大多数 SQL 数据库引擎 (据我们所知,除 SQLite 之外的所有 SQL 数据库引擎)都使用严格的静态类型。使用静态类型,值的类型便由它的容器 -- 存储值的特定的列 -- 来决定。
SQLite 使用更通用的动态类型系统。在 SQLit 中,值的数据类型与值本身相关,而不是与它的容器。SQLite 的动态类型系统与其它数据库引擎的常用静态类型系统是向后兼容的,在这个意义上,工作在静态类型数据库上的 SQL 语句应该以同样的方式工作在 SQLite 中。然而,SQLite 中的动态类型允许它做传统的严格类型的数据库所不能做的事。
1.0 存储类型与数据类型
存储在 SQLite 数据库中的每个值(或是由数据库引擎所操作的值)都有一个以下的存储类型:
- NULL. 值是空值。
- INTEGER. 值是有符号整数,根据值的大小以1,2,3,4,6 或8字节存储。
- REAL. 值是浮点数,以8字节 IEEE 浮点数存储。
- TEXT. 值是文本字符串,使用数据库编码(UTF-8, UTF-16BE 或 UTF-16LE)进行存储。
- BLOB. 值是一个数据块,按它的输入原样存储。
注意,存储类型比数据类型更笼统。以 INTEGER 存储类型为例,它包括6种不同的长度不等的整数类型,这在磁盘上是不同的。但是只要 INTEGER 值从磁盘读取到内存进行处理,它们就被转换为更为一般的数据类型(8字节有符号整型)。因此在一般情况下,“存储类型” 与 “数据类型” 没什么差别,这两个术语可以互换使用。
SQLite 版本3数据库中的任何列,除了整型主键列,都可用于存储任何存储类型的值。
SQL 语句中的任何值,无论它们是嵌入到 SQL 语句中的字面量还是绑定到预编译 SQL 语句中的参数,都有一个隐含的存储类型。在下述情况下,数据库引擎会在执行查询时在数值存储类型(INTEGER 和 REAL)和 TEXT 之间进行转换。
1.1 布尔类型
SQLite 并没有单独的布尔存储类型,而是将布尔值存储为整数 0 (false) 和 1 (true)。
1.2 日期和时间类型
SQLite 没有另外的存储类型来存储日期和时间。SQLite 的内置的日期和时间函数能够将日期和时间存为 TEXT、REAL 或 INTEGER 值:
- TEXT ISO8601 字符串 ("YYYY-MM-DD HH:MM:SS.SSS")。
- REAL 儒略日数 (Julian Day Numbers),按照前公历,自格林威治时间公元前4714年11月24日中午以来的天数。
- INTEGER Unix 时间,自 1970-01-01 00:00:00 UTC 以来的秒数。
应用可以选择这些格式中的任一种存储日期和时间,并使用内置的日期和时间函数在这些格式间自由转换。
2.0 类型亲和性
为了最大限度地提高 SQLite 和其它数据库引擎之间的兼容性,SQLite 支持列的“类型亲和性”的概念。列的类型亲和性是指数据存储于该列的推荐类型。这里重要的思想是类型是推荐的,而不是必须的。任何列仍可以存储任何类型的数据。这只是让一些列有选择性地优先使用某种存储类型。一个列的首选存储类型被称为它的“亲和性”。
每个 SQLite 3 数据库中的列都归于以下的类型亲和性中的一种:
- TEXT
- NUMERIC
- INTEGER
- REAL
- NONE
一个具有 TEXT 亲和性的列使用存储类型 NULL、 TEXT 或 BLOB 存储所有数据。如果数值数据被插入到一个具有 TEXT 亲和性的列,则数据在存储前被转换为文本形式。
数值亲和性的列可能包含了使用所有五个存储类的值。当插入文本数据到数值列时,该文本的存储类型被转换成整型或实数(按优先级排序)如果这种转换是无损或可逆的的话。对于文本与实数类型之间的转换,如果前15个重要十进制数字被保留的话,SQLite认为这种转换是无损并可逆的。如果文本不能无损地转换成整型或实数,那这个值将以文本类型存储。不要试图转换NULL或BLOB值。
一个字符串可能看上去像带有小数点和/或指数符的浮点文字,但只要这个值可以用一个整型表示,数值亲和性就会把它转换成一个整型。因此,字符串‘3.0e+5'以整型300000,而不是浮点值30000.0的形式存储在一个数值亲和性的列里。
