
值得一看的Python高效数据处理
Pandas是Python中非常常用的数据处理工具,使用起来非常方便。它建立在NumPy数组结构之上,所以它的很多操作通过NumPy或者Pandas自带的扩展模块编写,这些模块用Cython编写并编译到C,并且在C上执行,因此也保证了处理速度。
今天我们就来体验一下它的强大之处。
1.创建数据
使用pandas可以很方便地进行数据创建,现在让我们创建一个5列1000行的pandas DataFrame:
mu1, sigma1 = 0, 0.1
mu2, sigma2 = 0.2, 0.2
n = 1000df = pd.DataFrame(
{
"a1": pd.np.random.normal(mu1, sigma1, n),
"a2": pd.np.random.normal(mu2, sigma2, n),
"a3": pd.np.random.randint(0, 5, n),
"y1": pd.np.logspace(0, 1, num=n),
"y2": pd.np.random.randint(0, 2, n),
}
)登录后复制- a1和a2:从正态(高斯)分布中抽取的随机样本。
- a3:0到4中的随机整数。
- y1:从0到1的对数刻度均匀分布。
- y2:0到1中的随机整数。
生成如下所示的数据:

2.绘制图像
Pandas 绘图函数返回一个matplotlib的坐标轴(Axes),所以我们可以在上面自定义绘制我们所需要的内容。比如说画一条垂线和平行线。这将非常有利于我们:
