之前上课的时候偶然间看到了知乎上关于特斯拉如何实现自动驾驶的详解,因为我本身就是做算法的,对自动驾驶也很感兴趣,得知信息来源于Tesla的AI Day,于是下课后马不停蹄就去找了回放好好学习学习。
视频连接:https://www.youtube.com/watch?v=j0z4FweCy4M
整个AI Day两三个小时,涉及特斯拉视觉解决方案、决策规划系统、数据标注、Hydranet、Dojo芯片和最吸引人眼球的Tesla Bot。
Pre-event

开场前的视频是一段Tesla全自动驾驶的演示视频,整体看下来可以发现驾驶过程非常流畅,如果不知道这是特斯拉的话从外看上去感觉并不会以为是自动驾驶。
不过也可以发现车辆在遇到行人或者会车的时候即使确定有足够的安全区间也会减速,这大概是为了安全考虑,也无可厚非。
另外自动驾驶过程中也还是要求驾驶者必须把手放在方向盘上,并不是真正意义上的完全自动驾驶,不需要人为干预,但是感觉现在能限制自动驾驶的只有法律要求了,Tesla能够从纯视觉方案实现这么流畅的自动驾驶还是非常让人惊讶的。
不过Tesla的全自动驾驶现在还只是测试版
AI Day Begins
开场Elon Musk就介绍到,Tesla不仅仅是一家电动汽车公司,同样也是现在世界AI的领导者,不仅仅是在自动驾驶领域,未来也会探索更多更有意义的应用。
Tesla Vision
整个AI Day中最令我激动的就是Tesla AutoPilot的视觉团队负责人 Andrej Karpathy给我们带来的特斯拉纯视觉方案自动驾驶的详细解析。
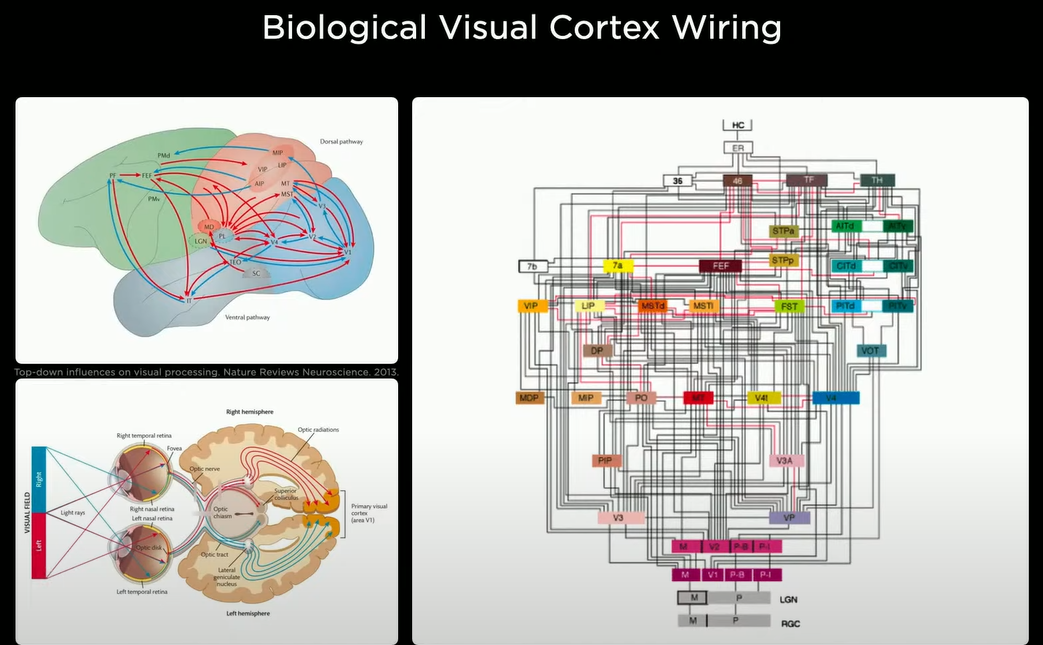
现在生物视觉皮层实际上有很多错综复杂的结构和组织大脑信息流的区域,特别是在视觉皮层中,信息光到达视网膜然后通过LGN一直到视觉皮层的不同区域。因此,Tesla在考虑设计汽车的视觉皮层时也在想设计信息如何在神经网络架构中流动。
