
来源:新智元
整理:肖琴
本文约6400字,建议阅读10+分钟。
谷歌在今年的CVPR上表现强势,有超过200名谷歌员工将在大会上展示论文或被邀请演讲,45篇论文被接收。在计算机视觉领域,生成对抗网络GAN无疑是最受关注的主题之一,本文一并带来谷歌 Staff Research Scientist、GAN的提出人Ian Goodfellow在CVPR 2018上作关于GAN的演讲的PPT。
今天,2018年计算机视觉和模式识别会议(CVPR 2018)正在盐湖城举办,这是计算机视觉领域最重要的年度学术会议,包括主大会和若干workshop和tutorial。作为会议的钻石赞助商,谷歌在今年的CVPR上同样表现强势,有超过200名谷歌员工将在大会上展示论文或被邀请演讲,谷歌也组织和参与了多个研讨会。
根据谷歌官方博客,CVPR 2018谷歌共有45篇论文被接收。这些论文关注下一代智能系统和机器感知领域的最新机器学习技术,包括Pixel 2和Pixel 2 XL智能手机的人像模式背后的技术,V4版本的Open Images数据集等等。
地址:
https://ai.googleblog.com
http://www.iangoodfellow.com/slides/2018-06-18.pdf
Google at CVPR 2018
组织者
财务主席:Ramin Zabih
领域主席:Sameer Agarwal, Aseem Agrawala, Jon Barron, Abhinav Shrivastava, Carl Vondrick, Ming-Hsuan Yang
论文列表
Orals/Spotlights
作为结构表示的对象标志的无监督发现
Unsupervised Discovery of Object Landmarks as Structural Representations
Yuting Zhang, Yijie Guo, Yixin Jin, Yijun Luo, Zhiyuan He, Honglak Lee
DoubleFusion:利用单个深度传感器实时捕捉人体的内体形状
DoubleFusion: Real-time Capture of Human Performances with Inner Body Shapes from a Single Depth Sensor
Tao Yu, Zerong Zheng, Kaiwen Guo, Jianhui Zhao, Qionghai Dai, Hao Li, Gerard Pons-Moll, Yebin Liu
用于无监督运动重定向的神经运动网络
Neural Kinematic Networks for Unsupervised Motion Retargetting
Ruben Villegas, Jimei Yang, Duygu Ceylan, Honglak Lee
用核预测网络去噪
Burst Denoising with Kernel Prediction Networks
Ben Mildenhall, Jiawen Chen, Jonathan Barron, Robert Carroll, Dillon Sharlet, Ren Ng
神经网络的量化和训练,以实现高效的整数运算推理
Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference
Benoit Jacob, Skirmantas Kligys, Bo Chen, Matthew Tang, Menglong Zhu, Andrew Howard, Dmitry Kalenichenko, Hartwig Adam
AVA:一个时空本地化原子视觉动作视频数据集
AVA: A Video Dataset of Spatio-temporally Localized Atomic Visual Actions
Chunhui Gu, Chen Sun, David Ross, Carl Vondrick, Caroline Pantofaru, Yeqing Li, Sudheendra Vijayanarasimhan, George Toderici, Susanna Ricco, Rahul Sukthankar, Cordelia Schmid, Jitendra Malik
视觉问答的视觉-文本注意力焦点
Focal Visual-Text Attention for Visual Question Answering
Junwei Liang, Lu Jiang, Liangliang Cao, Li-Jia Li, Alexander G. Hauptmann
推断来自阴影中的光场
Inferring Light Fields from Shadows
Manel Baradad, Vickie Ye, Adam Yedida, Fredo Durand, William Freeman, Gregory Wornell, Antonio Torralba
修改多个视图中的非本地变量
Modifying Non-Local Variations Across Multiple Views
Tal Tlusty, Tomer Michaeli, Tali Dekel, Lihi Zelnik-Manor
超越卷积的迭代视觉推理
Iterative Visual Reasoning Beyond Convolutions
Xinlei Chen, Li-jia Li, Fei-Fei Li, Abhinav Gupta
3D形变模型回归的无监督训练
Unsupervised Training for 3D Morphable Model Regression
Kyle Genova, Forrester Cole, Aaron Maschinot, Daniel Vlasic, Aaron Sarna, William Freeman
学习可扩展图像识别的可转换架构
Learning Transferable Architectures for Scalable Image Recognition
Barret Zoph, Vijay Vasudevan, Jonathon Shlens, Quoc Le
生物物种分类和检测数据集
The iNaturalist Species Classification and Detection Dataset
Grant van Horn, Oisin Mac Aodha, Yang Song, Yin Cui, Chen Sun, Alex Shepard, Hartwig Adam, Pietro Perona, Serge Belongie
利用观察世界来学习内在的图像分解
Learning Intrinsic Image Decomposition from Watching the World
Zhengqi Li, Noah Snavely
学习智能对话框用于边界框注释
Learning Intelligent Dialogs for Bounding Box Annotation
Ksenia Konyushkova, Jasper Uijlings, Christoph Lampert, Vittorio Ferrari
Posters
重新审视训练对象类别检测器的知识迁移
Revisiting Knowledge Transfer for Training Object Class Detectors
