站是用PHP写的,前后没有做分离,所以我们不会读接口来捕获数据,我们使用 crawler 库,来捕获网页中的元素从而得到数据。提前说明一下,用 crawler 库,好处是你可以用 jQuery 的方式在Node环境中捕获元素。
安装:
yarn add crawler
登录后复制实现:
const Crawler = require("crawler");
const fs = require("fs")
const { resolve } = require("path")
let crawler = new Crawler({
timeout: 10000,
jQuery: true,
});
let crawler = new Crawler({
timeout: 10000,
jQuery: true,
});
function getPokemon() {
let uri = "" // 宝可梦图鉴地址
let data = []
return new Promise((resolve, reject) => {
crawler.queue({
uri,
callback: (err, res, done) => {
if (err) reject(err);
let $ = res.$;
try {
let $tr = $(".roundy.eplist tr");
$tr.each((i, el) => {
let $td = $(el).find("td");
let _code = $td.eq(1).text().split("n")[0]
let _name = $td.eq(3).text().split("n")[0]
let _attr = $td.eq(4).text().split("n")[0]
let _other = $td.eq(5).text().split("n")[0]
_attr = _other.indexOf("属性") != -1 ? _attr : `${_attr}+${_other}`
if (_code) {
data.push([_code, _name, _attr])
}
})
done();
resolve(data)
} catch (err) {
done()
reject(err)
}
}
})
})
}登录后复制在生成实例的时候,还需要开启 jQuery 模式,然后,就可以使用 $ 符了。而以上代码的中间部分的业务就是在捕获元素爬取网页中所需要的数据,使用起来和 jQuery API 一样,这里就不再赘述了 。
getPokemon().then(async data => {
console.log(data)
})登录后复制最后我们可以执行并打印一下传过来的 data 数据,来验证确实爬取到了格式也没有错误。

写入Excel
既然刚才已经爬取到数据了,接下来,我们就将使用 node-xlsx 库,来完成把数据写入并生成一个 Excel 文件中。
首先,我们先介绍一下,node-xlsx 是一个简单的 excel 文件解析器和生成器。由 TS 构建的一个依靠 SheetJS xlsx 模块来解析/构建 excel 工作表,所以,在一些参数配置上,两者可以通用。
安装:
yarn add node-xlsx
登录后复制实现:
const xlsx = require("node-xlsx")
getPokemon().then(async data => {
let title = ["编号", "宝可梦", "属性"]
let list = [{
name: "关都",
data: [
title,
...data
]
}];
const sheetOptions = { '!cols': [{ wch: 15 }, { wch: 20 }, { wch: 20 }] };
const buffer = await xlsx.build(list, { sheetOptions })
try {
await fs.writeFileSync(resolve(__dirname, "data/pokemon.xlsx"), buffer, "utf8")
} catch (error) { }
})登录后复制其 name 则是Excel文件中的栏目名,而其中的 data 类型是数组其也要传入一个数组,构成二维数组,其表示从 ABCDE.... 列中开始排序传入文本。同时,可以通过!cols来设置列宽。第一个对象wch:10 则表示 第一列宽度为10 个字符,还有很多参数可以设置,可以参照 xlsx 库 来学习这些配置项。
最后,我们通过 xlsx.build 方法来生成 buffer 数据,最后用 fs.writeFileSync 写入或创建一个 Excel 文件中,为了方便查看,我这里存入了 名叫 data 的文件夹里,此时,我们在 data 文件夹 就会发现多出一个叫 pokemon.xlsx 的文件,打开它,数据还是那些,这样把数据写入到Excel的这步操作就完成了。
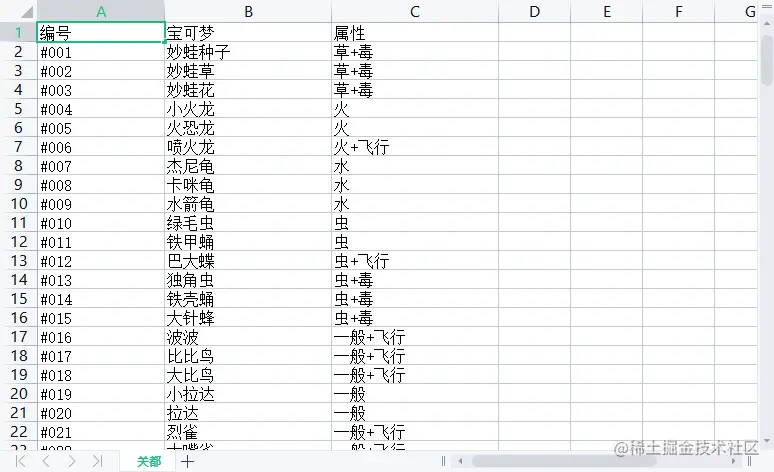
读取Excel
读取Excel其实非常容易甚至不用写 fs 的读取, 用xlsx.parse 方法传入文件地址就能直接读取到。
xlsx.parse(resolve(__dirname, "data/pokemon.xlsx"));
登录后复制当然,我们为了验证准确无误,直接写一个接口,看看能不能访问到数据。为了方便我直接用 express 框架来完成这件事。
先来安装一下:
yarn add express
登录后复制然后,再创建 express 服务,我这里端口号就用3000了,就写一个 GET 请求把读取Excel文件的数据发送出去就好。
const express = require("express")
const app = express();
const listenPort = 3000;
app.get("/pokemon",(req,res)=>{
let data = xlsx.parse(resolve(__dirname, "data/pokemon.xlsx"));
res.send(data)
})
app.listen(listenPort, () => {
console.log(`Server running at http://localhost:${listenPort}/`)
})登录后复制最后,我这里用 postman 访问接口,就可以清楚的看到,我们从爬取到存入表格所有的宝可梦数据都接收到了。

结语
如你所见,本文以宝可梦为例,来去学习怎么用Node.js爬取网页的数据,怎么把数据写入Excel文件,以及怎么读取到Excel文件的数据这三个问题,其实实现难度并不大,但有些时候蛮实用的,如果担心忘记可以收藏起来哟~

最后
以上就是感性草莓最近收集整理的关于node爬取数据实例:抓取宝可梦图鉴并生成Excel文件的全部内容,更多相关node爬取数据实例内容请搜索靠谱客的其他文章。








发表评论 取消回复