最令人着迷的是,这是从头开始构建一种合成动物,将汽车视为一种动物,它可以在周围移动并感知环境,它的行为是自主和智能的。

从AI Day所提供的内容来看,特斯拉的视觉感知不仅仅解决看这个问题,更多的工作重心放在了对行为的追踪和预测这件事儿上,而所有的这一切都是在一个数字化的空间内完成了,这就是Andrej大神反复强调的Vector Space。

将摄像头拍摄的视频(道路交通线、交通标志、交通灯、汽车的位置/方向/速度等)经过神经网络处理成向量空间,从而呈现在汽车的仪表盘中。
其实这么做的动机很好理解,就拿个体分隔来说,算法识别出了哪里是路, 并且在摄像头拍摄的图片中画出两条线来标记,我们作为人类可以理解,但是这样的信息对于计算机来说完全没有意义,因为图像中的像素缺少空间信息,这其实也是特斯拉只是用视觉方案所面临的最大障碍。

如果使用激光雷达+高清地图,就可以很简单的完成对空间的感知,对此,特斯拉的做法就是把2D的视觉信号投射进一个虚拟世界中进行重塑,并转换为数字空间信号。
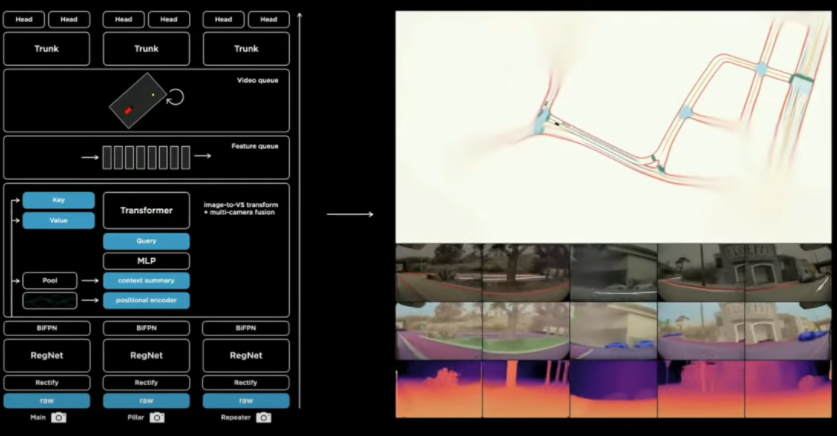
在特斯拉的视觉方案中,完成从视觉信号到数字空间信号转换的,就是一个名为HydraNets的神经网络模型。我觉得它这个名字的创意应该来自电影《美国队长》的九头蛇组织。
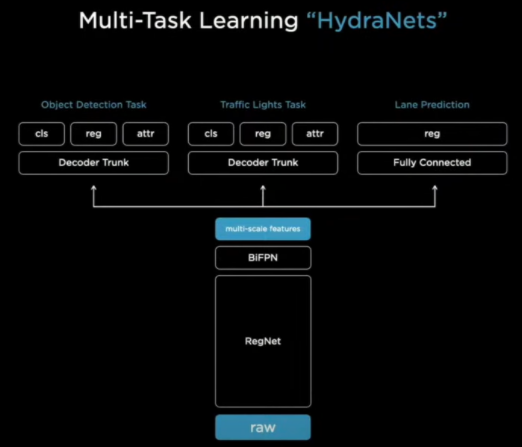
这个系统由一个Backbone和多个处理不同任务的头部组成,系统的主要输入就是特斯拉车上八个不同位置的摄像头,当视频图像进入这个系统后,首先要通过一个修正功能。
修正功能对每个摄像头拍到的视频进行调整,因为每台车的摄像头拍摄的位置和指向的角度都会有略微的不同,为了避免这种个体差异对图像学习所造成的干扰。
特斯拉的做法就是把每个位置的图像投射到位置固定的虚拟摄像头上,有点仿生学的意思了,不管眼球怎么动,大脑都会对收到的画面进行脑补,看起来就像是从同一个出发点看到的。