1.绘制平均线
2.标记重点的点
import matplotlib.pyplot as plt
ax = df.y1.plot()
ax.axhline(6, color="red", linestyle="--")
ax.axvline(775, color="red", linestyle="--")
plt.show()
登录后复制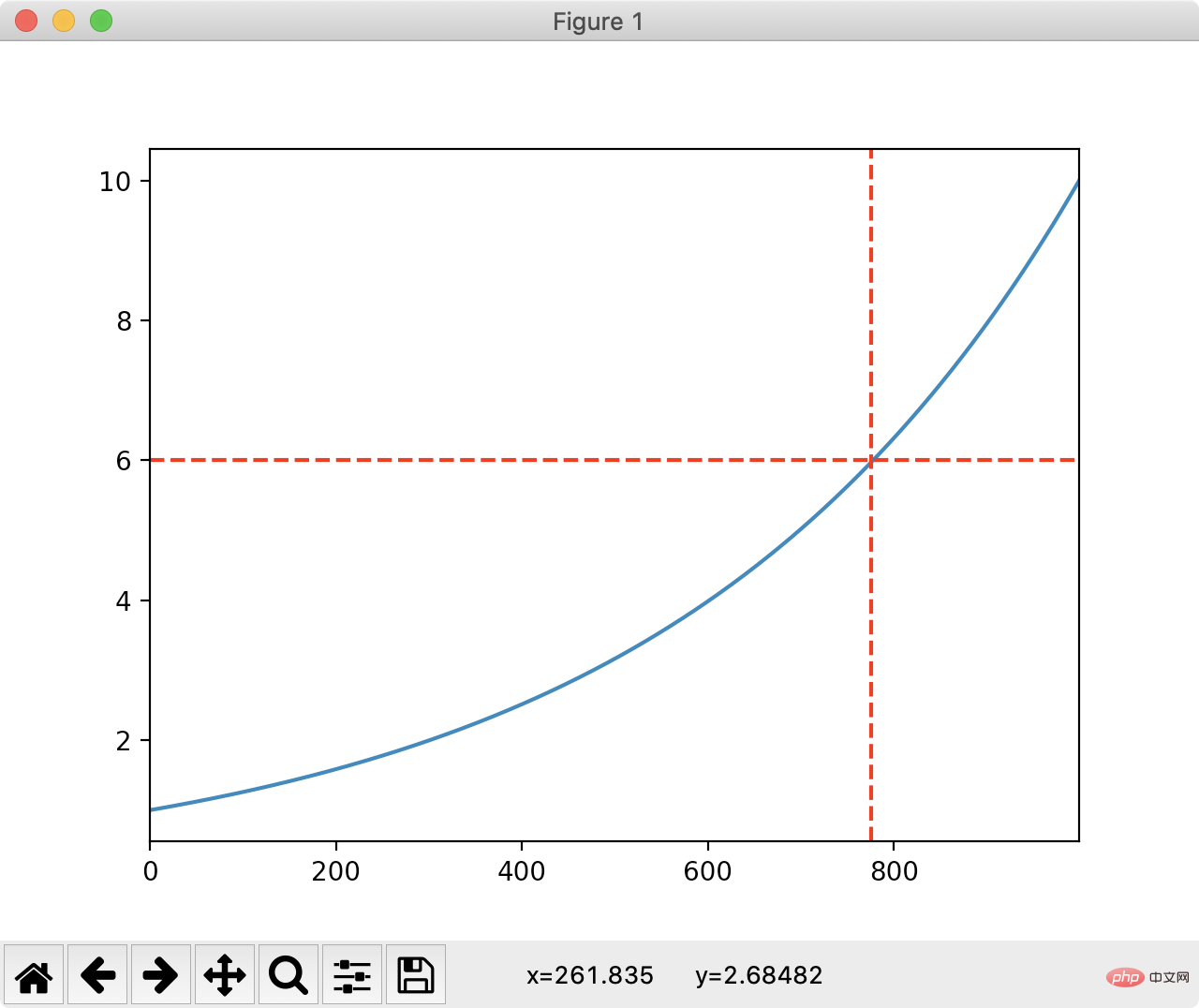
我们还可以自定义一张图上显示多少个表:
fig, ax = plt.subplots(2, 2, figsize=(14,7))
df.plot(x="index", y="y1", ax=ax[0, 0])
df.plot.scatter(x="index", y="y2", ax=ax[0, 1])
df.plot.scatter(x="index", y="a3", ax=ax[1, 0])
df.plot(x="index", y="a1", ax=ax[1, 1])
plt.show()
登录后复制
3.绘制直方图
Pandas能够让我们用非常简单的方式获得两个图形的形状对比:
df[["a1", "a2"]].plot(bins=30, kind="hist")
plt.show()
登录后复制
还能允许多图绘制:
df[["a1", "a2"]].plot(bins=30, kind="hist", subplots=True)
plt.show()