Jasper Uijlings, Stefan Popov, Vittorio Ferrari
重新思考用Faster R-CNN架构进行时间动作定位
Rethinking the Faster R-CNN Architecture for Temporal Action Localization
Yu-Wei Chao, Sudheendra Vijayanarasimhan, Bryan Seybold, David Ross, Jia Deng, Rahul Sukthankar
视觉对象识别的层次式新颖性检测
Hierarchical Novelty Detection for Visual Object Recognition
Kibok Lee, Kimin Lee, Kyle Min, Yuting Zhang, Jinwoo Shin, Honglak Lee
COCO-Stuff:语境中的事物和材料类别
COCO-Stuff: Thing and Stuff Classes in Context
Holger Caesar, Jasper Uijlings, Vittorio Ferrari
用于视频分类的外观关系网络
Appearance-and-Relation Networks for Video Classification
Limin Wang, Wei Li, Wen Li, Luc Van Gool
MorphNet:深度网络的快速简单资源约束结构学习
MorphNet: Fast & Simple Resource-Constrained Structure Learning of Deep Networks
Ariel Gordon, Elad Eban, Bo Chen, Ofir Nachum, Tien-Ju Yang, Edward Choi
图形卷积自动编码器的可变形形状补完
Deformable Shape Completion with Graph Convolutional Autoencoders
Or Litany, Alex Bronstein, Michael Bronstein, Ameesh Makadia
MegaDepth:从互联网照片学习单视图深度预测
MegaDepth: Learning Single-View Depth Prediction from Internet Photos
Zhengqi Li, Noah Snavely
作为结构表示的对象标志的无监督发现
Unsupervised Discovery of Object Landmarks as Structural Representations
Yuting Zhang, Yijie Guo, Yixin Jin, Yijun Luo, Zhiyuan He, Honglak Lee
用核预测网络去噪
Burst Denoising with Kernel Prediction Networks
Ben Mildenhall, Jiawen Chen, Jonathan Barron, Robert Carroll, Dillon Sharlet, Ren Ng
神经网络的量化和训练,以实现高效的整数运算推理
Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference
Benoit Jacob, Skirmantas Kligys, Bo Chen, Matthew Tang, Menglong Zhu, Andrew Howard, Dmitry Kalenichenko, Hartwig Adam
Pix3D:单图像3D形状建模的数据集和方法
Pix3D: Dataset and Methods for Single-Image 3D Shape Modeling
Xingyuan Sun, Jiajun Wu, Xiuming Zhang, Zhoutong Zhang, Tianfan Xue, Joshua Tenenbaum,William Freeman
用于表示和编辑图像的稀疏智能轮廓
Sparse, Smart Contours to Represent and Edit Images
Tali Dekel, Dilip Krishnan, Chuang Gan, Ce Liu, William Freeman
MaskLab:通过使用语义和方向特征优化对象检测进行实例分割
MaskLab: Instance Segmentation by Refining Object Detection with Semantic and Direction Features
Liang-Chieh Chen, Alexander Hermans, George Papandreou, Florian Schroff, Peng Wang,Hartwig Adam
大规模细粒度分类和领域特定的迁移学习
Large Scale Fine-Grained Categorization and Domain-Specific Transfer Learning
Yin Cui, Yang Song, Chen Sun, Andrew Howard, Serge Belongie
改进的带有初始值和空间自适应比特率的有损网络压缩
Improved Lossy Image Compression with Priming and Spatially Adaptive Bit Rates for Recurrent Networks
Nick Johnston, Damien Vincent, David Minnen, Michele Covell, Saurabh Singh, Sung Jin Hwang, George Toderici, Troy Chinen, Joel Shor
MobileNetV2:反向残差和线性瓶颈
MobileNetV2: Inverted Residuals and Linear Bottlenecks
Mark Sandler, Andrew Howard, Menglong Zhu, Andrey Zhmoginov, Liang-Chieh Chen
ScanComplete:3D扫描的大规模场景补完和语义分割
ScanComplete: Large-Scale Scene Completion and Semantic Segmentation for 3D Scans
Angela Dai, Daniel Ritchie, Martin Bokeloh, Scott Reed, Juergen Sturm, Matthias Nießner
Sim2Real通过循环控制查看不变视觉伺服
Sim2Real View Invariant Visual Servoing by Recurrent Control
Fereshteh Sadeghi, Alexander Toshev, Eric Jang, Sergey Levine
Alternating-Stereo VINS:可观测性分析和性能评估
Alternating-Stereo VINS: Observability Analysis and Performance Evaluation
Mrinal Kanti Paul, Stergios Roumeliotis
Soccer on Your Tabletop
Konstantinos Rematas, Ira Kemelmacher, Brian Curless, Steve Seitz
使用3D几何约束从单眼视频中无监督地学习深度和自我运动