一个使用整型亲和性的列与具有数值亲和性的列表现一致。只是在CAST表达式里,它们之间的区别体现得明显。
除了强制将整型值转换成浮点表示外,一个具有实数亲和性的列与具有数值亲和性的列表现一致(作为一个内部的优化,为了少占用空间,无小数部分且存储在实数亲和性列上的小浮点值以整型形式写到磁盘,读出时自动转换回浮点值。在SQL级别,这种优化是完全不可见的,并且只能通过检查数据库文件的原始比特检测到)。
一个具有NONE亲和性的列不能从一种存储类型转换成另一种,也不要试图强制对它进行转换。
2.1 列亲和性测定
列的亲和性是由它的声明类型决定的,按照以下顺序所示的规则:
1. 如果声明类型包含字符串“INT”,那它被指定为整型亲和性;
2. 如果列的声明类型包含任何“CHAR”、“CLOB”或“TEXT”字符串,那么该列具有文本亲和性。注意:VARCHAR类型包含“CHAR”并且被指定为文本亲和性;
3. 如果列的声明类型包含“BLOB”或者没有指定类型,那这列具有NONE亲和性;
4. 如果列的声明类型包含任何“REAL”、“FLOA”或“DOUB”字符串,则该列具有实数亲和性;
5. 否则,它将具有数值亲和性。
注意:判定列亲和性规则的顺序是很重要的。一个具有“CHARINT”声明类型的列将匹配规则1和2,但是规则1优先所有该列具有整型亲和性。
2.2 亲和性名字实例
下表显示了有多少从更传统的SQL实现的常用数据类型名,通过上一节介绍的五个规则被转换成各种亲和性类型。这张表只显示了SQLite可接受的一小部分数据类型名。注意:跟在类型名后,括号内数值参数(如:VARCHAR(255))将被SQLite忽略 - SQLite不对字符串、BLOBs或数值的长度强加任何限制(除了大型全局SQLITE_MAX_LENGTH限制)。
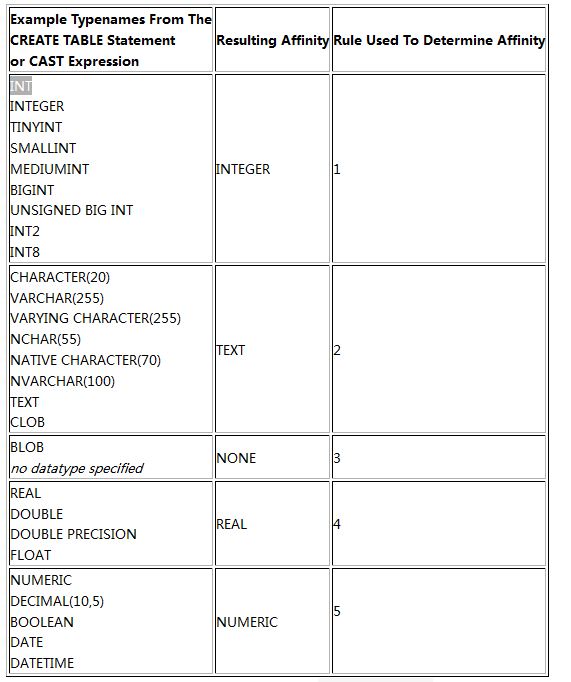
注意: 因为在“POINT”末尾的“INT”,一个“ FLOATING POINT”声明类型 会被赋予整型亲和性,而不是实数亲和性。而且“STRING”声明类型具有数值亲和性,而不是文本亲和性。
2.3 列亲和性行为实例
以下SQL演示当有值插入到一张表时,SQLite如何使用列亲和性实现类型转换的:
CREATE TABLE t1( t TEXT, -- text affinity by rule 2 nu NUMERIC, -- numeric affinity by rule 5 i INTEGER, -- integer affinity by rule 1 r REAL, -- real affinity by rule 4 no BLOB -- no affinity by rule 3 );
-- Values stored as TEXT, INTEGER, INTEGER, REAL, TEXT.(值分别以文本、整型、整型、实数、文本形式存储)
INSERT INTO t1 VALUES('500.0', '500.0', '500.0', '500.0', '500.0');
SELECT typeof(t), typeof(nu), typeof(i), typeof(r), typeof(no) FROM t1;
text|integer|integer|real|text
-- Values stored as TEXT, INTEGER, INTEGER, REAL, REAL.
DELETE FROM t1;
INSERT INTO t1 VALUES(500.0, 500.0, 500.0, 500.0, 500.0);
SELECT typeof(t), typeof(nu), typeof(i), typeof(r), typeof(no) FROM t1;
text|integer|integer|real|real
-- Values stored as TEXT, INTEGER, INTEGER, REAL, INTEGER.