登录后复制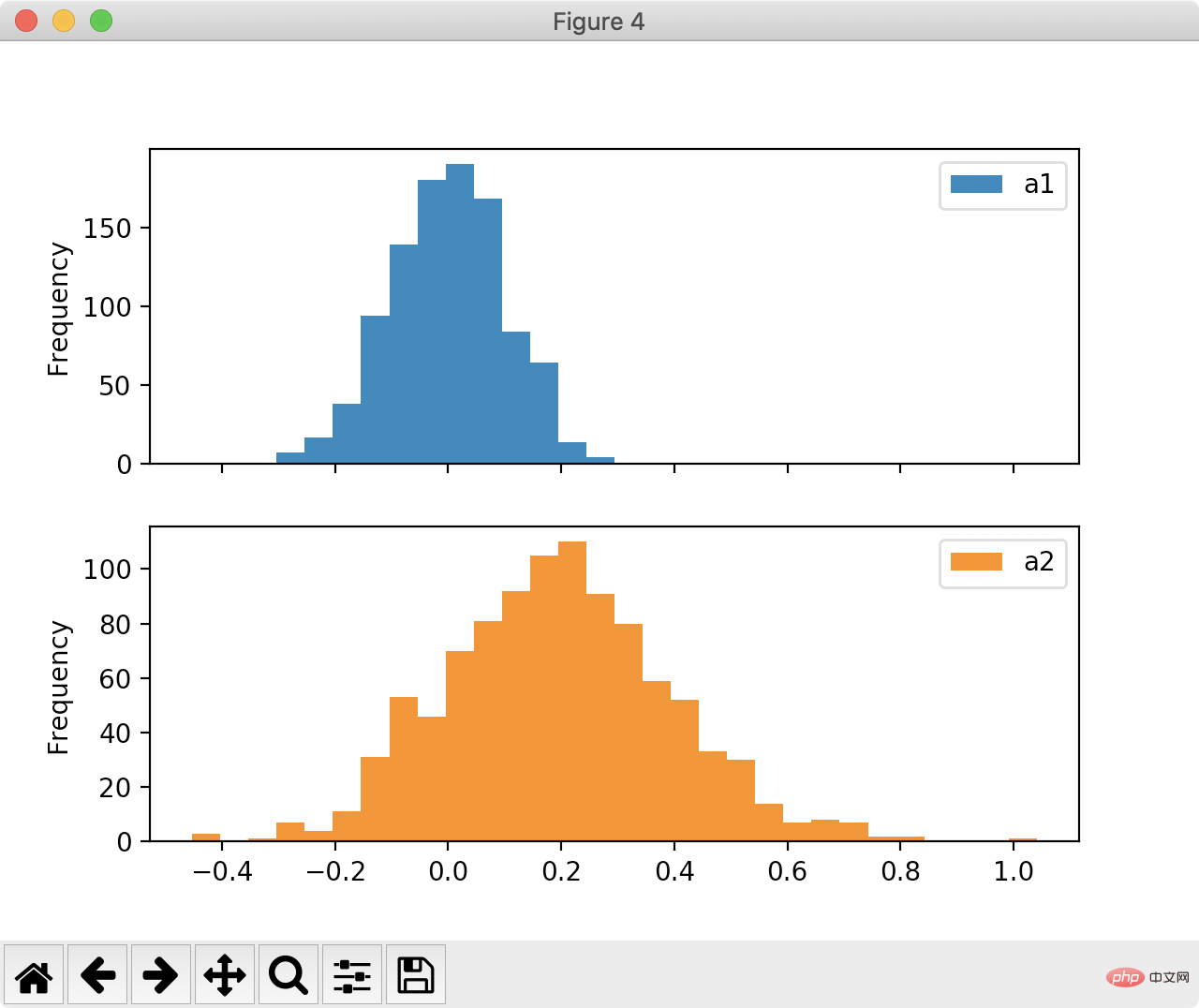
当然,生成折线图也不在画下:
df[['a1', 'a2']].plot(by=df.y2, subplots=True)
plt.show()
登录后复制
4.线性拟合
Pandas还能用于拟合,让我们用pandas找出一条与下图最接近的直线:

最小二乘法计算和该直线最短距离:
df['ones'] = pd.np.ones(len(df))
m, c = pd.np.linalg.lstsq(df[['index', 'ones']], df['y1'], rcond=None)[0]
登录后复制根据最小二乘的结果绘制y和拟合出来的直线:
df['y'] = df['index'].apply(lambda x: x * m + c)
df[['y', 'y1']].plot()
plt.show()
登录后复制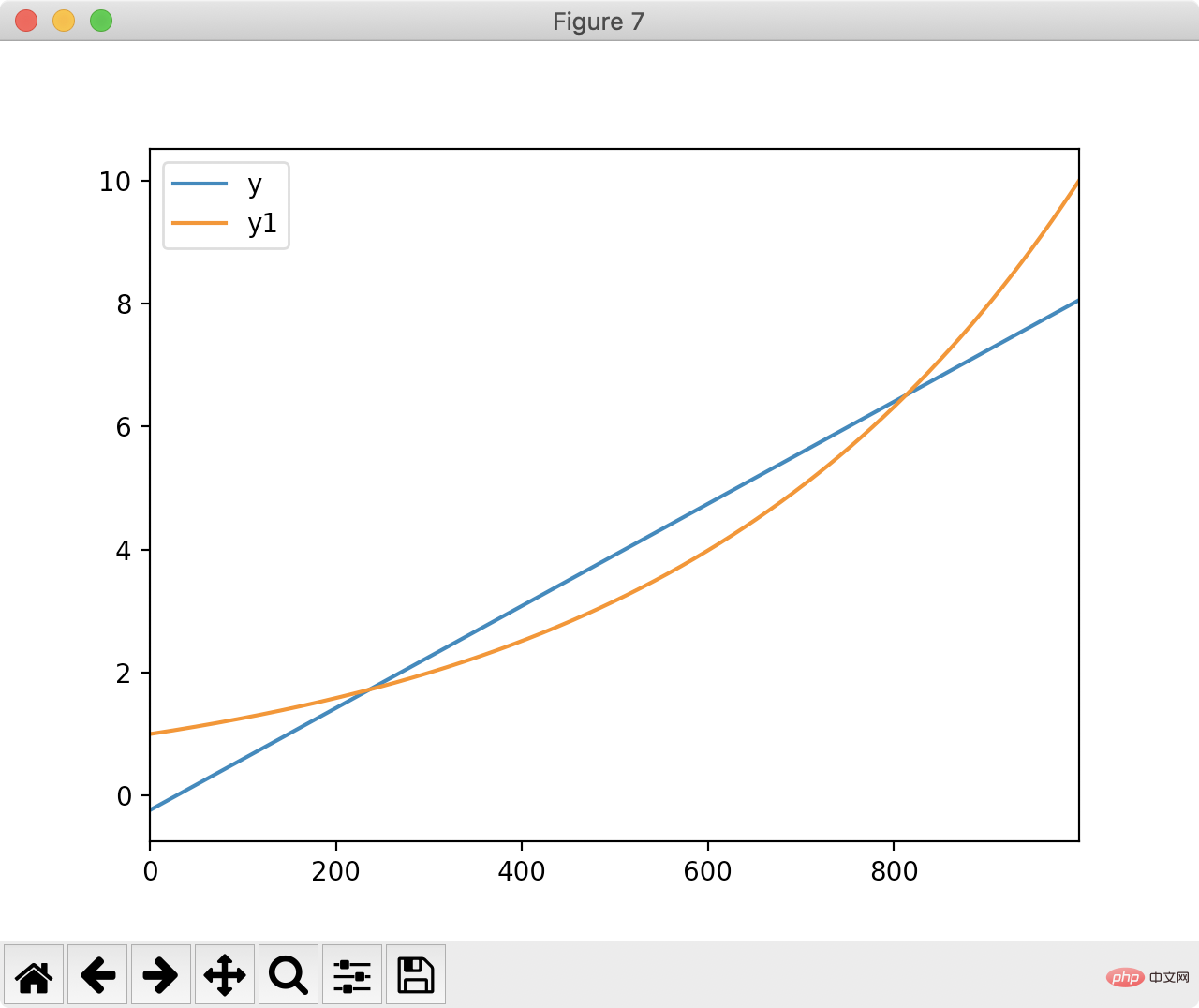
感谢大家的阅读,希望大家收益多多。
本文转自:https://blog.csdn.net/u010751000/article/details/106735872
推荐教程:《python教程》
以上就是值得一看的Python高效数据处理的详细内容,更多请关注靠谱客其它相关文章!

最后
以上就是优秀纸鹤最近收集整理的关于值得一看的Python高效数据处理的全部内容,更多相关值得一看内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复