Unsupervised Learning of Depth and Ego-Motion from Monocular Video Using 3D Geometric Constraints
Reza Mahjourian, Martin Wicke, Anelia Angelova
AVA:一个时空本地化原子视觉动作视频数据集
AVA: A Video Dataset of Spatio-temporally Localized Atomic Visual Actions
Chunhui Gu, Chen Sun, David Ross, Carl Vondrick, Caroline Pantofaru, Yeqing Li, Sudheendra Vijayanarasimhan, George Toderici, Susanna Ricco, Rahul Sukthankar, Cordelia Schmid, Jitendra Malik
推断来自阴影中的光场
Inferring Light Fields from Shadows
Manel Baradad, Vickie Ye, Adam Yedida, Fredo Durand, William Freeman, Gregory Wornell, Antonio Torralba
修改多个视图中的非本地变量
Modifying Non-Local Variations Across Multiple Views
Tal Tlusty, Tomer Michaeli, Tali Dekel, Lihi Zelnik-Manor
用于单目深度估计的孔径监控
Aperture Supervision for Monocular Depth Estimation
Pratul Srinivasan, Rahul Garg, Neal Wadhwa, Ren Ng, Jonathan Barron
实例嵌入转移到无监督视频对象分割
Instance Embedding Transfer to Unsupervised Video Object Segmentation
Siyang Li, Bryan Seybold, Alexey Vorobyov, Alireza Fathi, Qin Huang, C.-C. Jay Kuo
帧回放视频超分辨率
Frame-Recurrent Video Super-Resolution
Mehdi S. M. Sajjadi, Raviteja Vemulapalli, Matthew Brown
稀疏时间池网络的弱监督动作定位
Weakly Supervised Action Localization by Sparse Temporal Pooling Network
Phuc Nguyen, Ting Liu, Gautam Prasad, Bohyung Han
超越卷积的迭代视觉推理
Iterative Visual Reasoning Beyond Convolutions
Xinlei Chen, Li-jia Li, Fei-Fei Li, Abhinav Gupta
学习和使用时间箭头
Learning and Using the Arrow of Time
Donglai Wei, Andrew Zisserman, William Freeman, Joseph Lim
HydraNets:高效推理的专用动态架构
HydraNets: Specialized Dynamic Architectures for Efficient Inference
Ravi Teja Mullapudi, Noam Shazeer, William Mark, Kayvon Fatahalian
在有限的监督下进行胸部疾病的识别和定位
Thoracic Disease Identification and Localization with Limited Supervision
Zhe Li, Chong Wang, Mei Han, Yuan Xue, Wei Wei, Li-jia Li, Fei-Fei Li
推断分层文本-图像合成的语义布局
Inferring Semantic Layout for Hierarchical Text-to-Image Synthesis
Seunghoon Hong, Dingdong Yang, Jongwook Choi, Honglak Lee
深层语义的脸部去模糊
Deep Semantic Face Deblurring
Ziyi Shen, Wei-Sheng Lai, Tingfa Xu, Jan Kautz, Ming-Hsuan Yang
3D形变模型回归的无监督训练
Unsupervised Training for 3D Morphable Model Regression
Kyle Genova, Forrester Cole, Aaron Maschinot, Daniel Vlasic, Aaron Sarna, William Freeman
学习可扩展图像识别的可转换架构
Learning Transferable Architectures for Scalable Image Recognition
Barret Zoph, Vijay Vasudevan, Jonathon Shlens, Quoc Le
利用观察世界来学习内在的图像分解
Learning Intrinsic Image Decomposition from Watching the World
Zhengqi Li, Noah Snavely
PiCANet:针对像素级的上下文注意力,以检测显著性
PiCANet: Learning Pixel-wise Contextual Attention for Saliency Detection
Nian Liu, Junwei Han, Ming-Hsuan Yang
Tutorials
机器人和驾驶中的计算机视觉
Computer Vision for Robotics and Driving
Anelia Angelova, Sanja Fidler
无监督视觉学习
Unsupervised Visual Learning
Pierre Sermanet, Anelia Angelova
UltraFast 3D感应,重建和理解人物、物体和环境
UltraFast 3D Sensing, Reconstruction and Understanding of People, Objects and Environments
Sean Fanello, Julien Valentin, Jonathan Taylor, Christoph Rhemann, Adarsh Kowdle, Jürgen Sturm, Christine Kaeser-Chen, Pavel Pidlypenskyi, Rohit Pandey, Andrea Tagliasacchi, Sameh Khamis, David Kim, Mingsong Dou, Kaiwen Guo, Danhang Tang, Shahram Izadi
生成对抗网络
Generative Adversarial Networks
Jun-Yan Zhu, Taesung Park, Mihaela Rosca, Phillip Isola, Ian Goodfellow
Ian Goodfellowa:生成对抗网络(35 PPT)

