
经过多年的技术进步,推荐系统场景已经从最开始的协同过滤,发展到了现在的深度学习为核心的阶段。随着深度学习模型的体量逐渐变大后,其优化的难度也在增大,特别在推理性能上的限制下,最后模型的效果提升受到了很大的局限性,很少能产生质的飞跃。
对于这类问题,今天会和大家讨论怎么借助预训练模型的方法来跨过深水区,辅助推荐系统进一步大幅提高性能。
今天的介绍会围绕下面五点展开:
华为诺亚方舟实验室
信息流推荐场景
推荐技术的发展
预训练模型在信息流推荐的应用
展望
01
华为诺亚方舟实验室
华为诺亚方舟实验室包含计算视觉,语音语义,推荐搜索,决策推理,AI技术理论和AI系统工程六个子实验室。实验室的定位一方面是面向AI的技术研究,另一方面是面向产品的技术赋能,技术服务于产品。同时,实验室在全球建立广泛合作,目前已经涵盖到10多个国家,并与25所大学建立了联合实验室以及合作项目。
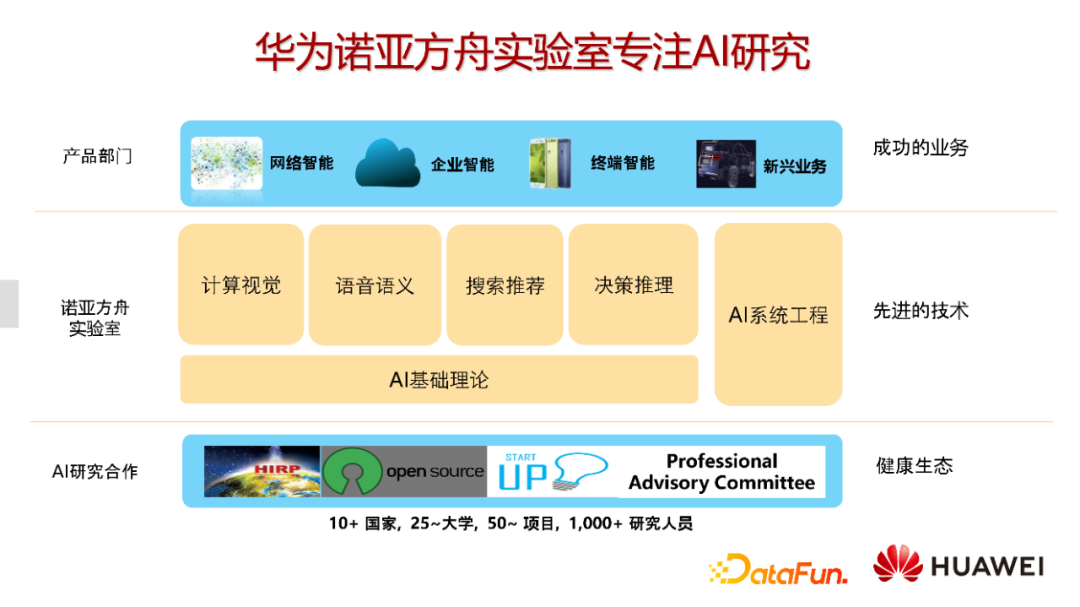
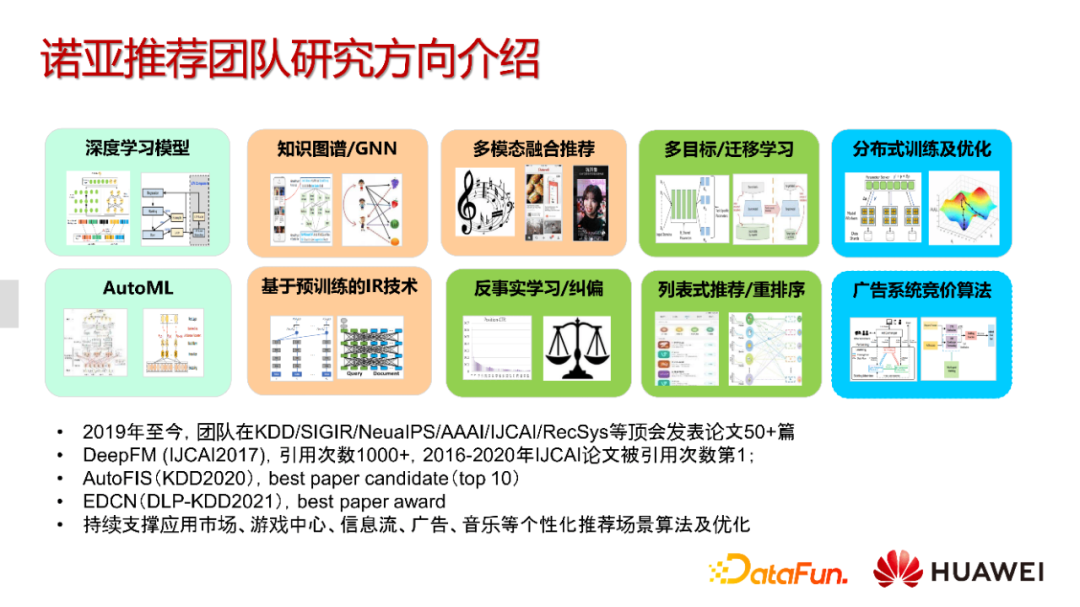
具体到推荐团队,我们有很多研究课题。在学术成果方面,我们团队已经在KDD/SIGIR等顶级会议上发表超过50篇论文,其中比较有代表性的DeepFM,已经有超过1000的引用量。在此基础上,我们持续对华为多个实际的应用业务进行技术支持,包括应用市场、游戏中心、信息流、广告、音乐等场景。
02
信息流推荐场景
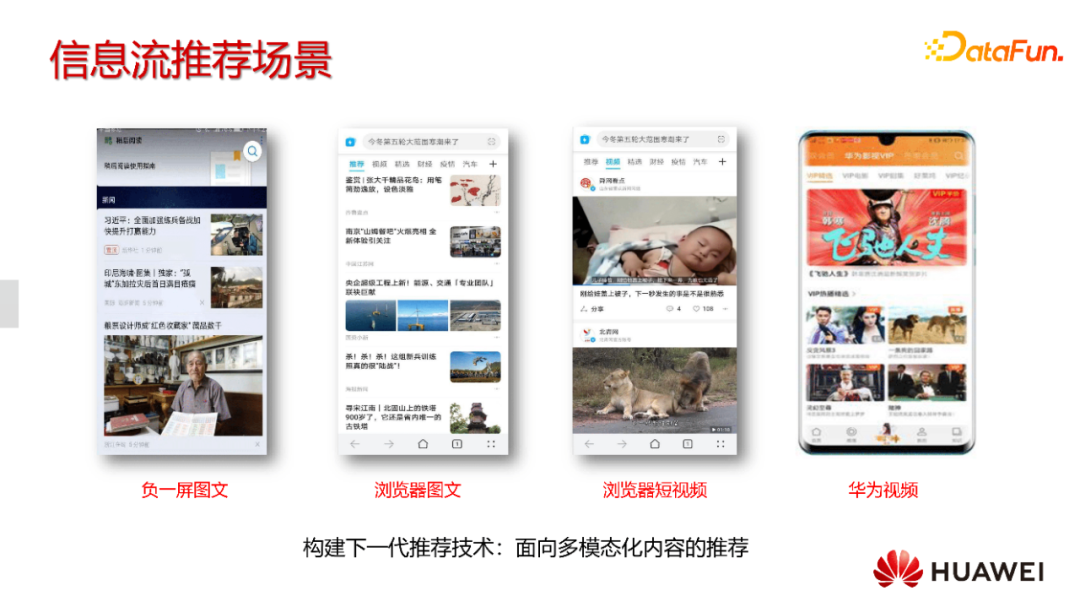
华为的多模态信息流推荐主要包含以下几个场景:华为手机的负一屏图文新闻推荐,华为浏览器的图文和短视频瀑布流,华为视频APP里面的电影/电视剧推荐。大家可以看到,相对于传统的推荐,现在的应用场景越来越向多模态、多元化的技术路线发展。如何构建一个面向多模态的推荐,是当下的一个难点,也是一个转折点。
03
推荐技术的发展
首先回顾一下推荐技术的发展。在2000年左右,我们使用最多的技术是协同过滤。迄今为止,矩阵分解或者基于物品的协同过滤,依然是业界广泛使用的算法之一,因为不仅简单,而且效果往往很显著。