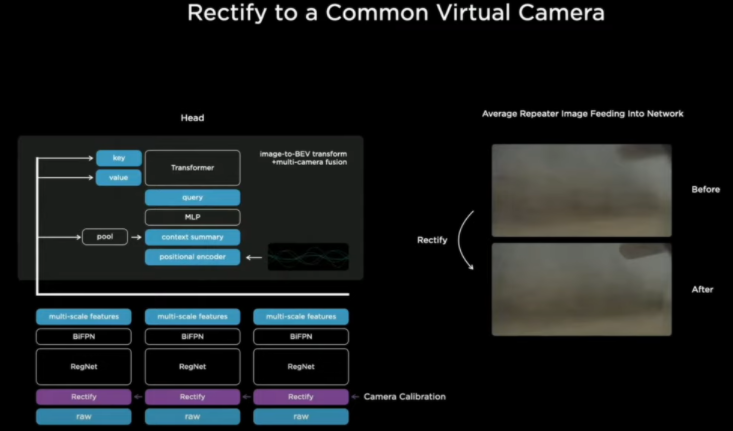
接下来修正过的图像就正式进入转化为数字空间信号的第一步:特征提取。
特斯拉在特征提取的时候使用了残差网络-RegNet架构,(这里简单介绍一下残差网络,这是2012年由微软亚洲研究院专为视觉分析搞出来的,基本上是视觉处理的万金油,几乎对所有视觉任务都有效,而且属于模块化架构)。
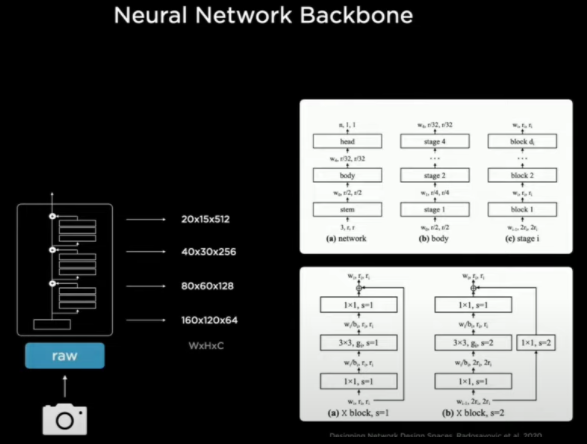
特斯拉使用的Reg-Net将图像转换为大小不同的特征图,这些特征图代表了对局部和全局分别的学习,然后就进入了下一步,特征融合。
在特征融合中,特斯拉采用了谷歌搞出来的双向特征金字塔,这个设计主要是加强对不同大小特征图的整体理解,对识别只有几个像素的小物体十分有效,而且也是一个模块化的架构。
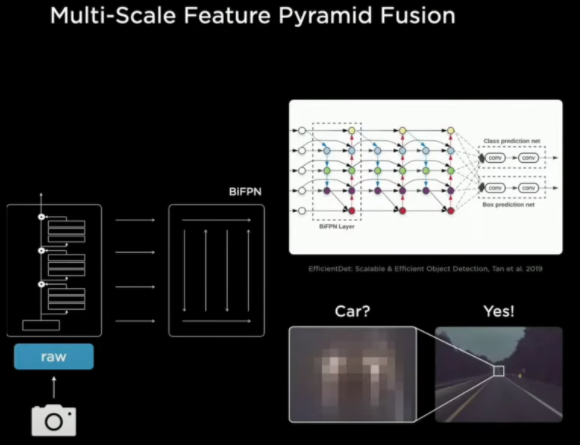
到这里,摄像头所看到的路标,路上的其他车辆,还有行人之类的视觉信号,就都被一大堆高维的数字信号所代替,准备进入数字化的虚拟空间。
但是在这之前还有一个问题,特斯拉车身上有8个摄像头,如果一个物体同时被多个摄像头看到要怎么处理,或者是一个物体从一个摄像头的视野进入另外一个摄像头的视野时应该怎么进行追踪。

还有一个很重要的问题,就是使用单个摄像头进行距离的估测很不准确。为了做到对每个像素进行更精准的距离估测,就需要多个摄像头的协作。对于上述这些问题,特斯拉做法是先把八个摄像头所看到的特征进行融合,然后再投入到虚拟空间,用来完成八个摄像头特征融合的任务,就交给了transformer这个网络的编码器结构。
Transformer是Google在17年的时候发表的论文《Attention Is All You Need》里提出的一种完全基于注意力机制的网络架构。它也是一种Seq-Seq模型,有一个Encoder和Decoder。我一开始理解的是特斯拉通过transformer的自注意力机制,来对时间线进行融合和学习,但是我发现我格局小了,我在第一层,特斯拉在第七层。