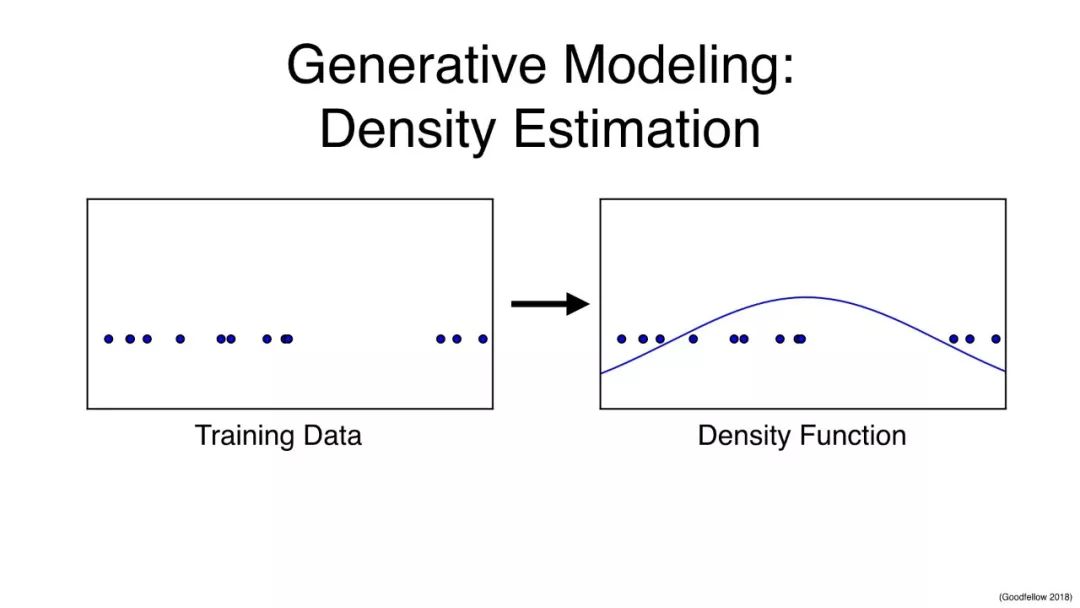
生成建模:密度估计
训练数据→密度函数

生成建模:样本生成
训练数据(CelebA)→样本生成
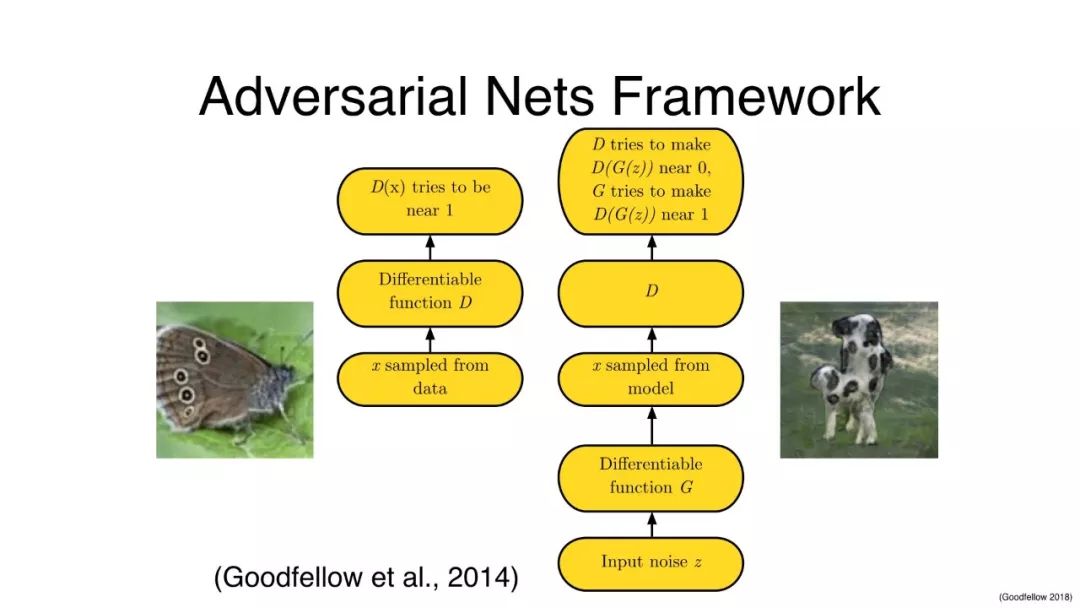
对抗网络的框架

Self-Attention GAN
ImageNet上最优的FID:1000个类别,128x128 像素
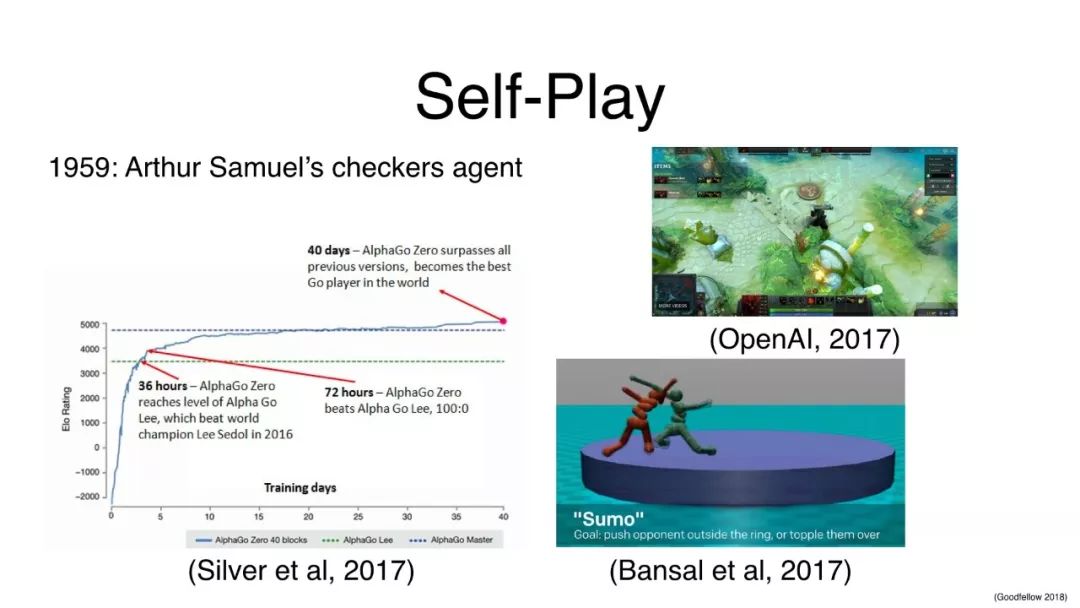
Self-Play

