在实际的业务中,可能会遇到很大量的特征,这些特征良莠不齐,层次不一,可能有缺失,可能有噪声,可能规模不一致,可能类型不一样,等等问题都需要我们在建模之前,先预处理特征或者叫清洗特征。那么这清洗特征的过程可能涉及多个步骤可能比较复杂,为了代码的简洁,我们可以将所有的预处理过程封装成一个函数,然后直接往模型中传入这个函数就可以啦~~~
接下来我们看看究竟如何做呢?
1. 如何使用input_fn自定义输入管道
当使用tf.contrib.learn来训练一个神经网络时,可以将特征,标签数据直接输入到.fit(),.evaluate(),.predict()操作中。比如在笔记04中就使用到了,复看一下代码:
# 将特征与标签数据载入
training_set = tf.contrib.learn.datasets.base.load_csv_with_header(
filename=IRIS_TRAINING, target_dtype=np.int, features_dtype=np.float32)
test_set = tf.contrib.learn.datasets.base.load_csv_with_header(
filename=IRIS_TEST, target_dtype=np.int, features_dtype=np.float32)
# 然后将两个数据喂给.fit()函数去训练
classifier.fit(x=training_set.data,
y=training_set.target,
steps=2000)
当原始数据不需要或几乎很少需要一些额外的预处理时,使用以上的方式到也不为过。然而在实际的业务中我们往往需要去做大量的特征工程,于是tf.contrib.learn支持使用一个用户自定义的输入函数input_fn来封装数据预处理的逻辑,并且将数据通过管道输送到模型中。
1.1 解剖input_fn函数的结构
以下是一个input_fn函数的基本结构:
def my_input_fn(): # Preprocess your data here...(首先预处理你的数据) # ...then return 1) a mapping of feature columns to Tensors with # the corresponding feature data, and 2) a Tensor containing labels # 然后返回新的特征数据与标签数据(都是以tensor的形式) return feature_cols, labels
输入函数的主体包括一个特定的预处理输入数据的逻辑,比如去除一些脏数据,弥补缺失数据,归一化等等。
输入函数的返回是两个部分:
(1)处理后的特征:feature_cols,格式是一个map,key是特征的名称,value是tensor形式的对应的特征列数据
(2)标签数据:labels,一个包含标签数据的tensor
1.2 如何将特征数据转换成tensors形式
如果你的特征/标签是存储在pandas的dataframe中或者numpy的array中的话,你就需要在返回特征与标签的时候将它们转换成tensor形式哦~那么怎么转换呢,来看一个小例子。
对于连续型数据,你可以使用tf.constant创建一个tensor:
feature_column_data = [1, 2.4, 0, 9.9, 3, 120] feature_tensor = tf.constant(feature_column_data)
对于稀疏型数据,类别下数据,你可以使用tf.SparseTensor来创建tensor:
sparse_tensor = tf.SparseTensor(indices=[[0,1], [2,4]],
values=[6, 0.5],
dense_shape=[3, 5])
可见,tf.SparseTensor有3个参数,分别是:
(1)dense_shape
这是tensor的shape,比如dense_shape=[3,6],表示tensor有3*6共2个维度;dense_shape=[2,3,4]表示tensor有2*3*4共3个维度;dense_shape=[9]表示tensor有1个维度,这个维度里有9个元素。
(2)indices
表示在这个tensor中indices索引所在的位置是非0值,其余都是0值。比如[0,0]表示在第1行第1列的值非0.
(3)values
value是一个1维的tensor, 其元素与indices中的索引一一对应,比如indices=[[1,3], [2,4]],values=[18, 3.6],表示在行索引为1列索引为3的位置值为18,在行索引为2列索引为4的位置值为3.6
因此上面的代码意思一目了然了,创建一个稀疏tensor,大小是3*5,在行索引为0列索引为1的位置值为6,在行索引为2,列索引为4的位置值为0.5,其余位置值为0.
打印出来应是:
[[0, 6, 0, 0, 0]
[0, 0, 0, 0, 0]
[0, 0, 0, 0, 0.5]]
1.3 如何将input_fn数据传给模型
在输入函数input_fn中封装好了特征预处理的逻辑,并且也返回了新的特征与标签。那怎么把这个输入函数或者说新的特征与标签传入模型中呢?