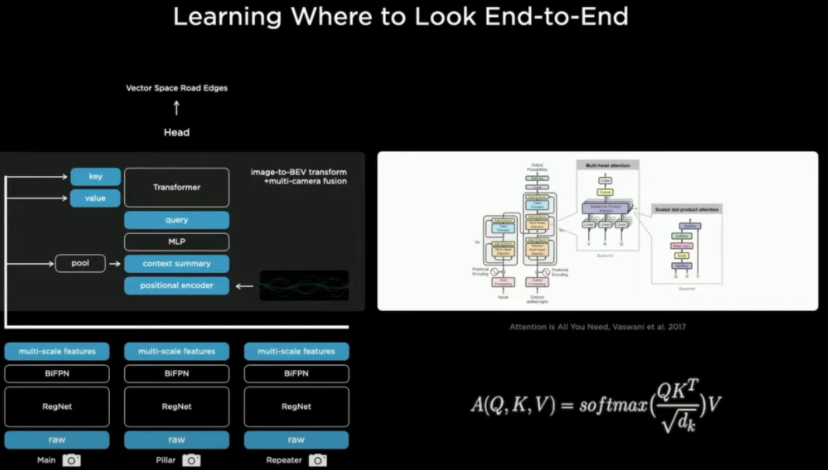
Transformer自注意力机制的本质,实际上是对空间信息的学习,只有当这些空间信息有先后顺序的时候,自注意力机制和提取到的信息,他会有时间特征的体现,而特斯拉AI团队在这儿利用自注意力机制,结合摄像头的位置信息,对每个摄像头所看到的特征进行了交叉学习,真正做到了把八个摄像头的信息编织成了一个完整的360度,并且高度压缩和抽象的信息整合。
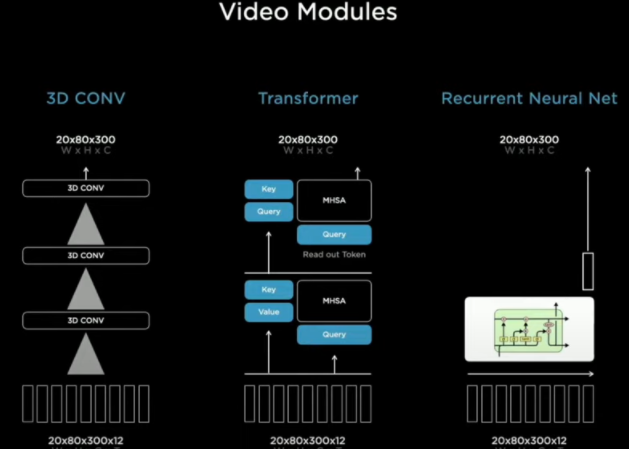
在这之后呢,才开始把时间线加进来,对连续的视频进行学习,毕竟到这一步,八个摄像头的整合信息也只包含一个时间点,也就是一帧,特斯拉的摄像头,每秒要拍摄36帧的画面,对时间线进行学习不仅仅在于可以对周围路况的变化进行追踪,更重要的是可以产生类似于上下文的记忆。
为什么需要上下文记忆呢?举个例子。
比如我们在路口等着迎面而来的车转向,结果有另外一台车从面前驶过,短暂地挡住了视线,此时刚才在等着转向的那台车不会因为你看不见而就此消失,这个上下文的记忆就可以帮助计算机估测,刚才那辆要转向的车估计已经挪地方了,根据之前观测到的行驶轨迹和速度,这车应该会出现在你的正前方,现在最好的策略就是原地不动,等着挡住你视线的车开走带。
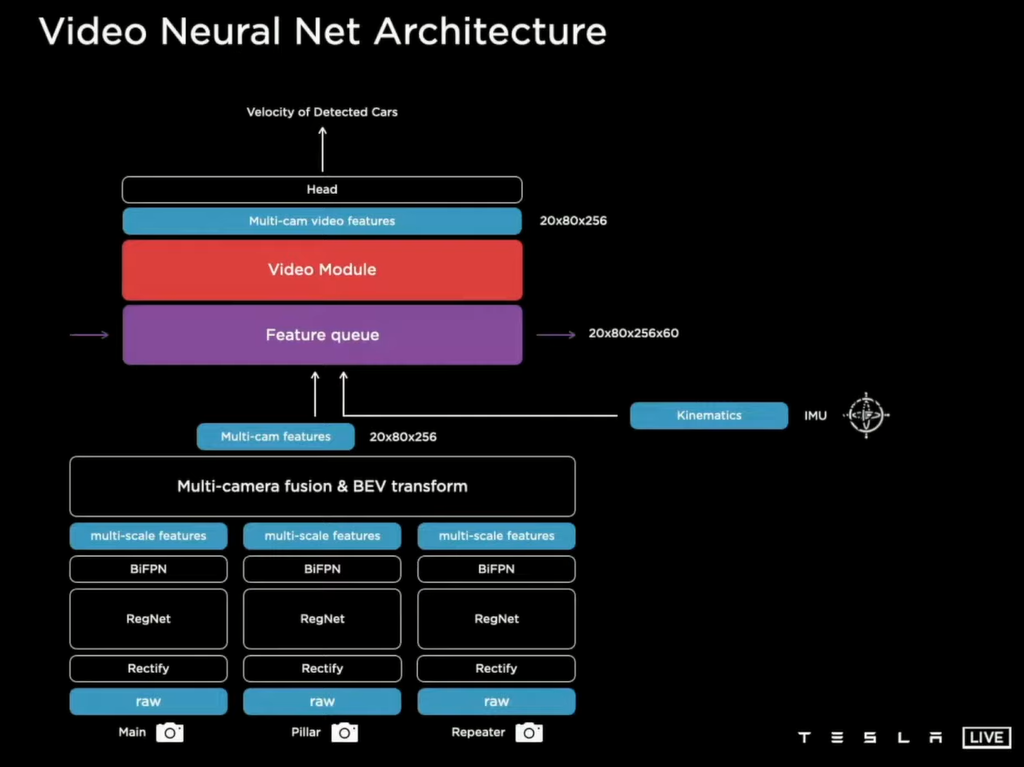
特斯拉在融合时间线的做法呢,是使用队列的概念,建立了两个缓存,一个针对空间,一个用于时间上下文的积累,用于针对时间的队列没27毫秒一更新,并以1.6秒为一个记忆单位来对信息进行打包,发送给下一个神经网络,来学习具有记忆效果的上下文。完成这项工作的就是一个大名鼎鼎的循环神经网络——LSTM。