用GAN能做什么呢?
模拟环境和训练数据
缺失数据
半监督学习
多个正确答案
逼真的生成任务
基于模型的优化
自动化定制
域适应

自动驾驶数据集
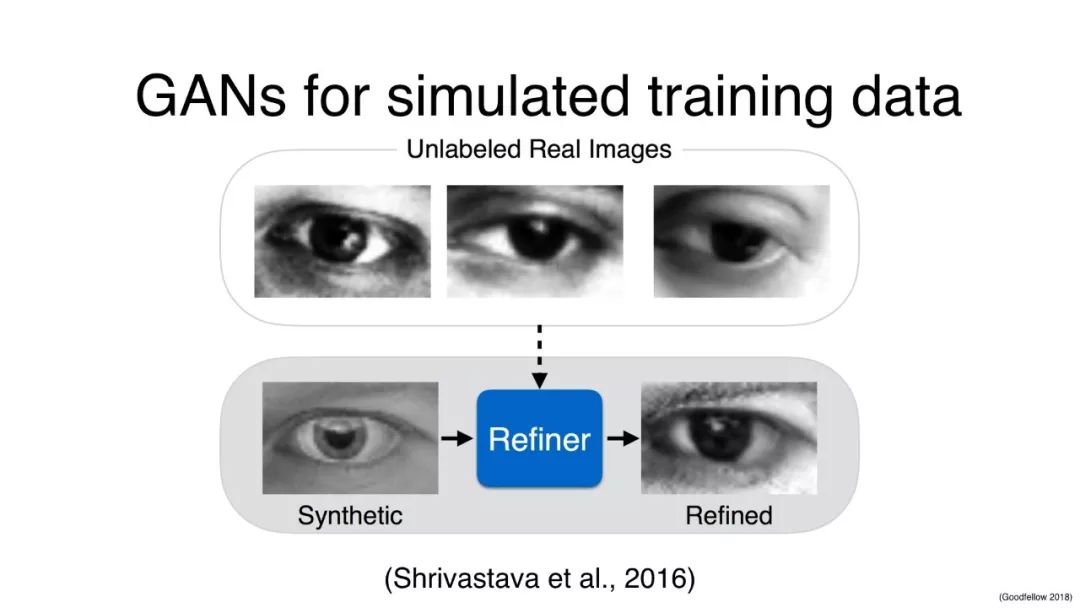
用于模拟训练数据的GAN


GAN用于缺失数据
从上面这张图像能看出什么呢?
用GAN模型看出它是一张脸
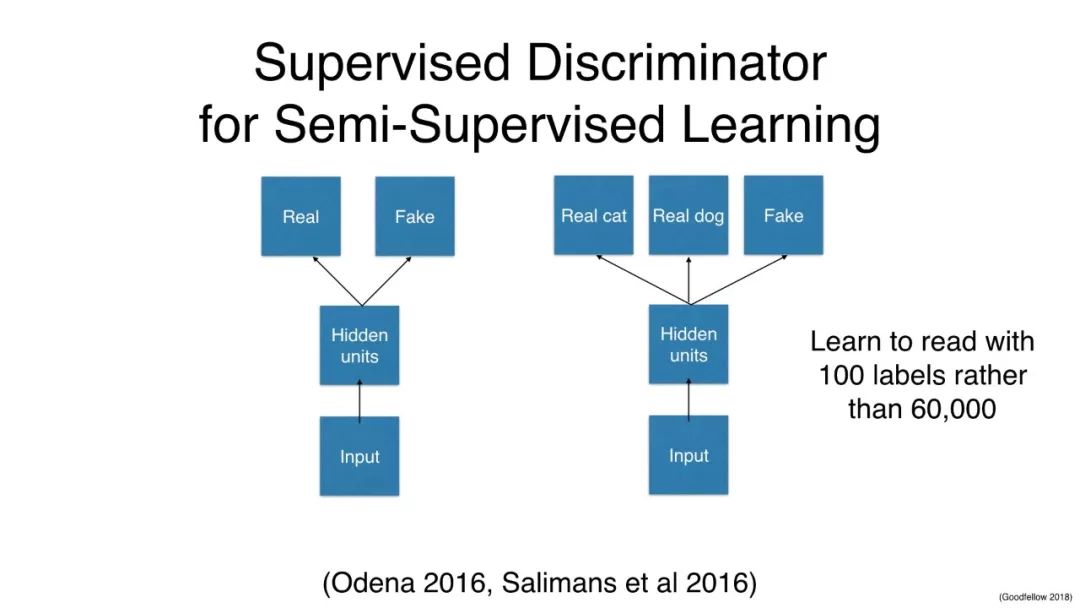