从2010年开始,随着广义线性模型的提出,很多模型,比如采用了FTRL算法和线性更新的逻辑回归,因子分解或者FM等被提出以及应用。这类方法比传统的协同过滤模型,在性能和效果上有所提升。在排序领域,像BPR,RankSVM等算法也获得了很好的效果。这里面效果的提升主要来源于大规模的训练数据以及很高效的训练迭代机制,比如实时更新。
从2015年开始,深度学习模型受到更多的关注。比如google提出的YoutubeDNN从发表开始就受到了业界各方面的关注,也得到了广泛的应用。还有后来的Wide&Deep架构也受到了很大关注。我们在此基础上提出了DeepFM。与此同时,这个阶段也有阿里的DIN等代表性工作出来。
深度学习模型的成功主要取决于GPU算力的飞跃,进而为各个推荐系统的业务场景带来了效果的提升。但是随着模型体量的增大,我们发现优化的难度也在提升,比如为了保证线上推理性能的要求,上线的模型很难带来质的提升。我们一直在思考什么是推荐技术的下一个突破性方向。从18年的BERT模型提出开始,在NLP领域已经建立了预训练+微调的新范式。同时,在CV领域,也已经开始大规模的进行大规模预训练模型的研究。我们希望借鉴相同的经验,通过预训练模型来辅助推荐系统进行进一步的性能提升。

04
预训练模型在信息流推荐中的应用
在本次分享中,希望从信息流推荐场景出发,介绍两部分技术,一部分是新闻场景下的预训练和排序建模,另一部分就是用户视角下的新闻界面表征建模。
从图中可以看出,给定一条新闻内容,现有技术已经能够从文本等相关内容里挖掘出包括类别标签,关键词和实体词等。我们往往并不关心这些具体类别或者标签的含义是什么,而是直接当成一种ID进行向量嵌入加到模型中。这并没有帮助模型去进行语义理解,比如图中标签Tag里面的“养生”,我们并没有建模文本语义。
另一方面,如果只是从文本模态去挖掘的话,很难捕捉到完整的用户行为。当看到新闻界面的时候,用户的第一感觉是什么?这就促使我们去思考如何从用户视角下去捕捉新闻界面的多模态信息,包括图片是否清晰,排版的类型,配大图还是三张小图这些都会对用户的直观感觉产生影响。