至此,从2D图像信号到数字空间信号的转换得以完成,得到了呢是一堆有关路况、车况,高度抽象的,只有计算机才看得懂的数字。
计算机可以对这些数字进行学习,并把学到信息在低纬空间中重塑,就要通过解决不同任务的头部网络来实现,这些头部网络有做个体分割的,来识别哪里是路,哪里是沟,也有多物体识别和分析的,比如说识别路上的其它车辆以及行车的方向和速度是多少,还有专门用来盯着红绿灯的,由这些头部网络重塑信息所组成的对路况、车况每时每刻的状态描述,就可以交给决策系统来决定这车要怎么开了。
总的来说,在视觉感知的架构上,特斯拉对于比较新的技巧,敢上也敢用,它的神经网络上并不是一味的追求大,所做出的的选择都比较稳健,大有大的章法,要充分利用资源。
Planning and Control
好啦,聊完了视觉感知,咱们接着说说决策系统。按照Tesla的说法,他们在行车轨迹的决策系统上做了不少的尝试。
从实验效果来看,使用经典的启发式算法,比如A*算法来做行车判定很不靠谱,容易卡在局部最优解,浪费大量的试错也不好优化。
特斯拉的做法呢,是使用蒙特卡洛树搜索,结合神经网络来进行行车的决策。
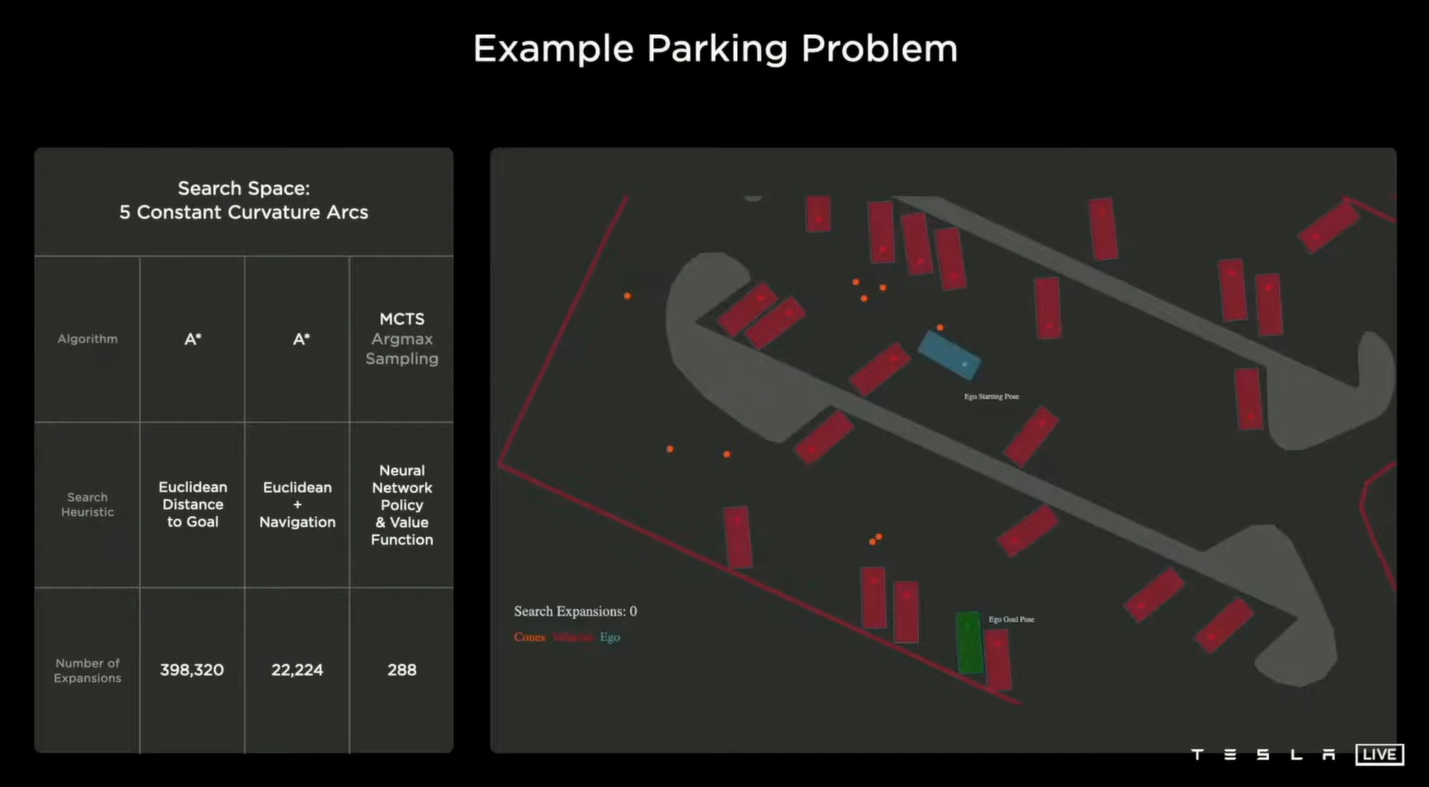
咱们先来说说蒙特卡洛树搜索,这个算法的名声啊很大,主要是因为谷歌当年在围棋人机大战中称王称霸的AlphaGo,就是基于这个算法的。算法的原理也很直白,就是根据当前一直的状态,在有限的时间和资源下,尽可能简单的模拟出各种可能的解决方法,并做出一个最符合要求的行动,来改变当前的状态,然后再次重新模拟。
有那么点儿高手比武,虽然两人都没动,但是在一年中已经相互过招无数,最后一招定输赢意思。
当年谷歌在AlphaGo上设计的精髓,在特斯拉的决策系统中得到了很好的体现,就是不做模拟,直接使用一个神经网络来估计在不同行驶状态下,各种驾驶决策有可能导致的结果,提供给蒙特卡洛树搜索来做选择。