GAN用于半监督学习
用于半监督学习的有监督鉴别器
半监督分类
MNIST: 100训练标签 -> 80 测试错误
SVHN: 1000 训练标签 -> 4.3% 测试误差
CIFAR-10: 4000 标签 -> 14.4% 测试误差
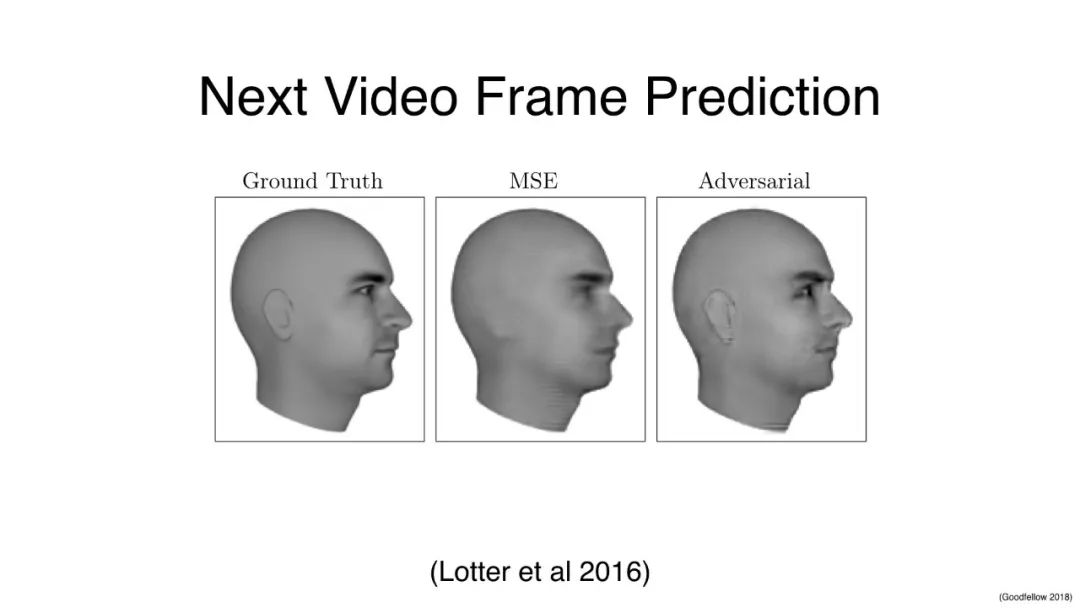

GAN用于下一帧视频的预测

