本篇文章给大家带来了关于python的相关知识,其中主要介绍了关于多进程的相关内容,包括了什么是多进程、进程的创建、进程间同步、进程池等等,下面一起来看一下,希望对大家有帮助。

推荐学习:python视频教程
一、什么是多进程?
1. 进程
程序:例如xxx.py这是程序,是一个静态的
进程:一个程序运行起来后,代码+用到的资源 称之为进程,它是操作系统分配资源的基本单元。不仅可以通过线程完成多任务,进程也是可以的
2. 进程的状态
工作中,任务数往往大于cpu的核数,即一定有一些任务正在执行,而另外一些任务在等待cpu进行执行,因此导致了有了不同的状态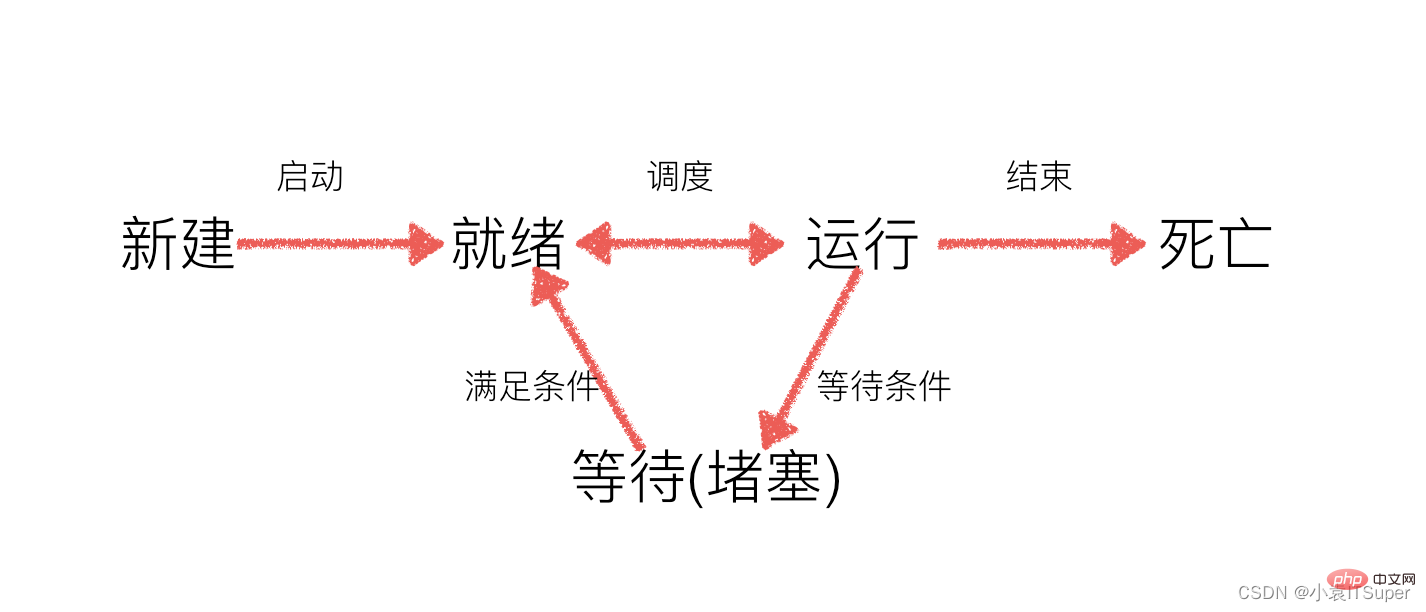
- 就绪态:运行的条件都已经慢去,正在等在cpu执行
- 执行态:cpu正在执行其功能
- 等待态:等待某些条件满足,例如一个程序sleep了,此时就处于等待态
二、进程的创建-multiprocessing
1. Process类语法说明
语法格式:multiprocessing.Process(group=None, target=None, name=None, args=(), kwargs={}, *, daemon=None)
参数说明:
group:指定进程组,大多数情况下用不到target:如果传递了函数的引用,可以任务这个子进程就执行这里的代码name:给进程设定一个名字,可以不设定args:给target指定的函数传递的参数,以元组的方式传递kwargs:给target指定的函数传递命名参数
multiprocessing.Process 对象具有如下方法和属性:
| 方法名/属性 | 说明 |
|---|---|
run() | 进程具体执行的方法 |
start() | 启动子进程实例(创建子进程) |
join([timeout]) | 如果可选参数 timeout 是默认值 None,则将阻塞至调用 join() 方法的进程终止;如果 timeout 是一个正数,则最多会阻塞 timeout 秒 |
name | 当前进程的别名,默认为Process-N,N为从1开始递增的整数 |
pid | 当前进程的pid(进程号) |
is_alive() | 判断进程子进程是否还在活着 |
exitcode | 子进程的退出代码 |
daemon | 进程的守护标志,是一个布尔值。 |
authkey | 进程的身份验证密钥。 |
sentinel | 系统对象的数字句柄,当进程结束时将变为 ready。 |
terminate() | 不管任务是否完成,立即终止子进程 |
kill() | 与 terminate() 相同,但在 Unix 上使用 SIGKILL 信号。 |
close() | 关闭 Process 对象,释放与之关联的所有资源 |
2. 2个while循环一起执行
# -*- coding:utf-8 -*-from multiprocessing import Processimport timedef run_proc():
"""子进程要执行的代码"""
while True:
print("----2----")
time.sleep(1)if __name__=='__main__':
p = Process(target=run_proc)
p.start()
while True:
print("----1----")
time.sleep(1)登录后复制运行结果: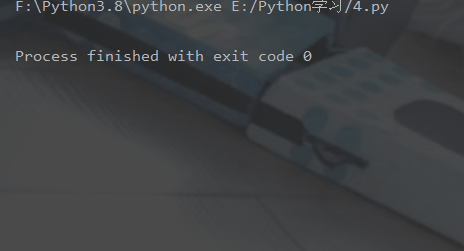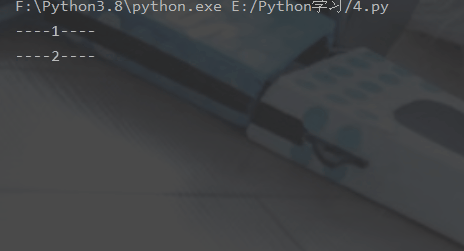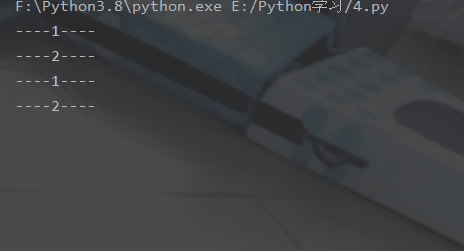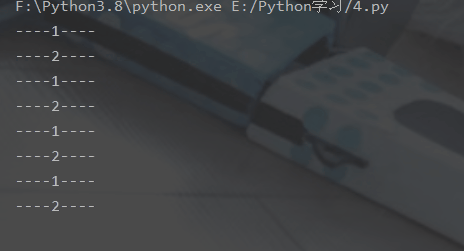
说明:创建子进程时,只需要传入一个执行函数和函数的参数,创建一个Process实例,用start()方法启动
3. 进程pid
