我是靠谱客的博主 受伤汽车,这篇文章主要介绍可解释机器学习- InterpretML的使用|interpretable machine learning- InterpretML tutorial代码示例Introduction代码示例Reference,现在分享给大家,希望可以做个参考。
Contents
- 代码示例
- Introduction
- 代码示例
- 训练Glassbox模型
- 解释Glassbox模型
- 训练Blackbox模型
- 解释Blackbox模型
- Reference
代码示例
全部代码示例请参考:
https://github.com/Alex2Yang97/Learning_tutorials/tree/main/InterpretML
Introduction
InterpretML 是一个为实践者和研究者提供机器学习可解释性算法的开源 Python 软件包。InterpretML 能提供两种类型的可解释性:(1)明箱(glassbox),这是针对可解释性设计的机器学习模型(比如线性模型、规则列表、广义加性模型);(2)**黑箱(blackbox)可解释技术,用于解释已有的系统(比如部分依赖、LIME、SHAP)。这个软件包可让实践者通过在一个统一的 API 下,借助内置的可扩展可视化平台,使用多种方法来轻松地比较可解释性算法。InterpretML 也包含了可解释 Boosting 机(Explainable Boosting Machine)**的首个实现,这是一种强大的可解释明箱模型,可以做到与许多黑箱模型同等准确。
代码示例
- 加载数据
import pandas as pd
from sklearn.model_selection import train_test_split
df = pd.read_csv(
"https://archive.ics.uci.edu/ml/machine-learning-databases/adult/adult.data",
header=None)
df.columns = [
"Age", "WorkClass", "fnlwgt", "Education", "EducationNum",
"MaritalStatus", "Occupation", "Relationship", "Race", "Gender",
"CapitalGain", "CapitalLoss", "HoursPerWeek", "NativeCountry", "Income"
]
train_cols = df.columns[0:-1]
label = df.columns[-1]
X = df[train_cols]
y = df[label]
seed = 1
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, random_state=seed)
训练Glassbox模型
- Glassbox模型是完全可解释的,并且能提供和目前最前沿的模型差不多的准确率
- interpretML可以让我们使用类似于sklearn的接口,来训练Glassbox模型