在.fit()操作中有一个参数:input_fn,只要将我们定义好的输入函数传给这个参数即可:
classifier.fit(input_fn=my_input_fn, steps=2000)
但是,极其注意的是绝不能直接这样做:
classifier.fit(input_fn=my_input_fn(training_set), steps=2000)
如果你想直接传参数给输入函数,可以选择令爱几个方法:
(1)再写一个封装函数如下:
def my_input_function_training_set(): return my_input_function(training_set) classifier.fit(input_fn=my_input_fn_training_set, steps=2000)
(2)使用Python's functools.partial方法:
classifier.fit(input_fn=functools.partial(my_input_function,
data_set=training_set), steps=2000)
(3)在lambda中调用输入函数,然后将参数传入input_fn中
classifier.fit(input_fn=lambda: my_input_fn(training_set), steps=2000)
个人建议使用第三种方法。
2.案例实战
2.1 数据介绍
数据集下载地址:https://archive.ics.uci.edu/ml/datasets/Housing
这是一份预测房价的数据,我们用它去训练一个神经网络去预测房价,总共选取9个特征,数据的特征如下:
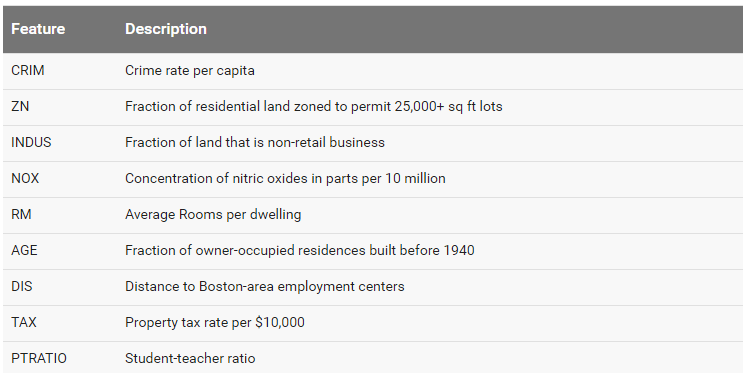
要预测的标签数据是MEDV,是业主自用住宅的价格均值。
在开始建模之前,我们先去下载好 boston_train.csv(训练集), boston_test.csv(测试集), and boston_predict.csv(预测集)这份文件
2.2 加载数据
首先导入需要的库(包括pandas, tensorflow),并且设置logging verbosity为INFO,这样就可以获取到更多的日志信息了。
from __future__ import absolute_import from __future__ import division from __future__ import print_function import itertools import pandas as pd import tensorflow as tf tf.logging.set_verbosity(tf.logging.INFO)
定义一个变量COLUMNS,将所有的特征名称与类别标签名称存储成list并赋值给他。
为了区分特征名称与标签名称,同时也将它们分别春初一个变量
COLUMNS = ["crim", "zn", "indus", "nox", "rm", "age", "dis", "tax", "ptratio", "medv"] FEATURES = ["crim", "zn", "indus", "nox", "rm", "age", "dis", "tax", "ptratio"] LABEL = "medv"
然后,将三份数据文件都用pandas.read_csv载入:
第一个参数是数据文件的路径,第二个参数是是否需要取出前后空值,第三个参数是去除的行数,第四个参数是列名
training_set = pd.read_csv("boston_train.csv", skipinitialspace=True,
skiprows=1, names=COLUMNS)
test_set = pd.read_csv("boston_test.csv", skipinitialspace=True,
skiprows=1, names=COLUMNS)
prediction_set = pd.read_csv("boston_predict.csv", skipinitialspace=True,
skiprows=1, names=COLUMNS)
2.3 定义特征列并且创建回归模型
现在创建一组FeatureColumn作为输入数据,正式指定哪些特征需要被用来训练。在我们的房价预测特征中所有数据都是连续型的值,因此你可以直接使用tf.contrib.layers.real_valued_column()来创建FeatureColumn
feature_cols = [tf.contrib.layers.real_valued_column(k)
for k in FEATURES]
接着我们来调用DNNRegressor函数实例化一个神经网络回归模型。
这里需要提供3个参数:
- feature_columns:一组刚刚定义的特征列
- hidden_units:每层隐藏层的神经网络个数
- model_dir:模型保存的路径
regressor = tf.contrib.learn.DNNRegressor(feature_columns=feature_cols,
hidden_units=[10, 10],
model_dir="/tmp/boston_model")
2.4 构建输入函数input_fn
这里我们构建一个输入函数去预处理数据,处理的内容比较简单,只是将用pandas读进来的dataframe形式的数据转换成tensor.
def input_fn(data_set):
feature_cols = {k: tf.constant(data_set[k].values)
for k in FEATURES}
labels = tf.constant(data_set[LABEL].values)
return feature_cols, labels
2.5 训练模型
训练模型,我们调用fit()函数,并且将训练数据集training_set作为参数传入
regressor.fit(input_fn=lambda: input_fn(training_set), steps=5000)
运行代码,你会看到有如下日志打印:
INFO:tensorflow:Step 1: loss = 483.179
INFO:tensorflow:Step 101: loss = 81.2072
INFO:tensorflow:Step 201: loss = 72.4354
...
INFO:tensorflow:Step 1801: loss = 33.4454
INFO:tensorflow:Step 1901: loss = 32.3397
INFO:tensorflow:Step 2001: loss = 32.0053
INFO:tensorflow:Step 4801: loss = 27.2791
INFO:tensorflow:Step 4901: loss = 27.2251
INFO:tensorflow:Saving checkpoints for 5000 into /tmp/boston_model/model.ckpt.
INFO:tensorflow:Loss for final step: 27.1674.
2.6 评估模型
模型训练好,就到了评估的时刻了,还是用测试数据集test_set来评估
ev = regressor.evaluate(input_fn=lambda: input_fn(test_set), steps=1)
提取损失并打印:
loss_score = ev["loss"]
print("Loss: {0:f}".format(loss_score))
打印结果应如下:
INFO:tensorflow:Eval steps [0,1) for training step 5000.
INFO:tensorflow:Saving evaluation summary for 5000 step: loss = 11.9221
Loss: 11.922098
2.7 使用模型做预测
模型要是评估通过,就可以用来预测新的数据了呢,这里我们使用prediction_set这个数据集,数据中只包含了特征没有标签,需要我们去预测。
y = regressor.predict(input_fn=lambda: input_fn(prediction_set))
# .predict() returns an iterator; convert to a list and print predictions
predictions = list(itertools.islice(y, 6))
print ("Predictions: {}".format(str(predictions)))
打印结果如下:
Predictions: [ 33.30348587 17.04452896 22.56370163 34.74345398 14.55953979
19.58005714]
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本之家。
最后
以上就是怕黑啤酒最近收集整理的关于Tensorflow 利用tf.contrib.learn建立输入函数的方法的全部内容,更多相关Tensorflow内容请搜索靠谱客的其他文章。








发表评论 取消回复