# -*- coding:utf-8 -*-from multiprocessing import Processimport osimport timedef run_proc():
"""子进程要执行的代码"""
print('子进程运行中,pid=%d...' % os.getpid()) # os.getpid获取当前进程的进程号
print('子进程将要结束...')if __name__ == '__main__':
print('父进程pid: %d' % os.getpid()) # os.getpid获取当前进程的进程号
p = Process(target=run_proc)
p.start()登录后复制运行结果: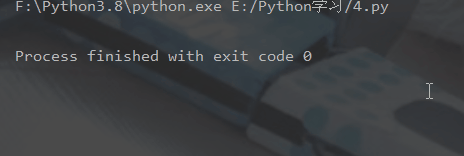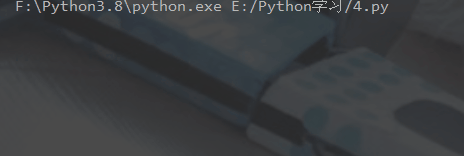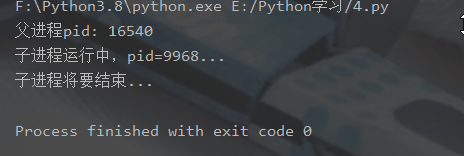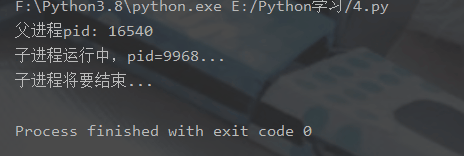
4. 给子进程指定的函数传递参数
# -*- coding:utf-8 -*-from multiprocessing import Processimport osfrom time import sleepdef run_proc(name, age, **kwargs):
for i in range(10):
print('子进程运行中,name= %s,age=%d ,pid=%d...' % (name, age, os.getpid()))
print(kwargs)
sleep(0.2)if __name__=='__main__':
p = Process(target=run_proc, args=('test',18), kwargs={"m":20})
p.start()
sleep(1) # 1秒中之后,立即结束子进程
p.terminate()
p.join()登录后复制运行结果:
5. 进程间不同享全局变量
# -*- coding:utf-8 -*-from multiprocessing import Processimport osimport time
nums = [11, 22]def work1():
"""子进程要执行的代码"""
print("in process1 pid=%d ,nums=%s" % (os.getpid(), nums))
for i in range(3):
nums.append(i)
time.sleep(1)
print("in process1 pid=%d ,nums=%s" % (os.getpid(), nums))def work2():
"""子进程要执行的代码"""
print("in process2 pid=%d ,nums=%s" % (os.getpid(), nums))if __name__ == '__main__':
p1 = Process(target=work1)
p1.start()
p1.join()
p2 = Process(target=work2)
p2.start()登录后复制运行结果:
in process1 pid=11349 ,nums=[11, 22]in process1 pid=11349 ,nums=[11, 22, 0]in process1 pid=11349 ,
nums=[11, 22, 0, 1]in process1 pid=11349 ,nums=[11, 22, 0, 1, 2]in process2 pid=11350 ,nums=[11, 22]
登录后复制三、进程间同步-Queue
1. Queue类语法说明
| 方法名 | 说明 |
|---|---|
q=Queue() | 初始化Queue()对象,若括号中没有指定最大可接收的消息数量,或数量为负值,那么就代表可接受的消息数量没有上限(直到内存的尽头) |
Queue.qsize() | 返回当前队列包含的消息数量 |
Queue.empty() | 如果队列为空,返回True,反之False |