1. 新闻场景下的BERT预训练和排序建模
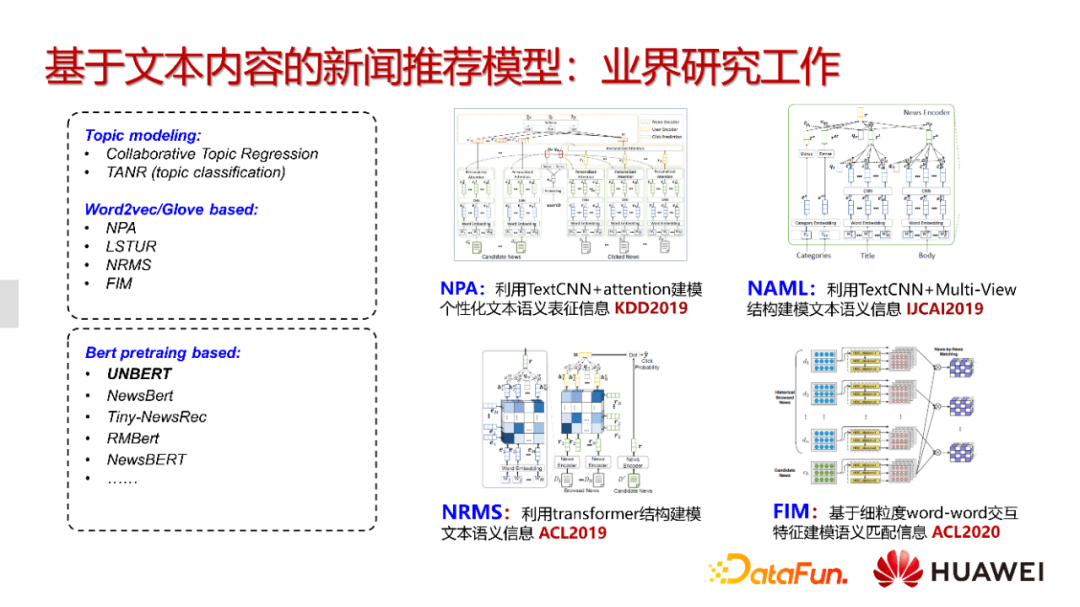
我们首先理解一下基于文本内容的新闻推荐模型。就目前业界的研究来看,微软亚洲研究院做的工作比较多,主要是分为以下几个方面。
第一个是Topic Modeling。随着LDA模型的提出,Topic Modeling在文本内容建模以及基于内容的推荐中得到了广泛的应用。但是LDA是一个无监督学习方法,很多时候它的效果取决于语料的选择,而且LDA得到的embedding与下游任务并不是百分之百匹配,就只能部分地去解决语义理解的问题。
随着深度模型的提出,更多的模型开始采取像Word2Vec或者Glove的word embedding的方式来对词的语义进行建模,但更多时候是以一种token初始化或者相似度来建模并融入到模型中。从2020年开始,很多团队开始尝试将BERT应用到新闻推荐的任务中,比如微软、我们团队。
图中展示了四个微软的前期工作,比如NPA,这是利用TextCNN来建立token之间的相关关系和文本语义表征,然后利用attention的方法来得到用户的兴趣表征。有了用户的兴趣表征和新闻的语义表征,就可以进行语义匹配任务。类似的方法包括NAML和NRMS,分表利用Multi-view和Multi-head技术进行建模。除了这些基于向量表征的方式,也有基于token级别的匹配关系建模的方法,比如FIM,该模型计算的就是文本token与token之间的相似度。但总的来说这些方法比较依赖下游任务的训练,并没有充分利用到NLP领域的语言知识。
如何充分利用pretrain + finetune的方式来提高新闻推荐的效果,这是我们的思考点。
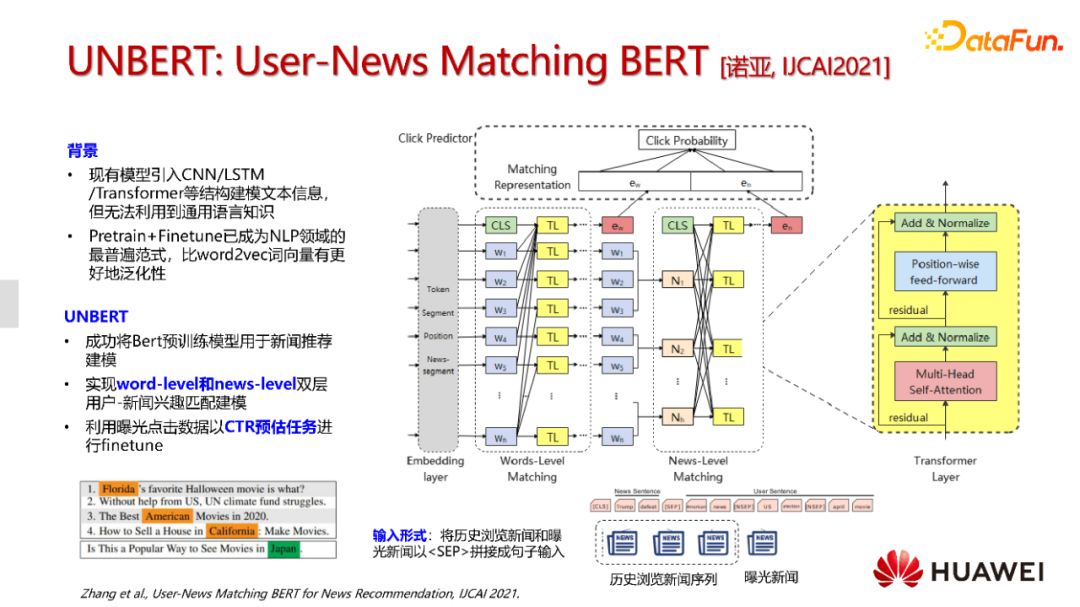
基于此,我们提出了UNBERT,通过预训练的新闻文本表征来优化推荐模型本身。