而这个神经网络呢,我认为就是通过对人类驾驶行为进行模拟学习所得来的,Tesla也给出了蒙特卡洛树搜索在做选择时的要求和例子,那就是:① 安全性,有没有可能撞到东西,② 舒适性,系统所做的选择会不会突然加速或者减速而导致乘客不适,③ 效率,你可以开的很安全,也很舒适,但是开的的太慢,这也得加紧考虑。
以这三点为准则,特斯拉的决策系统以每秒166万次的效率,不停地推算最佳的驾驶行为和行车轨迹。
我之前说特斯拉的视觉系统在对行为的追踪和预测上下了不少功夫,对识别出的物体进行了更深层的分析和语义加长,比如说路上其他车辆的行车方向、速度,学习这些信息的优势就在系统进行行车决策时显示的出来,因为特斯拉以蒙特卡洛树搜索为基础的决策系统,不仅仅用在本车Ego Car的行为决策上,同时还用在路上其他车辆上来预测这些车辆有可能采取的驾驶行为,形成了一个本车和其他车辆不停博弈的系统。
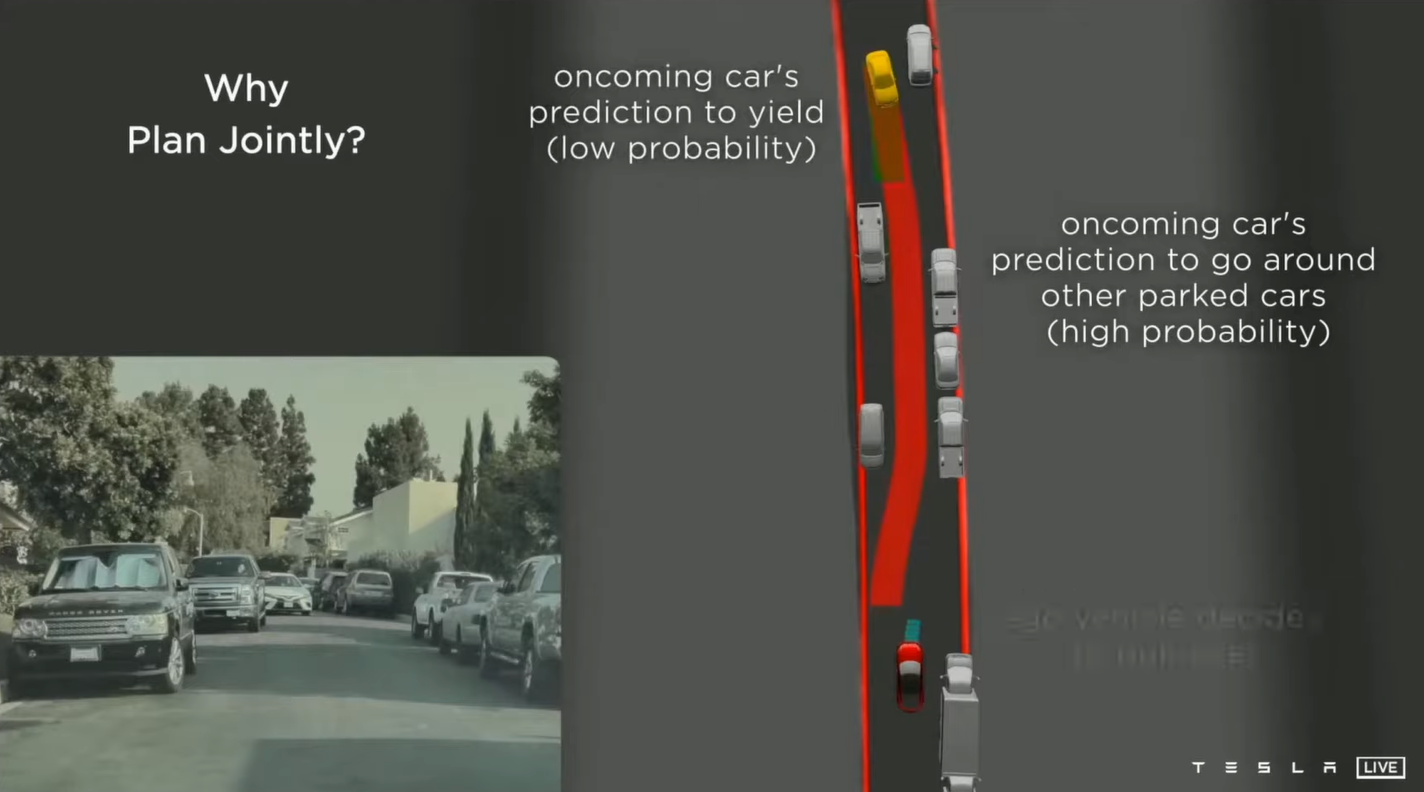
当然呢,这样系统的有效性呢是基于特斯拉通过模拟学习来的神经网络,见过足够多的人类驾驶行为。如果哪天你碰到个路子野的,不按常理驾驶的,那特斯拉的系统也没办法,毕竟人类的优势就在于可以通过对经验的泛化而创造出所谓的应变,这也是人工智能暂时没法比拟的。
Tesla的解决方案就是尽可能高效的收集和学习不同的路面情况和驾驶行为,说到这儿,就不得不提一下Tesla对数据的收集和标注
Auto Labeling
根据AI Day的介绍,特斯拉拥有自己的标注团队,最多时有上千人,但还是没有办法有效地处理Tesla所收集的海量数据,以及在数字模拟空间中进行标注的需求,这就迫使特斯拉开发工具和流程来实现自动信息标注——Auto Labeling。
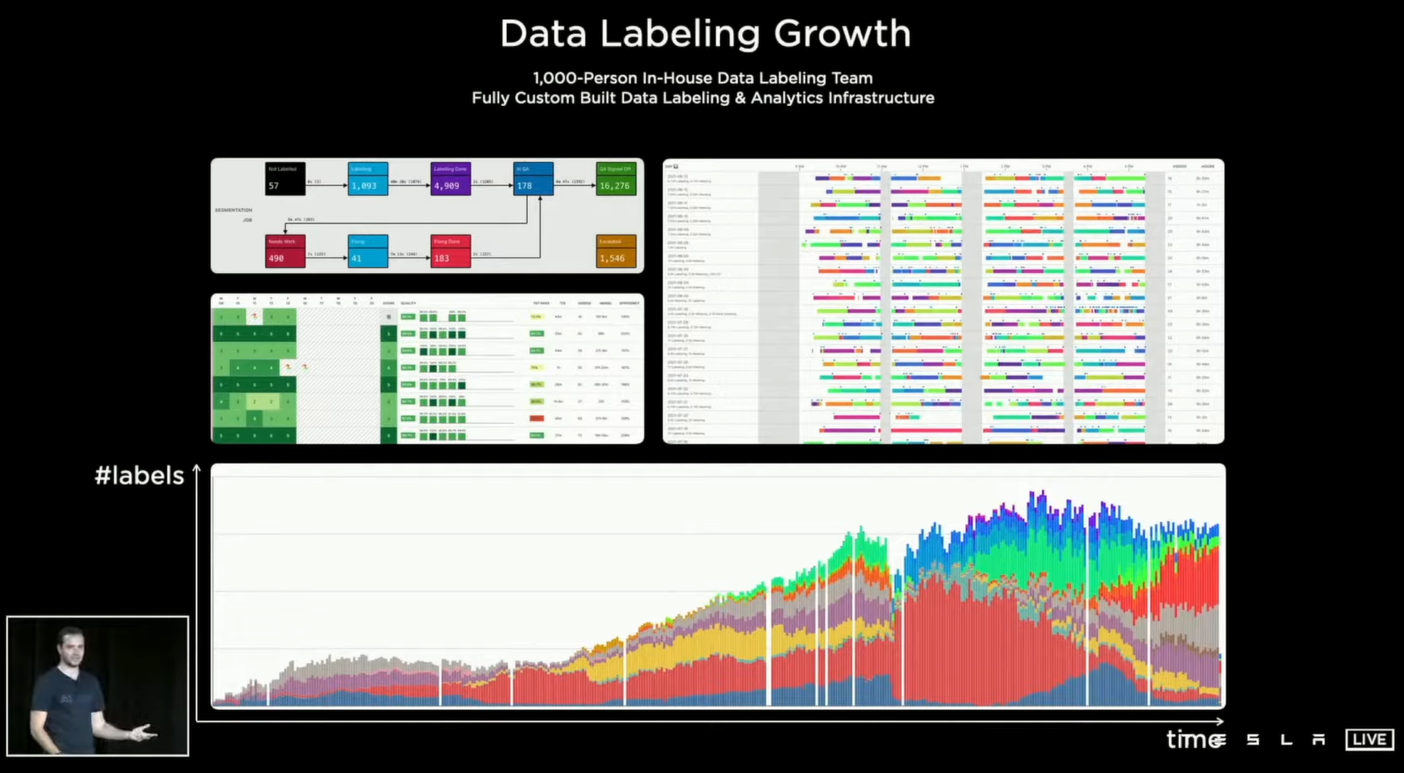
Tesla采用了自监督的方法,举个例子,就是一个20秒的行车视频,对前十秒学习来预测后十秒,然后用预测出来的后十秒和视频中原片的后十秒做对比,预测对了没奖励,预测错了就重来。
