网站经常会被各种爬虫光顾,有的是搜索引擎爬虫,有的不是,通常情况下这些爬虫都有UserAgent,而我们知道UserAgent是可以伪装的,UserAgent的本质是Http请求头中的一个选项设置,通过编程的方式可以给请求设置任意的UserAgent。
所以通过UserAgent判断请求的发起者是否是搜索引擎爬虫(蜘蛛)的方式是不靠谱的,更靠谱的方法是通过请求者的ip对应的host主机名是否是搜索引擎自己家的host的方式来判断。
要获得ip的host,在windows下可以通过nslookup命令,在linux下可以通过host命令来获得,例如:
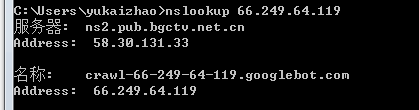
这里我在windows下执行了nslookup ip 的命令,从上图可以看到这个ip的主机名是crawl-66-249-64-119.googlebot.com。 这说明这个ip是一个google爬虫,google爬虫的域名都是 xxx.googlebot.com.
我们也可以通过python程序的方式来获得ip的host信息,代码如下:
import socket def getHost(ip): try: result=socket.gethostbyaddr(ip) if result: return result[0], None except socket.herror,e: return None, e.message
上述代码使用了socket模块的gethostbyaddr的方法获得ip地址的主机名。
常用蜘蛛的域名都和搜索引擎官网的域名相关,例如:
百度的蜘蛛通常是baidu.com或者baidu.jp的子域名
google爬虫通常是googlebot.com的子域名
微软bing搜索引擎爬虫是search.msn.com的子域名
搜狗蜘蛛是crawl.sogou.com的子域名
基于以上原理,我写了一个工具页面提供判断ip是否是真实搜索引擎的工具页面,该页面上提供了网页判断的工具和常见的google和bing的搜索引擎爬虫的ip地址。
附带常见搜索引擎蜘蛛的IP段:
| 蜘蛛名称 | IP地址 |
|---|---|
| Baiduspider |
202.108.11.* 220.181.32.* 58.51.95.* 60.28.22.* 61.135.162.* 61.135.163.* 61.135.168.* |
| YodaoBot |
202.108.7.215 202.108.7.220 202.108.7.221 |
| Sogou web spider |
219.234.81.* 220.181.61.* |
| Googlebot |
203.208.60.* |
| Yahoo! Slurp |
202.160.181.* 72.30.215.* 74.6.17.* 74.6.22.* |
| Yahoo ContentMatch Crawler |
119.42.226.* 119.42.230.* |
| Sogou-Test-Spider |
220.181.19.103 220.181.26.122 |
| Twiceler |
38.99.44.104 64.34.251.9 |
| Yahoo! Slurp China |
202.160.178.* |
| Sosospider | 124.115.0.* |
| CollapsarWEB qihoobot |
221.194.136.18 |
| NaverBot |
202.179.180.45 |
| Sogou Orion spider |
220.181.19.106 220.181.19.74 |
| Sogou head spider |
220.181.19.107 |
| SurveyBot |
216.145.5.42 64.246.165.160 |
| Yanga WorldSearch Bot v |
77.91.224.19 91.205.124.19 |
| baiduspider-mobile-gate |
220.181.5.34 61.135.166.31 |
| discobot |
208.96.54.70 |
| ia_archiver | 209.234.171.42 |
| msnbot |
65.55.104.209 65.55.209.86 65.55.209.96 |
| sogou in spider |
220.181.19.216 |
ps:https协议网页能够被搜索引擎收录吗
百度现在只能收录少部分的https,大部分的https网页无法收录。
不过我查询了google资料,Google能够比较好地收录https协议的网站。
所以如果你的网站是中文的,而且比较关注搜索引擎自然排名流量这块,建议尽量不要将所有内容都放到https中去加密去。
可考虑的方式是:
1、对于需要加密传递的数据,使用https,比如用户登录以及用户登录后的信息;
2、对于普通的新闻、图片,建议使用http协议来传输;
3、网站首页建议使用http协议的形式。
最后
以上就是傲娇毛豆最近收集整理的关于如何准确判断请求是搜索引擎爬虫(蜘蛛)发出的请求的全部内容,更多相关如何准确判断请求是搜索引擎爬虫(蜘蛛)发出内容请搜索靠谱客的其他文章。








发表评论 取消回复