这个模型的输入就是将用户的阅读的历史新闻和曝光的新闻进行拼接,当成一个整体的句子进行输入。句子与句子之间用不同的分隔符以及segment id进行表征,并借此来判断是历史阅读的新闻还是曝光新闻。由于BERT是对token与token之间的关系进行建模,我们通过CLS token这种结构对新闻token level的匹配信息进行建模。比如不同新闻之间token级别的相似性可以在这一层表现出来。但是BERT本身不具备句子表征的优势,我们的做法就是按照segment id对不同新闻进行pooling得到新闻向量,然后再经过相应的transformer来对新闻之间的相似性建模,这样做的好处能够判断曝光新闻更历史阅读新闻之间句子级别的相似性度。最后进行两层的融合输出预测分数。
训练任务就是通过使用点击日志数据参考CTR任务来进行二分类训练。这里我们遇到的难题就是如何优化BERT来保证效率。
首先我们看一下模型的效果。
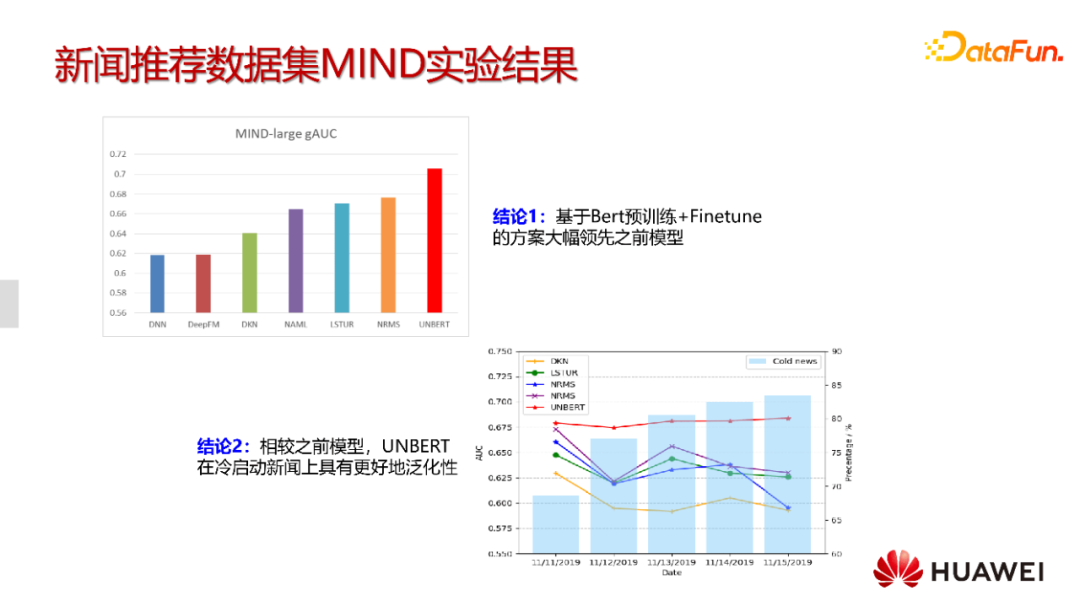
这种简单的借鉴NLP的pretrain + finetune的方式带来了离线效果的显著提升。相较于前面提到的基于transformer的NRMS和attention的NAML都有很大的性能提升。
我们认为这种效果提升并不是transformer结构本身,而是利用了BERT预训练模型中包含的大量通用语言知识。这种知识是从领域外的大量训练语料带来的,并且是传统新闻推荐无法做到的。除此之外,我们再对比不同的模型在时间维度(天)的一个表现,这个柱状图是按照每天产生的新新闻加入到评估中,可以看出来UNBERT的表现相对更加稳定,而其他基于ID类的方法都会下跌比较厉害,也就是说这种基于BERT的新闻推荐模型在冷启动方面有更好的泛化能力。
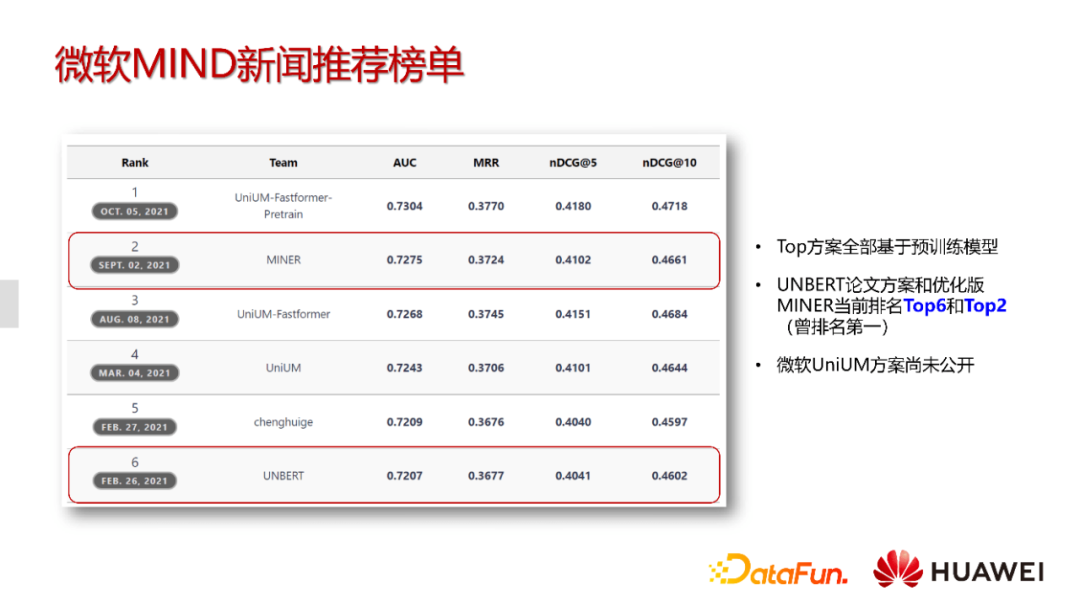
我们在微软的MIND新闻数据集上进行了比较长时间的尝试。
最开始的UNBERT方案现在排名第六,并且经过改进的MINER方案现在排名第二。两个方案都是采取比较一致的结构,基于BERT结构然后加上CTR数据进行finetune得到。并且可以看到,排名靠前的方案都是基于BERT结构做的。