from interpret.glassbox import ExplainableBoostingClassifier
ebm = ExplainableBoostingClassifier(random_state=seed)
ebm.fit(X_train, y_train)
解释Glassbox模型
- Glassbox模型可以提供全局global (overall behavior)和局部local (individual predictions)的解释
- 全局解释可以帮助我们理解模型认为什么是重要的,鉴别预测中潜在的问题(比如种族偏见)
全局解释 Global explanation
from interpret import set_visualize_provider
from interpret.provider import InlineProvider
set_visualize_provider(InlineProvider())
from interpret import show
ebm_global = ebm.explain_global()
show(ebm_global)
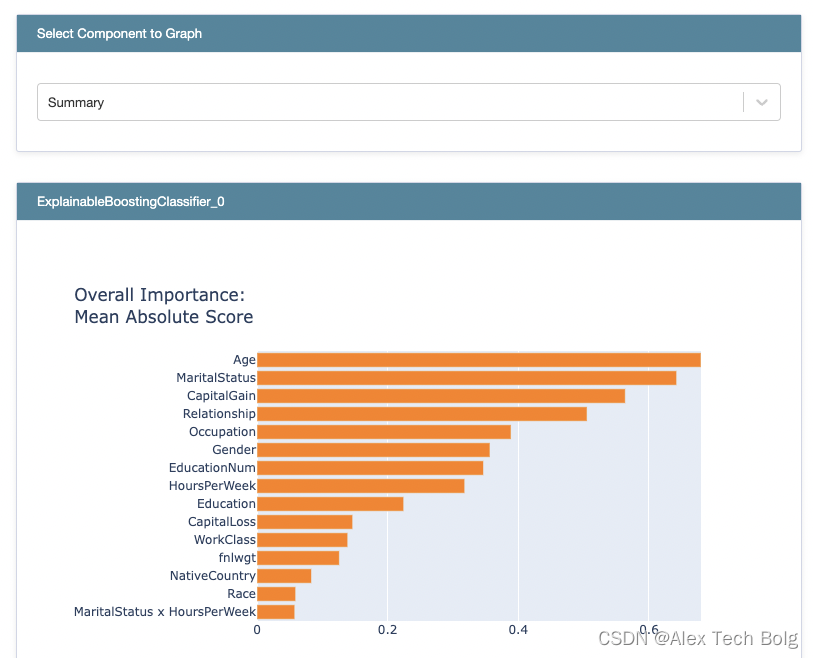
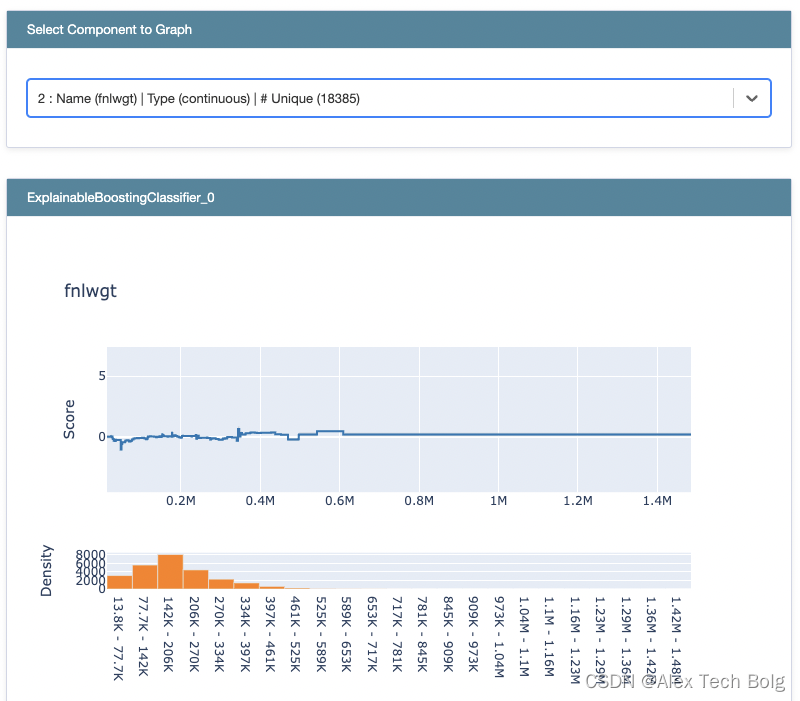
- 如果是回归模型,Score表示的就是预测目标,比如说房价预测模型,那么socre表示的就是价格(类似于shap,表示的也是单个特征对于输出的贡献)
- 如果是分类模型,Score表示的是log odds,log odds经过logit function之后才得到概率(这个也和shap是一样的)
L o g o d d s = L o g i t ( P ) = l n ( p 1 − p ) Log odds = Logit(P) = ln(frac{p}{1-p}) Log odds=Logit(P)=ln(1−pp) - Density表示的是特征在数据上的分布情况
- Summary的计算:计算每个特征在每个样本上的“贡献”,去绝对值,然后求平均得到整体的重要性
局部解释 Local explanation
ebm_local = ebm.explain_local(X_test[:5], y_test[:5])
show(ebm_local)
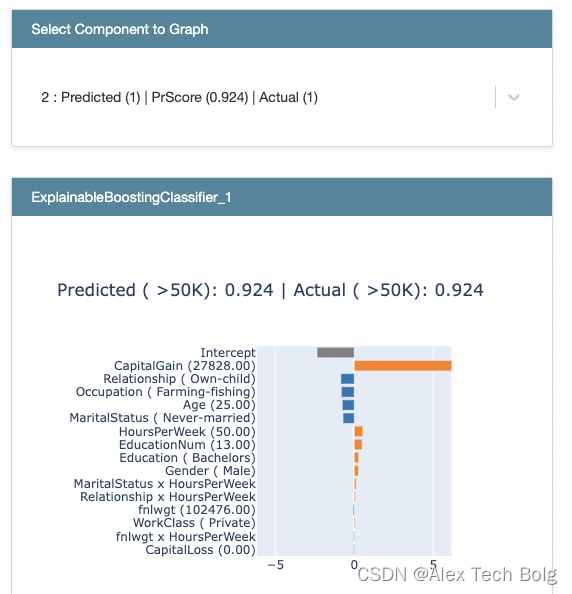
- 特征后面括号内的是具体的特征值
训练Blackbox模型
- 将PCA和Random Forest结合在一起,整体当做一个黑箱
from sklearn.ensemble import RandomForestClassifier
from sklearn.decomposition import PCA
from sklearn.pipeline import Pipeline
# We have to transform categorical variables to use sklearn models
X_enc = pd.get_dummies(X, prefix_sep='.')