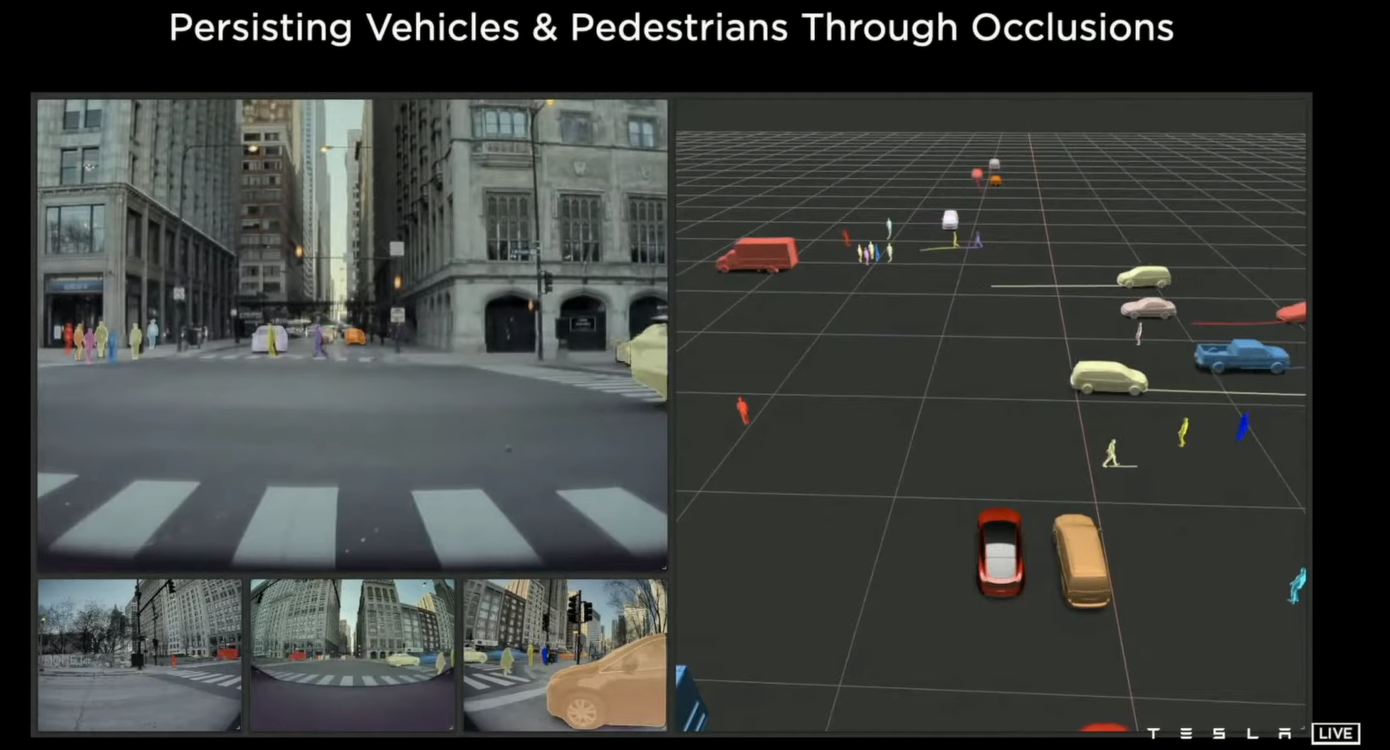
另一个技巧是特斯拉把视觉感知系统在虚拟空间中重塑的场景,和现实的视频图像一起交给以2D图像为基础的视觉分类的网络来做对比,有那么点儿生成对抗网络的意思。
Simulation
除了现实的行车视频,Tesla还大量使用了类似于游戏的模拟器,一是用来生成比较罕见的路况,比如有人带着狗在高速路上奔跑的情况,更主要是用来对现实的行车视频进行修改,生成新的路况来对视觉和角色系统进行更全面的测试

Dojo
说到测试,特斯拉也是十分的谨慎,搭建了有三千多台全自动驾驶FSD电脑所组成的集群,来对每一次在软件系统上的改动进行每周100万次的测试和评估。
为了支持自动标注、模拟和训练神经网络所需要的庞大运算,特斯拉目前的电脑集群拥有超过1万个GPU,然而还是不能满足特斯拉的需求。
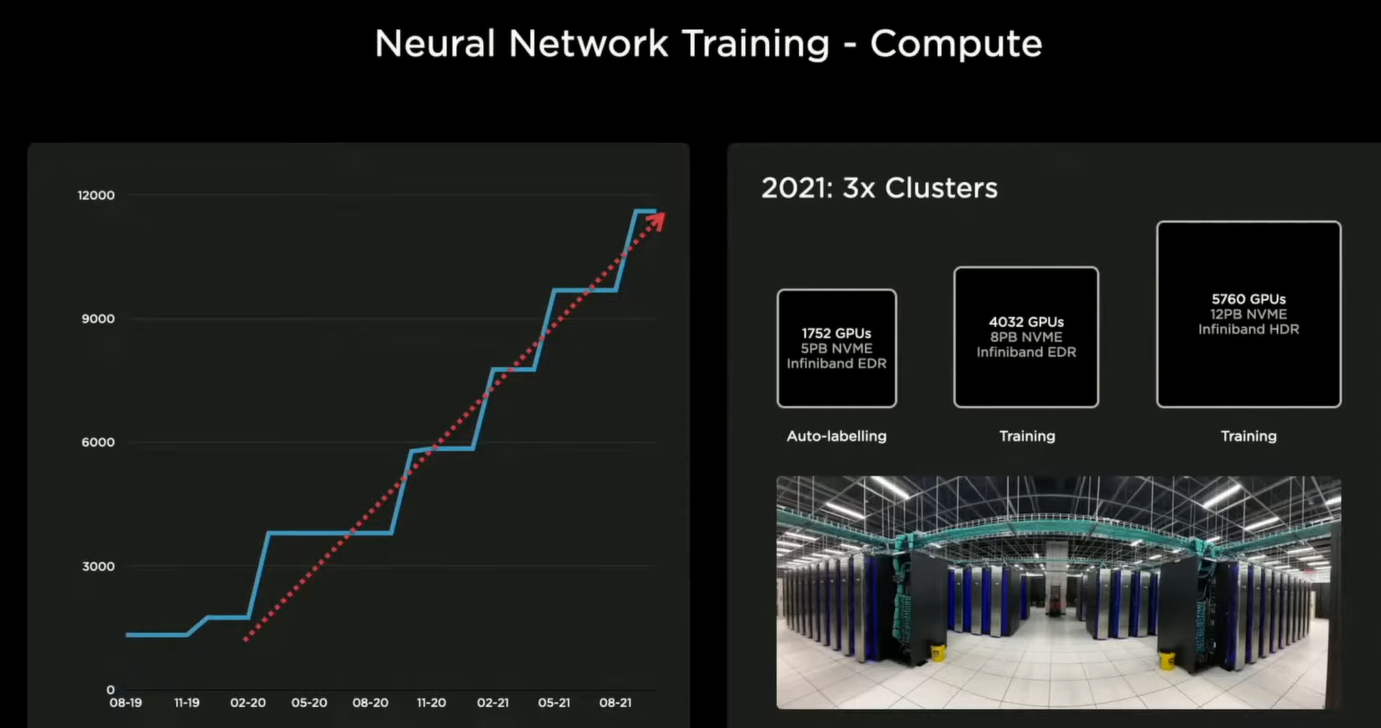
这也就是为什么Tesla要设计和开发Dojo 道场芯片。
Dojo的发布颠覆了很多搞硬件的世界观,和之前外界猜测的一样,Dojo采用分布式的计算架构,最大的技术突破不在于单块Dojo的算力,而是决定数据吞吐能力的带宽。
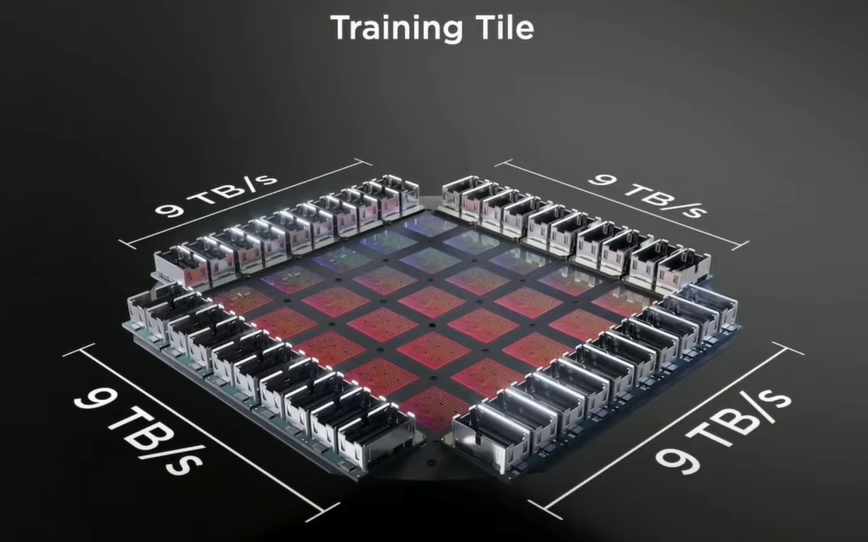
特斯拉很清楚地认识到,真正的系统瓶颈不是算力,而是通讯带宽,尤其是分布式架构中芯片之间的通讯。按照特斯拉的说法,Dojo模块之间的通信带宽是现在最好的网络中继芯片数据吞吐能力的两倍,在这样的硬件能力之上,特斯拉又再一次强调了自主设计Dojo来实现从程序编译器到芯片架构的垂直整合所带来的优势,就是在同等价位的产品中,特斯拉的Dojo系统性能是同行的四倍,并且更加的节能和节省空间。