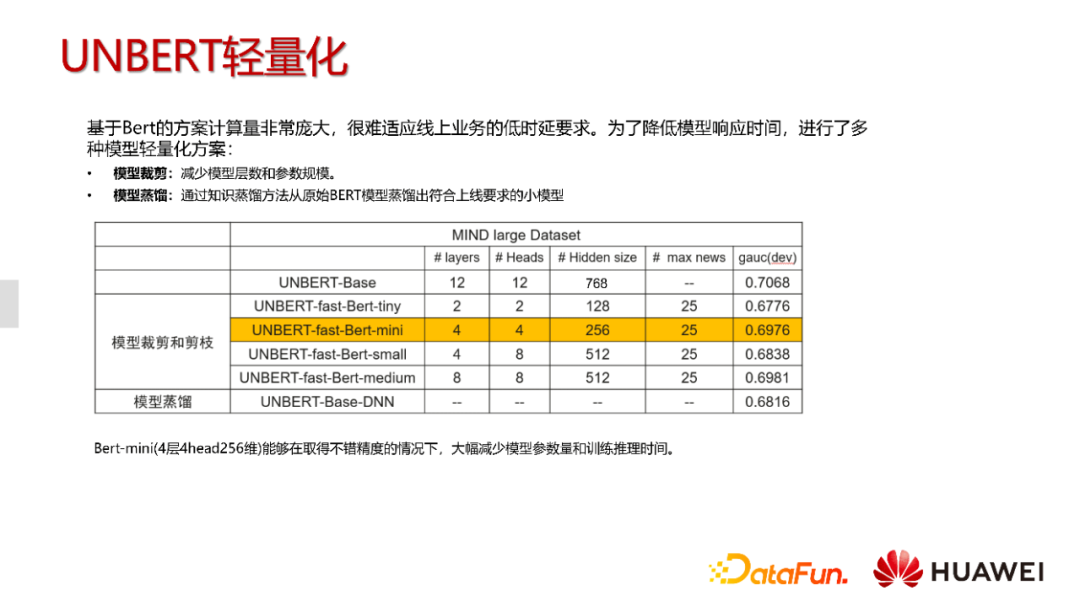
更重要的改进是如何将基于BERT的方案优化到能够进行线上服务的程度,这个工作量远比离线实验大。
首先,BERT的计算量非常庞大,很难适应线上的业务需求。为了达到该需求,我们进行了很多尝试。第一个就是直接对模型的参数和层数进行裁剪,并进行了一定对比,另外也验证了模型知识蒸馏方案的效果。可以看到,将BERT-Base的层数缩减为四层左右得到的BERT-mini,所降低的点数不是很多。但相对于原始的模型的话,还是能带来一些增益。
另外采用知识蒸馏的结构的话,会将原始模型蒸馏到像MLP这种DNN结构,也能带来一些增益。但是最后我们没有采取这种方式,因为蒸馏方法虽然能够带来推理效率的大幅提升,可训练时长却是普通方案的两倍。最后我们还是采取了小型BERT的方案。
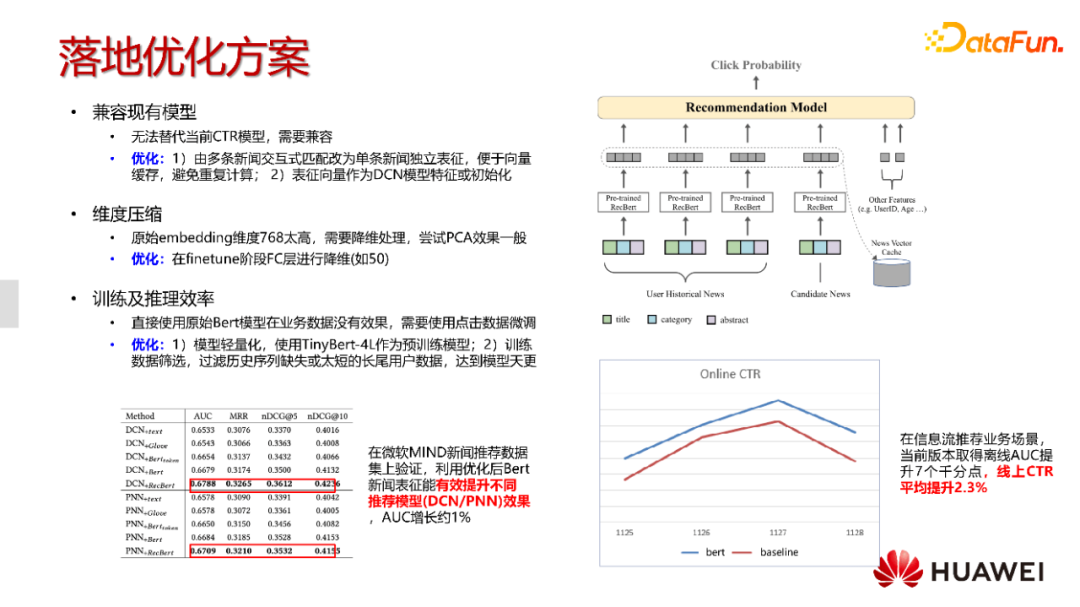
为了落地,我们采取了如下的一些优化方式。
首先就是模型的兼容,我们本来设想取代现有的CTR模型。但是当前上线的模型已经过多年的优化,有很多不可替代的统计类特征,还有ID类特征。直接用基于文本的BERT模型的话,效果上还存在一定差距。所以我们思考如何利用模型的优势来提升现有线上方案的效果,最后决定采用DCN结构的方式来兼容这种ID类模型。UNBERT是基于token与token level的匹配,以及news与news level的匹配,所以很难做到离线的缓存。为了做到这一点,我们在上线过程中把每个新闻的表征给解耦了。在进行了分离并训练之后,我们能够得到每个新闻的表征,并将这些向量缓存到cache里面。在实时推理的时候,我们只需要从cache中取得当前新闻的表征就能进行推理。
第二点,如果原始模型直接拿来用,是维度为768的embedding,这对于下游任务来说,这个维度太高了,而且我们的新闻量可能是百万或上亿级别,这样不仅内存消耗高,运算也会很慢。我们尝试过通过PCA的方式进行降维,但是线上效果并不理想。因为对于BERT来讲,finetune是非常重要的,所以我们在模型上加上全连接层降维,然后进行finetune,得到50维的向量来表示一个新闻。
