一、前言
最近在看spring源码,发现之前看的很多细节已经忘了,于是决定在看源码的过程中也把主要的流程用博客记载下来,希望自己能坚持下来吧。
spring已经发展很久,整个体系已经变得很庞大了。为了能更好的把源码看下去,我决定从最基础也是最核心的IOC开始切入,并且从最原始的xml解析开始看。面对这样一个庞大的体系,我认为从最原始的方式开始学习,才能更好的看懂它的设计和实现思路。
这一系列文章会默认你对于spring的使用已经熟悉,并且不抗拒读源码。因为很多的文字会在源码片段上注释-对于源码解析的文章,我暂时也找不到更好的表述方法了。

二、一个简单的示例
首先我们配置一个bean:
对应的类:
public class AccountServiceImpl implements AccountService { @Override public String queryAccount(String id) { return null; }}测试类:
@Testpublic void test1() { applicationContext = new ClassPathXmlApplicationContext("spring.xml"); AccountService bean = applicationContext.getBean(AccountService.class); System.out.println(bean);}运行结果:
com.xiaoxizi.spring.service.AccountServiceImpl@3e78b6a5三、源码解析
1. beanDefinition注册流程
我们知道,spring容器启动的逻辑在refresh()方法里面。所以,话不多说,直接点进refresh()逻辑,具体位置是 org.springframework.context.support.AbstractApplicationContext#refresh
public void refresh() throws BeansException, IllegalStateException { synchronized (this.startupShutdownMonitor) { prepareRefresh(); // 本篇博文主要讲这个逻辑 ConfigurableListableBeanFactory beanFactory = obtainFreshBeanFactory(); prepareBeanFactory(beanFactory); ...}本篇博文主要讲xml解析的逻辑,暂时我们只关注 obtainFreshBeanFactory()
protected ConfigurableListableBeanFactory obtainFreshBeanFactory() { refreshBeanFactory(); return getBeanFactory();}继续往下跟refreshBeanFactory(),实际上方法位置在org.springframework.context.support.AbstractRefreshableApplicationContext#refreshBeanFactory
@Overrideprotected final void refreshBeanFactory() throws BeansException { if (hasBeanFactory()) { destroyBeans(); closeBeanFactory(); } try { // 创建一个beanFactory DefaultListableBeanFactory beanFactory = createBeanFactory(); beanFactory.setSerializationId(getId()); customizeBeanFactory(beanFactory); // 加载所有的BeanDefinitions,实际解析xml的位置 loadBeanDefinitions(beanFactory); synchronized (this.beanFactoryMonitor) { this.beanFactory = beanFactory; } } catch (IOException ex) { throw new ApplicationContextException("I/O error parsing bean definition source for " + getDisplayName(), ex); }}继续往下 org.springframework.context.support.AbstractXmlApplicationContext#loadBeanDefinitions(org.springframework.beans.factory.support.DefaultListableBeanFactory)
protected void loadBeanDefinitions(DefaultListableBeanFactory beanFactory) throws BeansException, IOException { // 这里使用了委托模式,把BeanDefinition的解析委托给了 BeanDefinitionReader // 由于我们当前是解析xml,所以是委托给Xml...Reader。合理想象,注解方式将会委托给Anno...Reader // 需要注意的是,我们把beanFactory引用传递给了Reader,之后会用到 XmlBeanDefinitionReader beanDefinitionReader = new XmlBeanDefinitionReader(beanFactory);// ... 为BeanDefinitionReader设置了一些不重要的属性,略过。 // 加载BeanDefinition loadBeanDefinitions(beanDefinitionReader);}// XmlBeanDefinitionReader对应构造器,注意 beanFactory 是作为 BeanDefinitionRegistry 传入的public XmlBeanDefinitionReader(BeanDefinitionRegistry registry) { super(registry);}protected void loadBeanDefinitions(XmlBeanDefinitionReader reader) throws BeansException, IOException { Resource[] configResources = getConfigResources(); if (configResources != null) { // 可以看到,是委托给Reader来加载BeanDefinition的 reader.loadBeanDefinitions(configResources); } // 配置文件位置实际上就是我们 new ClassPathXmlApplicationContext("xxx") 时传入的 String[] configLocations = getConfigLocations(); if (configLocations != null) { // 可以看到,是委托给Reader来加载BeanDefinition的 reader.loadBeanDefinitions(configLocations); }}经过一系列解析、包装、加载逻辑之后... org.springframework.beans.factory.xml.XmlBeanDefinitionReader#doLoadBeanDefinitions