一个比较有意思的细节啊,就是按照AI Day的展示,Dojo系统的设计,可以对并行的计算模块进行分区,从而把一个神经网络的训练加载到不同的区间进行,来达到资源利用最大化。
在AI Day活动后半段的问答时间里,现场有人问到特斯拉是如何解决程序编译器在分布式计算上的一些挑战的时候,特斯拉团队的回答呢也很诚恳,就是在解决这些问题上,特斯拉团队已经有了明确的思路,但是具体的实现呢还是在路上的状态,这也就体现了AI的另一个目的,就是招募在硬件、软件方面的能人,来帮助特斯拉实现普及AI应用的目标,对于特斯拉来说,这个目标现阶段的课题就是全自动驾驶。
Tesla Bot
关于Tesla Bot其实在AI Day之前就埋下了伏笔,当UCLA大学搞机器人开发的Dennis Hong教授在推特上放出Dojo 道场芯片设计图的时候,大家就猜测过:特斯拉是不是要在机器人方面有什么动作?

结果呢,我想大家都已经知道了,就是特斯拉宣布要开发和生产人形机器人Tesla Bot。
特斯拉把这个拿出来:
- 是为了设定更高,更有挑战的目标,毕竟人性机器人很多公司都在搞,但是能大规模应用来代替人类劳动力的,目前还没有;
- 是可以吸引大众的注意力,AI Day作为一个比较冷门儿的活动,怎么才能更好地为特斯拉做宣传,并且能把非专业人士也带进来一起玩儿呢?我想没有什么比发布一个充满未来感的人形机器人更让人激动的了。
参考文献:
純視覺不靠譜?你能聽懂的特斯拉人工智能自動駕駛解密上集!全網最細緻!TESLA AI DAY EXPLAINED
簡單看懂AI Day|特斯拉人形機器人Tesla Bot 馬斯克超前部署的一步棋
特斯拉火力展示! 最強超級電腦Dojo D1晶片,FSD自動駕駛背後怎麼運作的?第二代FSD明年上線? Tesla 機器人,科幻電影將成真?
最后
以上就是酷酷洋葱最近收集整理的关于Tesla AI Day:特斯拉如何实现自动驾驶的详解参考文献:的全部内容,更多相关Tesla内容请搜索靠谱客的其他文章。








发表评论 取消回复