DELETE FROM t1;
INSERT INTO t1 VALUES(500, 500, 500, 500, 500);
SELECT typeof(t), typeof(nu), typeof(i), typeof(r), typeof(no) FROM t1;
text|integer|integer|real|integer
-- BLOBs are always stored as BLOBs regardless of column affinity. DELETE FROM t1;
INSERT INTO t1 VALUES(x'0500', x'0500', x'0500', x'0500', x'0500');
SELECT typeof(t), typeof(nu), typeof(i), typeof(r), typeof(no) FROM t1;
blob|blob|blob|blob|blob
-- NULLs are also unaffected by affinity
DELETE FROM t1;
INSERT INTO t1 VALUES(NULL,NULL,NULL,NULL,NULL);
SELECT typeof(t), typeof(nu), typeof(i), typeof(r), typeof(no) FROM t1;
null|null|null|null|null
3.0 比较表达式
同标准SQL一样,SQLite 3支持如下的比较操作符:"=", "==", "<", "<=", ">", ">=", "!=", "<>", "IN", "NOT IN", "BETWEEN", "IS", 以及 "IS NOT"。
3.1 排序规则
比较的结果与操作数的存储类型有关,同时依据以下的规则:
- NULL值小于其他任何值(包括另外一个NULL)
- INTEGER或REAL小于TEXT,BLOB值;若两个INTEGER(或者REAL)比较,则按照实际的数值进行。
- TEXT小于BLOB,若两个TEXT比较,结果则由适当的整理顺序决定
- 若两个BLOD比较,与memcmp()的结果一致
3.2 操作数进行比较时的相似性
在进行值的比较之前,SQLite会尝试在存储类INTEGER、REAL和/或TEXT之间进行值的转换。在比较之前尝不尝试进行转换完全取决于操作数的相似性。操作数相似性的判定规则如下:
- 只是对一个列中的值进行引用的表达式同被引用的列具有完全相同的相似性。注意,如果X、Y.Z代表的是列的名称,那么+X和+Y.Z可以认为是为了判定其相似性的表达式。
- "CAST(expr AS type)"所表示的表达式同类型定义为"type"的列具有完全相同的相似性。
- 其它情况下的表达式具有NONE相似性。
3.3 比较前的类型转换
“应用相似性”("apply affinity")的意思是,当且仅当所涉及的转换是无损且可逆的情况下,将一个操作数转换为某特定的存储类型。在进行比较之前对比较运算符的操作数应用相似性的规则如下按顺序所示:
- 如果其中的一个操作数具有INTEGER、REAL或者NUMERIC相似性而另外一个操作数具有TEXT或者NONE相似性,那么就要对这另外一个操作数应用NUMERIC 相似性。
- 如果其中的一个操作数具有TEXT相似性而另外一个具有NONE相似性,那么就要对这另外一个操作数应用TEXT相似性。
- 其它情况下不会应用任何相似性,两个操作数按照各自的原样进行比较。
将表达式"a BETWEEN b AND c"看作两个单独的二元比较运算"a >= b AND a <= c",即使这么一来,可能会造成其中的a在两次比较中会被应用不同的相似性,也要这么处理。Datatype conversions in comparisons of the form 在"x IN (SELECT y ...)"这种形式的比较中,数据类型的转换完全同"x=y"一样进行处理。表达式"a IN (x, y, z, ...)" 同"a = +x OR a = +y OR a = +z OR ..."等价。换句话说,IN运算符右侧的值(本例中就是"x", "y", and "z")被看作是无相似性的,即使它们凑巧是某列的值或者是CAST表达式。
3.4 比较示例
CREATE TABLE t1(
a TEXT, -- text affinity
b NUMERIC, -- numeric affinity
c BLOB, -- no affinity
d -- no affinity
);
-- Values will be stored as TEXT, INTEGER, TEXT, and INTEGER respectively
INSERT INTO t1 VALUES('500', '500', '500', 500);
SELECT typeof(a), typeof(b), typeof(c), typeof(d) FROM t1;
text|integer|text|integer
-- Because column "a" has text affinity, numeric values on the
-- right-hand side of the comparisons are converted to text before
-- the comparison occurs.
SELECT a < 40, a < 60, a < 600 FROM t1;
0|1|1
-- Text affinity is applied to the right-hand operands but since
-- they are already TEXT this is a no-op; no conversions occur.