Queue.full() | 如果队列满了,返回True,反之False |
Queue.get([block[, timeout]]) | 获取队列中的一条消息,然后将其从列队中移除,block默认值为True。1、如果block使用默认值,且没有设置timeout(单位秒),消息列队如果为空,此时程序将被阻塞(停在读取状态),直到从消息列队读到消息为止,如果设置了timeout,则会等待timeout秒,若还没读取到任何消息,则抛出"Queue.Empty"异常。2、如果block值为False,消息列队如果为空,则会立刻抛出"Queue.Empty"异常 |
Queue.get_nowait() | 相当Queue.get(False) |
Queue.put(item,[block[, timeout]]) | 将item消息写入队列,block默认值为True。1、如果block使用默认值,且没有设置timeout(单位秒),消息列队如果已经没有空间可写入,此时程序将被阻塞(停在写入状态),直到从消息列队腾出空间为止,如果设置了timeout,则会等待timeout秒,若还没空间,则抛出"Queue.Full"异常。 2、如果block值为False,消息列队如果没有空间可写入,则会立刻抛出"Queue.Full"异常 |
Queue.put_nowait(item) | 相当Queue.put(item, False) |
2. Queue的使用
可以使用multiprocessing模块的Queue实现多进程之间的数据传递,Queue本身是一个消息列队程序,首先用一个小实例来演示一下Queue的工作原理:
#coding=utf-8from multiprocessing import Queue
q=Queue(3) #初始化一个Queue对象,最多可接收三条put消息q.put("消息1") q.put("消息2")print(q.full()) #Falseq.put("消息3")print(q.full()) #True#因为消息列队已满下面的try都会抛出异常,第一个try会等待2秒后再抛出异常,第二个Try会立刻抛出异常try:
q.put("消息4",True,2)except:
print("消息列队已满,现有消息数量:%s"%q.qsize())try:
q.put_nowait("消息4")except:
print("消息列队已满,现有消息数量:%s"%q.qsize())#推荐的方式,先判断消息列队是否已满,再写入if not q.full():
q.put_nowait("消息4")#读取消息时,先判断消息列队是否为空,再读取if not q.empty():
for i in range(q.qsize()):
print(q.get_nowait())登录后复制运行结果:
FalseTrue消息列队已满,现有消息数量:3消息列队已满,现有消息数量:3消息1消息2消息3
登录后复制3. Queue实例
我们以Queue为例,在父进程中创建两个子进程,一个往Queue里写数据,一个从Queue里读数据:
from multiprocessing import Process, Queueimport os, time, random# 写数据进程执行的代码:def write(q):
for value in ['A', 'B', 'C']:
print('Put %s to queue...' % value)
q.put(value)
time.sleep(random.random())# 读数据进程执行的代码:def read(q):
while True:
if not q.empty():
value = q.get(True)
print('Get %s from queue.' % value)
time.sleep(random.random())
else:
breakif __name__=='__main__':
# 父进程创建Queue,并传给各个子进程:
q = Queue()