GAN用于逼真的生成任务
iGAN

图像到图像翻译

无监督的图像到图像翻译

CycleGAN

文本-图像合成
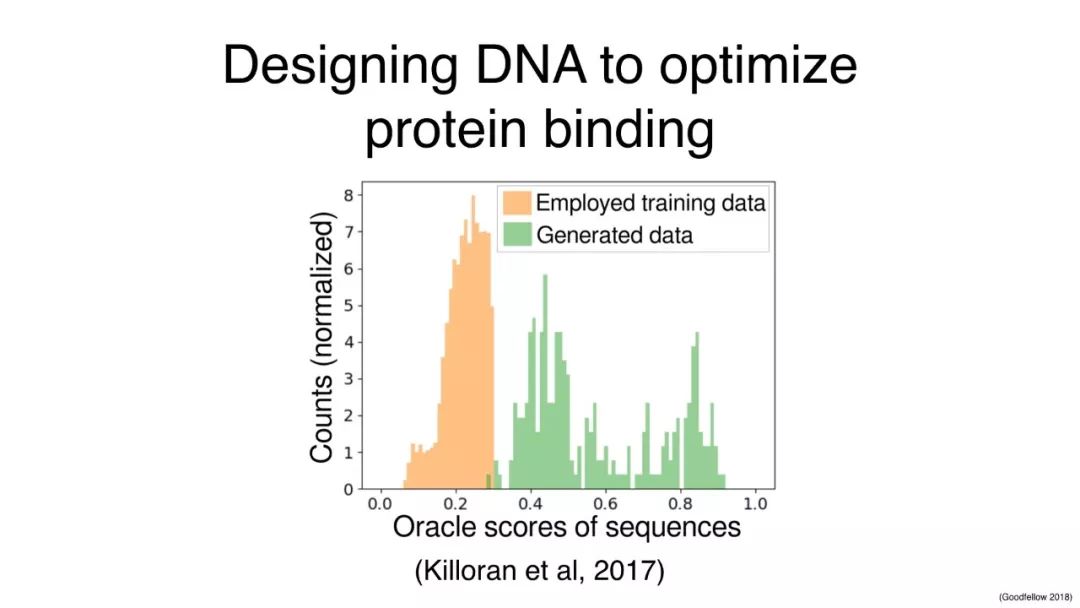
GAN用于基于模型的优化
设计DNA以优化蛋白质结合的研究
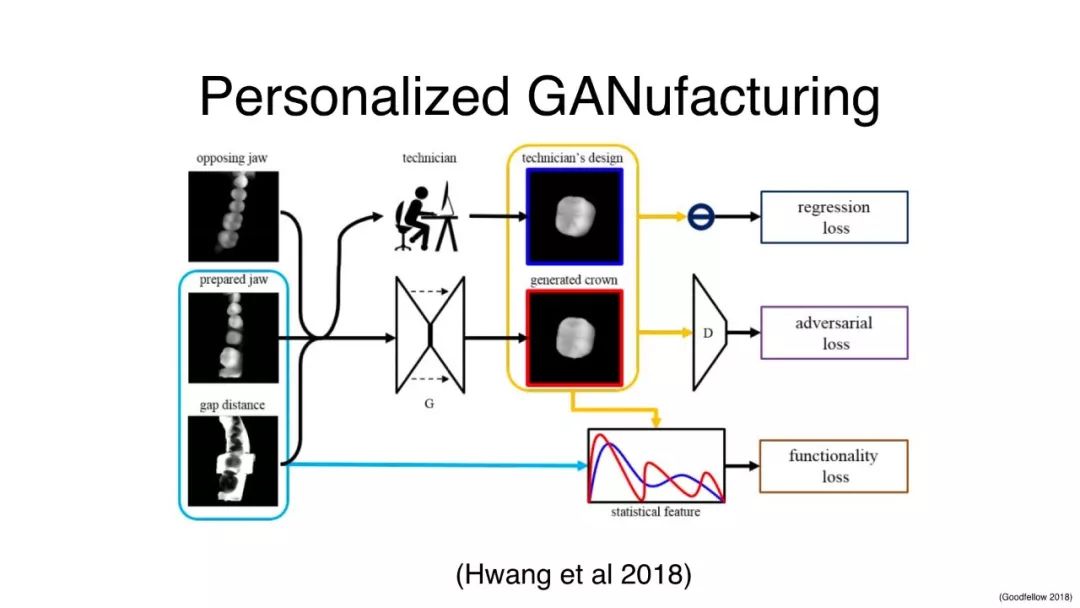
GAN用于自动化定制
个性化的GANufacturing