第三点,我们非常关注训练和推理的效率,因为如果不使用业务数据进行finetune,上线效果表现有限,我们还是希望能够做到每天更新一次。不同于NLP和CV领域,推荐系统不仅强调推理阶段的轻量化,也要保证数据的实时性和模型的更新效率。
如何在训练阶段保证效率呢?我们首先采用诺亚提出的4层TinyBert作为预训练模型。另外,在数据方面,MIND数据集只有几千万的数据,基本一天以内就能处理得非常好。但是在实际业务中,我们经常遇到上亿甚至是十亿级别的新闻交互数据。如果要完全过一遍数据的话,往往需要几天时间,是不可能做到以天为单位进行更新的。为了达到天更的目的,我们对数据进行了一定的筛选,一些长尾用户,比如点击历史太短或者缺失就被过滤掉,这样就能降低数据量,保留更多拥有历史点击序列和曝光序列的序列对。通过这些序列对,我们能够做到天更。我们最后在公开数据集和业务数据集上都验证了这个方案。
之前的纯BERT模型,能够在榜单上取得很好的成绩,能否让传统模型比如DeepFM/DCN也得到提升呢?我们最后经过验证发现,只要是经过finetune之后,这种传统的模型也能带来AUC百分位的提升。在正式上线并经过一段时间测试后,CTR有2.3%的平均提升。但是目前我们的挖掘还不充分,当前版本只用了新闻的标题。后续我们还计划把整个文章内容都进行进一步的优化。但是如果想对整个文本进行建模,我们可能需要对效率进行更多的考量,因为文章本身的token更多,难度会更大。
2. 用户视角下的新闻界面表征建模
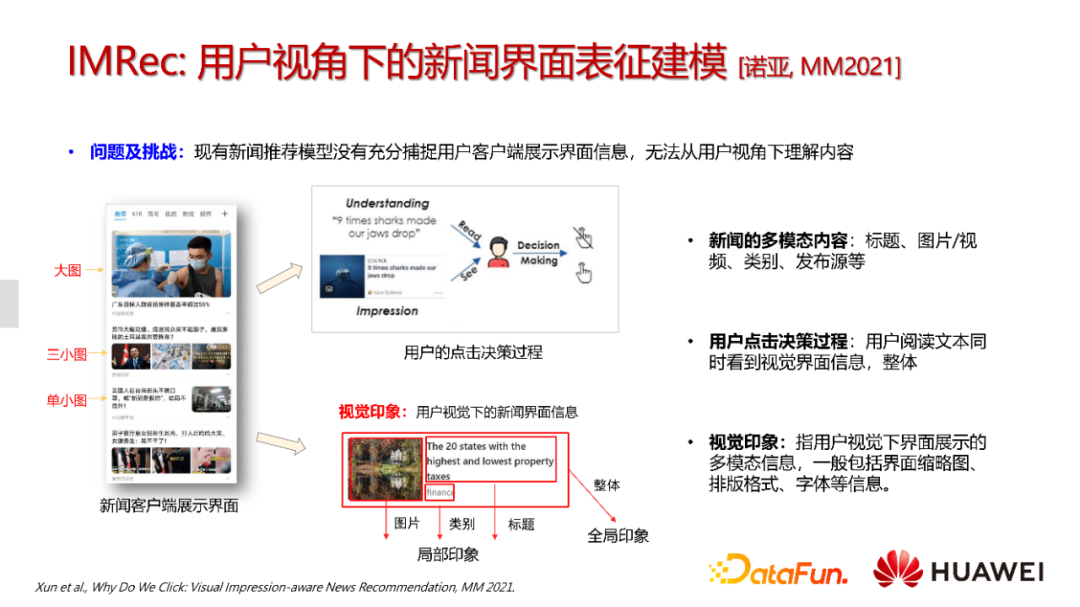
我们的第二个工作是在MM2021上发表的工作。现有新闻推荐模型都是从资料库取出新闻,它可能包括文本、图片,但是没有展示在界面的信息。如果我们的模型能够捕捉到用户视角下的界面信息,比如把阅读一张图片的不同排版信息捕捉下来,可能是大图,三张小图或者是单小图。当前视觉模型是做不到这一点的。
如何来捕捉这种信息呢?