SELECT a < '40', a < '60', a < '600' FROM t1;
0|1|1
-- Column "b" has numeric affinity and so numeric affinity is applied
-- to the operands on the right. Since the operands are already numeric,
-- the application of affinity is a no-op; no conversions occur. All
-- values are compared numerically.
SELECT b < 40, b < 60, b < 600 FROM t1;
0|0|1
-- Numeric affinity is applied to operands on the right, converting them
-- from text to integers. Then a numeric comparison occurs.
SELECT b < '40', b < '60', b < '600' FROM t1;
0|0|1
-- No affinity conversions occur. Right-hand side values all have
-- storage class INTEGER which are always less than the TEXT values
-- on the left.
SELECT c < 40, c < 60, c < 600 FROM t1;
0|0|0
-- No affinity conversions occur. Values are compared as TEXT.
SELECT c < '40', c < '60', c < '600' FROM t1;
0|1|1
-- No affinity conversions occur. Right-hand side values all have
-- storage class INTEGER which compare numerically with the INTEGER
-- values on the left.
SELECT d < 40, d < 60, d < 600 FROM t1;
0|0|1
-- No affinity conversions occur. INTEGER values on the left are
-- always less than TEXT values on the right.
SELECT d < '40', d < '60', d < '600' FROM t1;
1|1|1
若示例中的比较被替换——例如"a<40"被写作"40>a"——所有的结果依然相同相同。
4.0 操作符
所有的数学运算符(+, -, *, /, %, <<, >>, &, and |)在展开前会将两个操作数放入 NUMERIC 储存类。即使这个过程是有损和不可逆转的。一个 NULL 操作数在数学运算符上产生一个 NULL 结果。在数算运算符上的操作数不被视为数字,NULL 并不会被转为0或0.0。
5.0 排序, 分组 和 组合查询
当查询结果使用 ORDER BY 子句排序时, 存储类型的NULL空值是排在第一位的, 其次是INTEGER和散布在数字顺序的REAL数据, 其次是按照核对序列顺序的TEXT值, 最后为memcmp() order 的BLOB值. 排序之前不会出现任何存储类型转换.
当使用GROUP BY 子句分组时不同类型的值被认为是不同的数据, 除了INTEGER 和 REAL 值如果他们数值相等则被认为是相同的的数据. 没有任何亲和性适用于GROUP BY 子句结果的任意值.
组合查询使用 UNION, INTERSECT 和 EXCEPT 在数据之间执行隐式的比较. 没有任何亲和性适用于与UNION, INTERSECT, 或者 EXCEPT关联的隐式比较的运算数 - 数据的比较就像这样.
6.0 整理序列
当 SQLite 比较两个字符串时,它使用一个整理序列或整理函数(一物两表)来决定当两个字符串相同时,哪个字符串值更高。SQLite 拥有三个内建整理函数:BINARY, NOCASE, 和 RTRIM。
- BINARY - 使用 memcmp() 比较字符串,无视文本编码。
- NOCASE - 与二进制比较相同,除了 ASCII 的26个大写字母在比较前将会转为其小写形势。注意,只有 ASCII 字符会大小写转化。 由于表大小的需求,SQLite 并不会尝试 UTF 大小写转化。
- RTRIM - 与二进制比较相同,除了尾部空格符将被忽略。
应用可以通过 sqlite3_create_collation() 接口注册额外的整理函数。
6.1 设定SQL中的排列顺序
每个表中的每一个列都具有一个相关的排序函数。如果没有显式地定义排序函数,那么,就会缺省使用BINARY作为排序函数。列定义中的COLLATE子句可为列定义一个可选的排序函数。
对于二元比较运算符(=, <, >, <=, >=, !=, IS, and IS NOT)来说,判定到底使用哪个排序函数的规则按顺序如下所列:
- 如果两个操作数中有任意一个操作数具有使用后缀COLLATE运算符显式定义的排序函数,那么就会用该函数进行比较,如果两个操作数都有的情况下,优先使用左操作数的排序函数。