GAN用于域自适应
域对抗网络

GAN的一些技巧
在鉴别器和生成器中 (Zhang et al 2018) 都进行频谱归一化 (Miyato et al 2017)
生成器和鉴别器的学习率不同(Heusel et al 2017)
不需要比生成器更频繁地运行鉴别器(Zhang et al 2018)
许多不同的损失函数都能很好地工作(Lucic et al 2017); 可以花费更多时间调整超参数,而不是尝试不同的损失函数
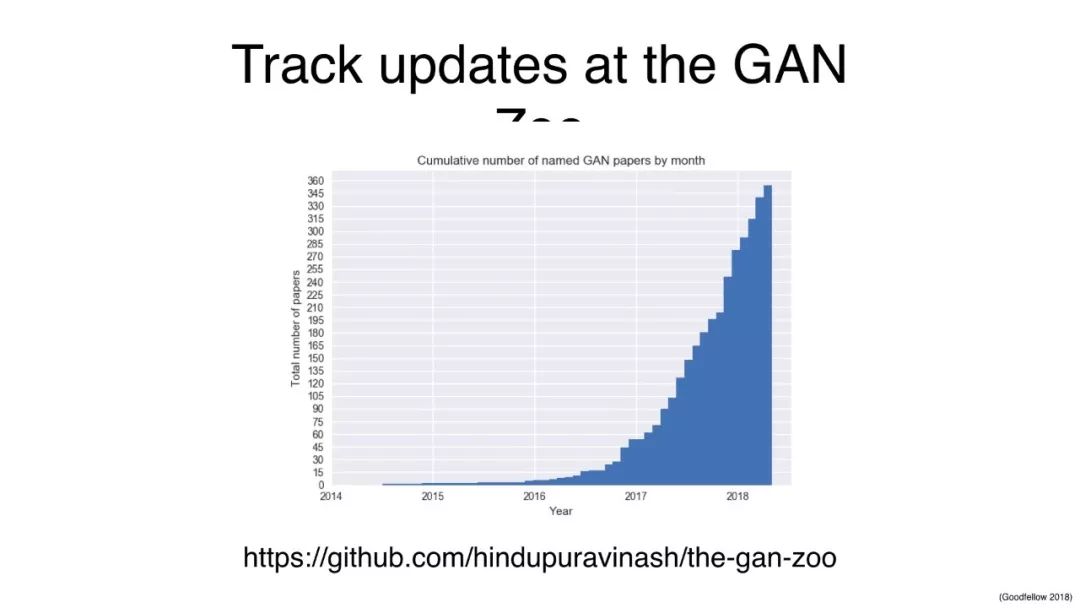


最后
以上就是干净星月最近收集整理的关于梳理谷歌45篇入选CVPR论文,后附GAN主题演讲PPT下载!的全部内容,更多相关梳理谷歌45篇入选CVPR论文内容请搜索靠谱客的其他文章。








发表评论 取消回复