前段时间有个需求是要求查一段时间的dns上的域名访问次数排行(top100),没办法,只好慢慢的去解析dns日志呗,正好学习了python,拿来练练手。
1.原始数据分析:
首先看下原始数据文件,即dns日志内容,下面是抽取的几条有代表性的日志,2×8.2×1.2x.1×5 这种中间的x是相应的数字被我抹去了。
13-08-30 03:11:34,226 INFO : queries: – |1×3.2×8.2×0.2×0|config.dengluqi.net||config.34245.com.;127.0.0.1;||A|success|+|–G—- qr rd ra |1|
13-08-30 03:11:34,229 INFO : queries: – |1×3.2×8.2x.2×8|p19.qhimg.com|default|2×8.2×1.2x.1×5;|default;|A|success|+|—w— qr aa rd ra |8061|
13-08-30 03:11:34,238 INFO : queries: – |1×3.2×8.x.9x|shu.taobao.com|default|2×8.2×1.2x.1×5;|default;|A|success|+|—w— qr aa rd ra |59034|
13-08-30 03:11:34,238 INFO : queries: – |1×3.2×8.2×7.1×2|cncjn.phn.live.baofeng.net|default|2×8.2×1.2x.17x;|default;|A|success|+|—w— qr aa rd ra |3004|
可以看出中间的日志采用的是| 分割的,shu.taobao.com 即为我们想要的数据域名,至于域名访问次数统计,则每个域名的一条记录算一次访问。由此我们可以确定一下两点:
a)采用| 作为分割符
b)第二个字段domain为目标数据,我们用作键值,即字典的key
c)domain[key]存储相应域名的访问次数
2.脚本构思:
a)我们的dns日志都是隔一段时间自动切割、压缩为gz文件,因此首先必须采用gzip.open去打开gz文件,这里需要导入gz库。
b)要求查找的是一段时间的域名排行,所以必须有得过滤一段时间,这里我采用了正则的方式去过滤,so导入re正则库。
c)排序,必须对结果进行排序,然后输出topXX的结果,由于是采用字典保存的,而字典是乱想的,所以必须有合适的办法去排序,字典的iteritems正好适用。
3.脚本编写:
明白了大致要点,脚本写起来就很easy了。
代码如下:
#write by siashero
import gzip
import re
file = gzip.open("e:\python_programs\queries.log.CBN-XA-1-3N3.20130803160052.gz")
domain_list= {}
print "time format is 13-08-04 19:1{1,2,3,4,5} "
time = raw_input("please enter a time you want to analysis")
while True:
line = file.readline()
if not line:
break
if re.search(time,line):
domain = line.split(‘|')[2]
if domain in domain_list:
domain_list[domain] += 1
else:
domain_list[domain] = 1
count = 0
for v in sorted(domain_list.iteritems(),key =lambda x:x[1],reverse=True):
print v[1],v[0]
#to print the only top20 domain
if count > 20:
break
count += 1
raw_input("enter a word to finish")
file.close
稍微说下脚本内容,queries.log.CMN-CQ.20130830031330.gz 为具体的一个目标文件,脚本主要是采用字典存储,以domain字段作为key,domain[key]存储访问次数。
稍后调用字典的iteritems 方法生产迭代器进行排序,最后输入top100的域名。
最后的raw_input(“enter a word to finish”) 是因为我在win7下测试的,默认执行完就一闪而过了,加入这行纯碎是为了观察结果,linux下可以删去。
这里稍微别扭的是时间的过滤采用的是正则去过滤的,所以要求输入必须是正则的方式,这点麻烦。
3.执行
说了大半天了,还是先跑下看看效果吧。
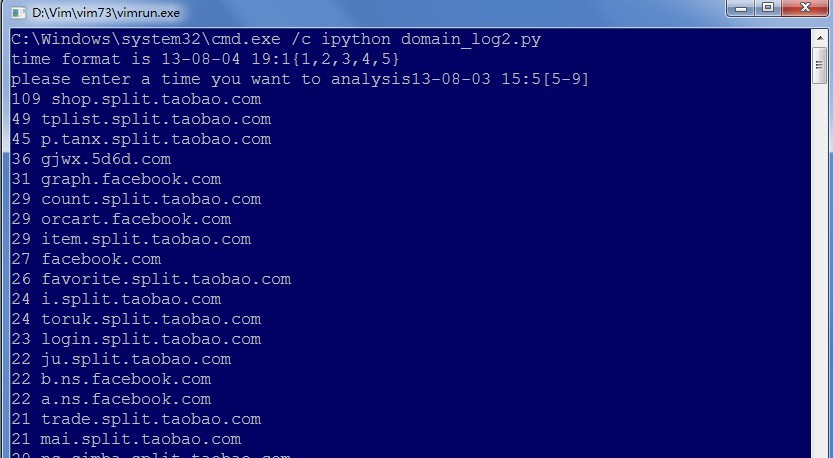
可以看出正常输出了top20的域名。
4.总结:
大致实现了相应的要求,只是很多的文件处理的不大好。例如采用正规去过滤时间段,在数据量很大的情况下会对性能有影响。同时感谢同事,最后的字典的排序方法我是抄他的,感谢个~
最后
以上就是眼睛大画板最近收集整理的关于python脚本实现分析dns日志并对受访域名排行的全部内容,更多相关python脚本实现分析dns日志并对受访域名排行内容请搜索靠谱客的其他文章。








发表评论 取消回复