- 如果两个操作数中任意一个操作数是一个列,那么就会使用该列的排序函数进行比较,但在两个操作数都是列的情况下,优先使用左操作数对应的列的排序函数。为了达到这句话的目的,列名前带有1个或多个一元运算符"+"的,仍然按原列名处理。
- 其它情况下,采用BINARY排序函数进行比较。
比较运算中的操作数,如果在它的任何子表达式中使用了后缀 COLLATE运算符,就可以认为是具有显式的排序函数(上文中的规则1)。 再者,如果在比较表达式中的任何地方使用了 COLLATE运算符,那么该运算符所定义的排序函数就会用于字符串的比较,而无论在表达式中出现了表中的哪一列。如果在比较中的任何地方出现了两个或多个 COLLATE运算符子表达式,无论在表达式中嵌入得多深,也无论表达式是怎么使用括号的,都会使用出现在最左侧的显式排序函数。
表达式"x BETWEEN y and z"从逻辑上讲,同"x >= y AND x <= z"这两个比较运算完全等价,在使用排序函数时它们俩要象两个本来就是独立的比较运算一样进行处理。在判定排列顺序时,表达式"x IN (SELECT y ...)"处理方式完全同表达式"x = y"一样,形如"x IN (y, z, ...)"的表达式,排列顺序完全同X的排列顺序一样。
作为 SELECT语句的一个部分,ORDER BY子句中排序条件也可以通过使用COLLATE运算符设定排列顺序,如果设定了排序时就要按照设定的排序函数进行排序。否则,如果ORDER BY子句使用的排序表达式是一个列,那么该列的排列顺序就用于判定排列顺序。如果该排序表达式不是列并且也无COLLATE子句,就会使用BINARY排列顺序。
6.2 整理序列示例
下面的示例将识别整理序列,决定 SQL 语句的文本比较结果。注意,在文本比较时,如果是数字,二进制或Null值,整理序列可能并没有被使用。
CREATE TABLE t1(
x INTEGER PRIMARY KEY,
a, /* collating sequence BINARY */
b COLLATE BINARY, /* collating sequence BINARY */
c COLLATE RTRIM, /* collating sequence RTRIM */
d COLLATE NOCASE /* collating sequence NOCASE */
);
/* x a b c d */
INSERT INTO t1 VALUES(1,'abc','abc', 'abc ','abc');
INSERT INTO t1 VALUES(2,'abc','abc', 'abc', 'ABC');
INSERT INTO t1 VALUES(3,'abc','abc', 'abc ', 'Abc');
INSERT INTO t1 VALUES(4,'abc','abc ','ABC', 'abc');
/* a=b 的文本比较表现为使用 BINARY (二进制)整理序列。 */
SELECT x FROM t1 WHERE a = b ORDER BY x;
--结果 1 2 3
/* a=b 的文本比较表现为使用 RTRIM 整理序列。 */
SELECT x FROM t1 WHERE a = b COLLATE RTRIM ORDER BY x;
--结果 1 2 3 4
/* d=a 的文本比较表现为使用 NOCASE 整理序列。 */
SELECT x FROM t1 WHERE d = a ORDER BY x;
--结果 1 2 3 4
/* a=d 的文本比较表现为使用 BINARY (二进制)整理序列。 */
SELECT x FROM t1 WHERE a = d ORDER BY x;
--结果 1 4
/* 'abc'=c 的文本比较表现为使用 RTRIM (二进制)整理序列。 */
SELECT x FROM t1 WHERE 'abc' = c ORDER BY x;
--结果 1 2 3
/* c='abc' 的文本比较表现为使用 RTRIM 整理序列。 */
SELECT x FROM t1 WHERE c = 'abc' ORDER BY x;
--结果 1 2 3
/* 分组表现为使用 NOCASE 整理序列(值'abc','ABC' 和 'Abc'
** 被分为同一组)。*/
SELECT count(*) FROM t1 GROUP BY d ORDER BY 1;
--结果 4
/* 分组表现为使用 BINARY 整理序列(值'abc','ABC' 和 'Abc'
** 被分为不同的组)。*/
SELECT count(*) FROM t1 GROUP BY (d || '') ORDER BY 1;
--结果 1 1 2
/* 列c排序表现为使用 RTRIM 整理序列。*/(译注:sorting or column c 疑为 sorting of...误写)
SELECT x FROM t1 ORDER BY c, x;
--结果 4 1 2 3
/* (c||'')排序表现为使用 BINARY 整理序列。*/
SELECT x FROM t1 ORDER BY (c||''), x;
--结果 4 2 3 1
/* 列c排序表现为使用 NOCASE 整理序列。*/
SELECT x FROM t1 ORDER BY c COLLATE NOCASE, x;
--结果 2 4 3 1
最后
以上就是开心羽毛最近收集整理的关于详解SQLite中的数据类型的全部内容,更多相关详解SQLite中内容请搜索靠谱客的其他文章。








发表评论 取消回复