我们设计了这样的模型。用户观看的第一印象往往决定了是否产生点击行为,我们称这个为视觉印象。直观理解就是图片或是标题里的关键词是不是吸引人?给用户留下了怎样的印象?我们把整个新闻界面划分为多个卡片,每个卡片包含几个子领域,包括图片、类别、标题等。以图中的展示界面为例,一张卡片包含图片、类别和标题的局部印象,同时整体卡片也能获取一个全局的表征,我们称为全局印象。这样包含了展示方式的建模其实就是我们希望获取的在用户视角下的展示界面的多模态信息。
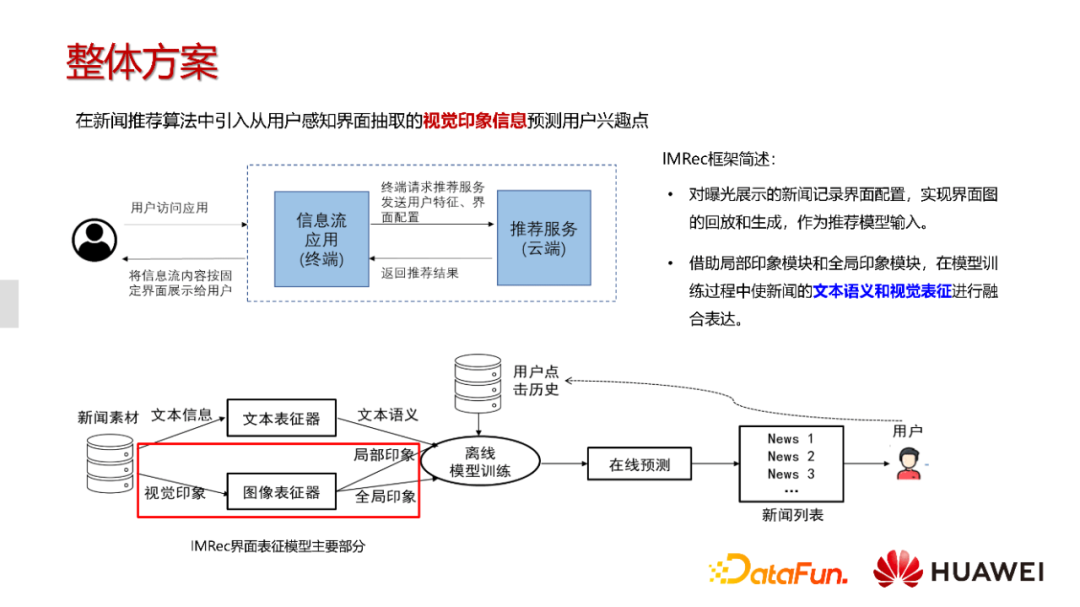
整个方案的设计和实现是比较直观的,在用户在发起请求之后,我们希望不仅能够获得新闻相关行为信息,也能够获得新闻在界面上的展示形态,比如具体是呈现哪一种视觉表达形式。根据这个表征形式,我们能够更好的建模整个新闻内容,进而返回更加精确的推荐结果给用户。
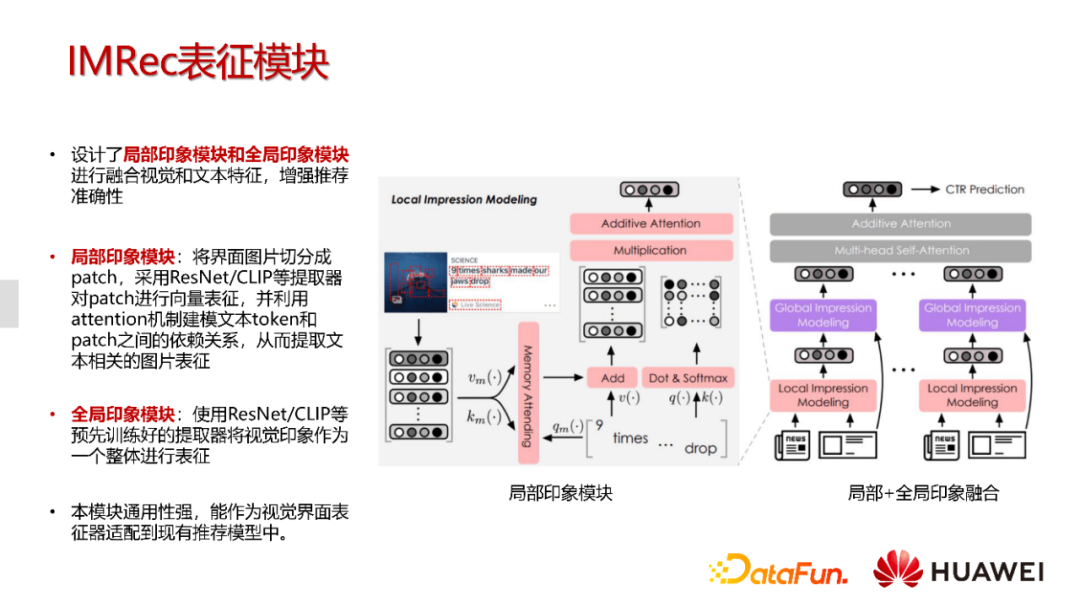
相对于传统新闻推荐,我们加入了一个界面表征模块,这个模块包含了局部印象和全局印象。
局部印象模块会把整个卡片按照固定的大小切成很多patch,然后采用预训练的ResNet或CLIP获取向量表征。接着进行索引计算,并对标题文本进行双映射,也就是文本的token和patch之间进行一个相关性的计算。我们通过第一层的attention计算来对图片和文本的相关性进行计算。然后我们也会对token之间和patch之间的相关性进行计算,最终产生丰富的多模态表达。最后的输出其实是卡片图片的一个表征,不同之处在于,它的建模方式是条件式的,也就是说当给我们对应的文本,我们的整个卡片图片表征应该是什么样的?如果我们的patch分得足够细,就能够捕捉到大图或者小图,字体风格或者文字排版等关键信息,它的建模方式会更加丰富。
另外,我们也会把卡片当成一张整体的图进行全局的建模,比如采取ResNet或者CLIP。最后,把全局表征和局部表征进行融合,作为新闻的一个向量特征输入到CTR模型中。由于这个模型采用了大概三层的attention结构,这会带来比较高复杂度。通常情况下,引入多模态信息的话,模型的复杂度会大于普通模型,所以与Bert模型的使用相同,我们采取离线计算卡片向量并缓存的方式。
我们来看一下结果,也是在MIND的数据集上,我们通过模拟的方式生成界面卡片信息,然后对应到不同的新闻上面,最后再对比现有的模型,我们发现多模态信息能够带来较大的提升,AUC的提升能够到百分位点。同时,我们也对比了基于界面的新闻和不带图片的新闻,可以发现,当引入新闻界面信息是能够带来性能提升。比如NRMS的提升能够达到两个百分点,也就是说图片本身对于用户点击的提升效果还是很明显的。
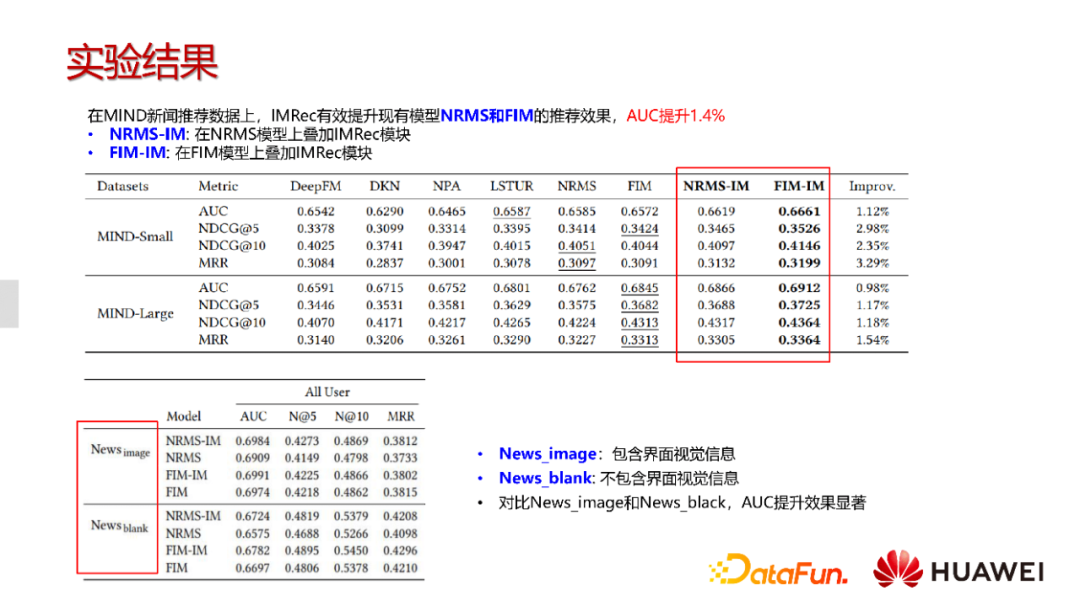
从图中可以看出,想较与基线模型NRMS和FIM,我们方案取得了较大的指标提升。这里面就包括界面卡片的表征、历史阅读新闻卡片的表征。那么问题的关键就是如何把模型真正应用到业务系统里面去。但是在实际落地中,我们遇到了很多挑战。
第一点是是数据问题。由于图片本身存储是比较大的,现在只有大概近一个月的数据,这就造成我们在对用户进行建模的时候,较长的历史行为无法拿到对应的图片,也就没法生成界面,这造成我们的覆盖率不够高。