pw = Process(target=write, args=(q,))
pr = Process(target=read, args=(q,))
# 启动子进程pw,写入:
pw.start()
# 等待pw结束:
pw.join()
# 启动子进程pr,读取:
pr.start()
pr.join()
# pr进程里是死循环,无法等待其结束,只能强行终止:
print('')
print('所有数据都写入并且读完')登录后复制运行结果: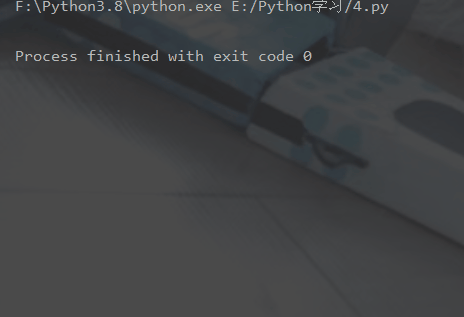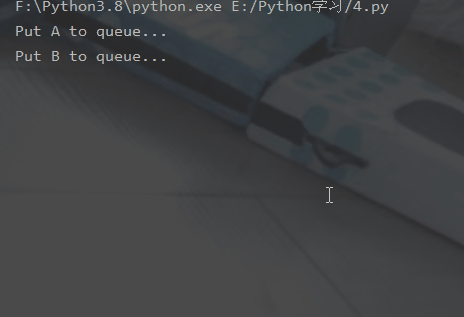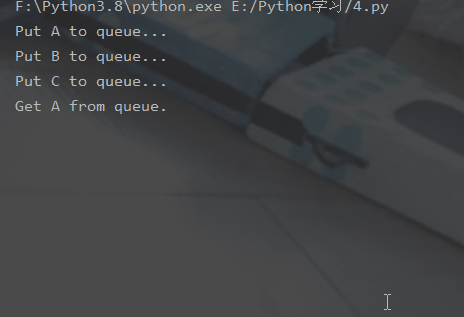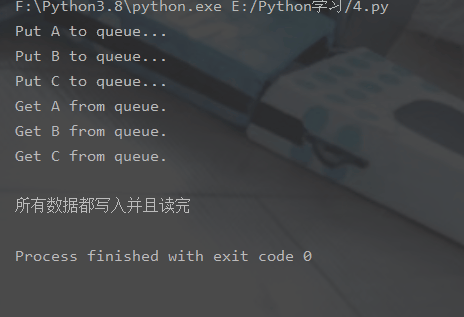
四、进程间同步-Lock
1. Lock的语法说明:
lock = multiprocessing.Lock(): 创建一个锁lock.acquire():获取锁lock.release():释放锁with lock:自动获取、释放锁 类似于 with open() as f:
2. 程序不加锁时:
import multiprocessingimport timedef add(num, value):
print('add{0}:num={1}'.format(value, num))
for i in range(0, 2):
num += value print('add{0}:num={1}'.format(value, num))
time.sleep(1)if __name__ == '__main__':
lock = multiprocessing.Lock()
num = 0
p1 = multiprocessing.Process(target=add, args=(num, 1))
p2 = multiprocessing.Process(target=add, args=(num, 2))
p1.start()
p2.start()登录后复制运行结果:运得没有顺序,两个进程交替运行
add1:num=0add1:num=1add2:num=0add2:num=2add1:num=2add2:num=4
登录后复制3. 程序加锁时:
import multiprocessingimport timedef add(num, value, lock):
try:
lock.acquire()
print('add{0}:num={1}'.format(value, num))
for i in range(0, 2):
num += value print('add{0}:num={1}'.format(value, num))
time.sleep(1)
except Exception as err:
raise err finally:
lock.release()if __name__ == '__main__':
lock = multiprocessing.Lock()
num = 0
p1 = multiprocessing.Process(target=add, args=(num, 1, lock))
p2 = multiprocessing.Process(target=add, args=(num, 2, lock))
p1.start()
p2.start()登录后复制运行结果:只有当其中一个进程执行完成后,其它的进程才会去执行,且谁先抢到锁谁先执行
add1:num=0add1:num=1add1:num=2add2:num=0add2:num=2add2:num=4
登录后复制五、进程池Pool
1. Pool类语法说明
语法格式:multiprocessing.pool.Pool([processes[, initializer[, initargs[, maxtasksperchild[, context]]]]])
参数说明:
processes:工作进程数目,如果 processes 为 None,则使用 os.cpu_count() 返回的值。initializer:如果 initializer 不为 None,则每个工作进程将会在启动时调用 initializer(*initargs)。maxtasksperchild:一个工作进程在它退出或被一个新的工作进程代替之前能完成的任务数量,为了释放未使用的资源。context:用于指定启动的工作进程的上下文。
两种方式向进程池提交任务:
apply(func[, args[, kwds]]):阻塞方式。apply_async(func[, args[, kwds]]):非阻塞方式。使用非阻塞方式调用func(并行执行,堵塞方式必须等待上一个进程退出才能执行下一个进程),args为传递给func的参数列表,kwds为传递给func的关键字参数列表
multiprocessing.Pool常用函数:
| 方法名 | 说明 |
|---|---|
close() | 关闭Pool,使其不再接受新的任务 |
terminate() | 不管任务是否完成,立即终止 |
join() | 主进程阻塞,等待子进程的退出, 必须在close或terminate之后使用 |
2. Pool实例
初始化Pool时,可以指定一个最大进程数,当有新的请求提交到Pool中时,如果池还没有满,那么就会创建一个新的进程用来执行该请求;但如果池中的进程数已经达到指定的最大值,那么该请求就会等待,直到池中有进程结束,才会用之前的进程来执行新的任务,请看下面的实例:
# -*- coding:utf-8 -*-from multiprocessing import Poolimport os, time, randomdef worker(msg):
t_start = time.time()
print("%s开始执行,进程号为%d" % (msg,os.getpid()))
# random.random()随机生成0~1之间的浮点数
time.sleep(random.random()*2)
t_stop = time.time()
print(msg,"执行完毕,耗时%0.2f" % (t_stop-t_start))po = Pool(3) # 定义一个进程池,最大进程数3for i in range(0,10):
# Pool().apply_async(要调用的目标,(传递给目标的参数元祖,))
# 每次循环将会用空闲出来的子进程去调用目标
po.apply_async(worker,(i,))print("----start----")po.close()
# 关闭进程池,关闭后po不再接收新的请求po.join()
# 等待po中所有子进程执行完成,必须放在close语句之后print("-----end-----")登录后复制运行结果:
----start----
0开始执行,进程号为21466
1开始执行,进程号为21468
2开始执行,进程号为21467
0 执行完毕,耗时1.01
3开始执行,进程号为21466
2 执行完毕,耗时1.24
4开始执行,进程号为21467
3 执行完毕,耗时0.56
5开始执行,进程号为21466
1 执行完毕,耗时1.68
6开始执行,进程号为21468
4 执行完毕,耗时0.67
7开始执行,进程号为21467
5 执行完毕,耗时0.83
8开始执行,进程号为21466
6 执行完毕,耗时0.75
9开始执行,进程号为21468
7 执行完毕,耗时1.03
8 执行完毕,耗时1.05
9 执行完毕,耗时1.69
-----end-----
登录后复制3. 进程池中的Queue
如果要使用Pool创建进程,就需要使用multiprocessing.Manager()中的Queue()
而不是multiprocessing.Queue(),否则会得到一条如下的错误信息:RuntimeError: Queue objects should only be shared between processes through inheritance.