feature_names = list(X_enc.columns)
y = df[label].apply(lambda x: 0 if x == " <=50K" else 1)
# Turning response into 0 and 1
X_train, X_test, y_train, y_test = train_test_split(X_enc, y, test_size=0.20, random_state=seed)
#Blackbox system can include preprocessing, not just a classifier!
pca = PCA()
rf = RandomForestClassifier(n_estimators=100, n_jobs=-1)
blackbox_model = Pipeline([('pca', pca), ('rf', rf)])
blackbox_model.fit(X_train, y_train)
解释Blackbox模型
- 使用lime来解释整体的blackbox_model
from interpret.blackbox import LimeTabular
from interpret import show
lime = LimeTabular(predict_fn=blackbox_model.predict_proba, data=X_train, random_state=seed)
lime_local = lime.explain_local(X_test[:5], y_test[:5])
show(lime_local)
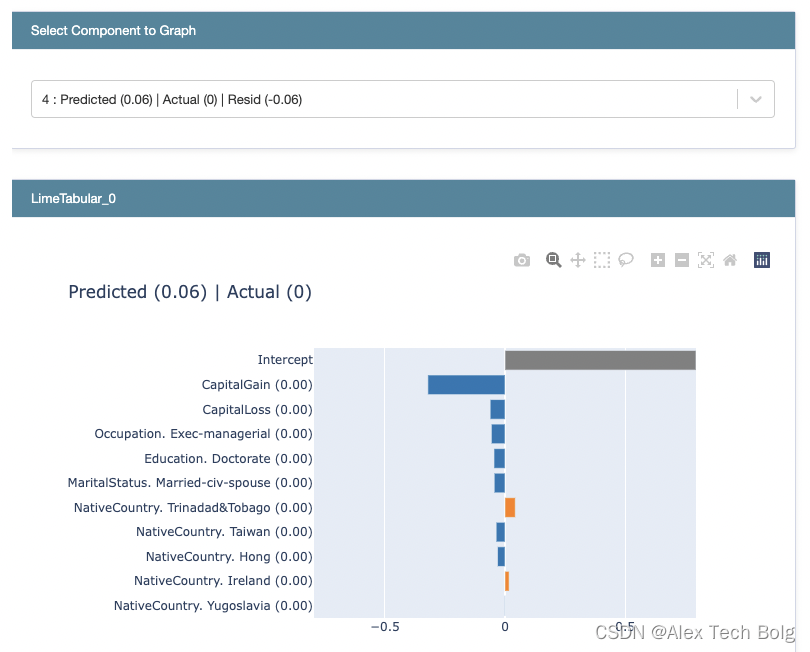
>> X_test.iloc[0]["CapitalGain"]
>> 0
-
LIME可以得到每一个样本的解释,每个特征后面是对应的特征值
-
关于LIME模型讲解:https://blog.csdn.net/qq_41103204/article/details/125801073
Reference
- https://interpret.ml/
- https://www.pianshen.com/article/52201418251/
- https://github.com/interpretml/interpret/issues/21
- https://github.com/interpretml/interpret/issues/12
最后
以上就是受伤汽车最近收集整理的关于可解释机器学习- InterpretML的使用|interpretable machine learning- InterpretML tutorial代码示例Introduction代码示例Reference的全部内容,更多相关可解释机器学习-内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复