第二点是是工程上的问题。如果要实时训练和推理的话,我们需要用户界面的图片进行建模和表征,这就需要定制化一些方法对界面展示进行模拟和回放。这些工程化内容还在进行当中。对于线上推理环节来说,由于我们已经上线了基于文本的向量表征模型,我们需要思考如何与先有的模型进行叠加,而不是分开建模。因为分开建模代价很高,需要缓存两份embedding,而且线上推理的时候,由于embedding数量越来越多,也会影响推理的速度。所以我们考虑如何通过文本和图片联合给出多模态表征。目前,我们还没有完全上线模型,但是我们也做了一些工程化的优化,并有了一定结果。总体来讲,我们发现,对于新闻、短视频等信息流推荐,多模态的表征能够很好得提升推荐的效果。

05
展望
我们对于下一阶段的工作还有很多展望。
第一方面是如何高效地预训练模型并且微调。现有的研究工作都是强调极简计算或模型量化,目的是在手机端运行一个小模型。但是并不在意模型的更新效率。那么在推荐领域,我们需要做到快速更新模型,而实时数据推荐领域的数据量又非常大。之前我们的方案都是按照序列数据进行finetune,因为每个用户都有各自的序列,这就造成数据量很大。所以我们思考可不可以从数据pair的结构上进行数据缩减。不同的用户,可能它阅读过的的item pair是一致的,这样我们可能进行合并和优化计算。另外,微软也公布了一种SpeedyFeed的方法,我们目前在业务数据上进行了一定初步尝试,效率提升在2-3倍左右。但如果要进行全量数据更新的话,SpeedyFeed也还是无法做到天更,还需要结合对数据进行一定筛选。
第二方面就是如何只对pretrained embeddings进行微调。如果我们同时考虑多种模态、文本、视觉、音频等,那么我们的模型就会越来越多。很有可能我们做不到对多个大模型同时finetune,所以我们考虑能不能直接在embedding上进行finetune。但是现在这种在embedding上直接加多层MLP,效果并不好。这是未来的一个研究点。另外一点就是文本BERT表征和图片视觉表征如何进一步融合并兼容到现有的推荐结构里面来得到提升。现在所做的尝试包括pretrained embedding作为初始化,向量表征或者通过相似性计算来改进现有模型,比如DCN或者DIN结构。我们线上方案采用向量初始化方案,因为它对推理接口的改动很小。如果我们有不同模态的向量,就不能简单使用初始化的方法,因为初始化只能用一种向量。如何在下游任务上利用多种embedding,也是可以探索的点。另外,对于融入了视觉卡片的应用,在推理阶段,我们只是做到了单新闻的评估,并不可能知道用户当前上下文展示的是什么新闻。在完成排序之前,我们是不知道这个信息的,而一旦排序之后,我们就可以获取到这个信息,所以在训练阶段,这个信息是可以获取的。如何在训练阶段利用这种上下文信息来更好捕捉用户的视觉偏好,也是我们可以探索的点。

一起交流
想和你一起学习进步!『NewBeeNLP』目前已经建立了多个不同方向交流群(机器学习 / 深度学习 / 自然语言处理 / 搜索推荐 / 图网络 / 面试交流 / 等),名额有限,赶紧添加下方微信加入一起讨论交流吧!(注意一定o要备注信息才能通过)


最后
以上就是幽默帅哥最近收集整理的关于他山之石 | 预训练模型在华为推荐中的应用与探索的全部内容,更多相关他山之石内容请搜索靠谱客的其他文章。








发表评论 取消回复