下面的实例演示了进程池中的进程如何通信:
# -*- coding:utf-8 -*-# 修改import中的Queue为Managerfrom multiprocessing import Manager,Poolimport os,time,randomdef reader(q):
print("reader启动(%s),父进程为(%s)" % (os.getpid(), os.getppid()))
for i in range(q.qsize()):
print("reader从Queue获取到消息:%s" % q.get(True))def writer(q):
print("writer启动(%s),父进程为(%s)" % (os.getpid(), os.getppid()))
for i in "itcast":
q.put(i)if __name__=="__main__":
print("(%s) start" % os.getpid())
q = Manager().Queue() # 使用Manager中的Queue
po = Pool()
po.apply_async(writer, (q,))
time.sleep(1) # 先让上面的任务向Queue存入数据,然后再让下面的任务开始从中取数据
po.apply_async(reader, (q,))
po.close()
po.join()
print("(%s) End" % os.getpid())登录后复制运行结果:
(11095) start
writer启动(11097),父进程为(11095)reader启动(11098),父进程为(11095)reader从Queue获取到消息:i
reader从Queue获取到消息:t
reader从Queue获取到消息:c
reader从Queue获取到消息:a
reader从Queue获取到消息:s
reader从Queue获取到消息:t(11095) End
登录后复制六、进程、线程对比
1. 功能
进程:能够完成多任务,比如 在一台电脑上能够同时运行多个QQ
线程:能够完成多任务,比如 一个QQ中的多个聊天窗口
定义的不同
进程是系统进行资源分配和调度的一个独立单位.
线程是进程的一个实体,是CPU调度和分派的基本单位,它是比进程更小的能独立运行的基本单位.线程自己基本上不拥有系统资源,只拥有一点在运行中必不可少的资源(如程序计数器,一组寄存器和栈),但是它可与同属一个进程的其他的线程共享进程所拥有的全部资源.
2. 区别
- 一个程序至少有一个进程,一个进程至少有一个线程.
-线程的划分尺度小于进程(资源比进程少),使得多线程程序的并发性高。
-进程在执行过程中拥有独立的内存单元,而多个线程共享内存,从而极大地提高了程序的运行效率
- 线线程不能够独立执行,必须依存在进程中
- 可以将进程理解为工厂中的一条流水线,而其中的线程就是这个流水线上的工人
3. 优缺点
- 线程:线程执行开销小,但不利于资源的管理和保护
- 进程:进程执行开销大,但利于资源的管理和保护
推荐学习:python视频教程
以上就是Python多进程知识点总结的详细内容,更多请关注靠谱客其它相关文章!

最后
以上就是落寞纸鹤最近收集整理的关于Python多进程知识点总结的全部内容,更多相关Python多进程知识点总结内容请搜索靠谱客的其他文章。








发表评论 取消回复