protected int doLoadBeanDefinitions(InputSource inputSource, Resource resource) throws BeanDefinitionStoreException { try { // 配置文件的输入流被加载成了Document --> XML解析知识,详细可搜素 SAX解析 Document doc = doLoadDocument(inputSource, resource); // 解析并注册BeanDefinitions int count = registerBeanDefinitions(doc, resource); if (logger.isDebugEnabled()) { logger.debug("Loaded " + count + " bean definitions from " + resource); } return count; }// 异常处理,省略...}public int registerBeanDefinitions(Document doc, Resource resource) throws BeanDefinitionStoreException { // 又来了,熟悉的委托模式,Document的解析被委托给了BeanDefinitionDocumentReader BeanDefinitionDocumentReader documentReader = createBeanDefinitionDocumentReader(); int countBefore = getRegistry().getBeanDefinitionCount(); // 委托documentReader解析注册BeanDefinition,注意这里传入了一个 XmlReaderContext documentReader.registerBeanDefinitions(doc, createReaderContext(resource)); return getRegistry().getBeanDefinitionCount() - countBefore;}// 可以看到XmlReaderContext的构造器传入了当前类-XmlBeanDefinitionReader// 而当前类持有BeanDefinitionRegistry,所以XmlReaderContext中持有了一个BeanDefinitionRegistrypublic XmlReaderContext createReaderContext(Resource resource) { return new XmlReaderContext(resource, this.problemReporter, this.eventListener, this.sourceExtractor, this, getNamespaceHandlerResolver());}细看DocumentReader解析过程 org.springframework.beans.factory.xml.DefaultBeanDefinitionDocumentReader#doRegisterBeanDefinitions
protected void doRegisterBeanDefinitions(Element root) { // 代理的逻辑,我们暂时不看 BeanDefinitionParserDelegate parent = this.delegate; this.delegate = createDelegate(getReaderContext(), root, parent); if (this.delegate.isDefaultNamespace(root)) { // ... }// 解析xml之前的钩子,暂时是空实现 preProcessXml(root); // 解析逻辑 parseBeanDefinitions(root, this.delegate); // 解析xml之前的钩子,暂时是空实现 postProcessXml(root); this.delegate = parent;}protected void parseBeanDefinitions(Element root, BeanDefinitionParserDelegate delegate) { // 判断是否是默认的命名空间 if (delegate.isDefaultNamespace(root)) { NodeList nl = root.getChildNodes(); for (int i = 0; i < nl.getLength(); i++) { Node node = nl.item(i); if (node instanceof Element) { Element ele = (Element) node; if (delegate.isDefaultNamespace(ele)) { // 解析默认标签 parseDefaultElement(ele, delegate); } else { // 可以看到代理主要进行自定义标签的解析 - CustomElement delegate.parseCustomElement(ele); } } } } else { // 可以看到代理主要进行自定义标签的解析 - CustomElement delegate.parseCustomElement(root); }}这里解释一下 自定义标签、自定义命名空间、默认标签、默认命名空间的含义
我们先看默认标签的解析过程
private void parseDefaultElement(Element ele, BeanDefinitionParserDelegate delegate) { // 解析import标签,其实就是一个递归解析import导入的xml的过程 if (delegate.nodeNameEquals(ele, IMPORT_ELEMENT)) { importBeanDefinitionResource(ele); } // 解析alias标签,一般很少用这个功能,我们不看这个逻辑 else if (delegate.nodeNameEquals(ele, ALIAS_ELEMENT)) { processAliasRegistration(ele); } // 解析bean标签,重头戏 else if (delegate.nodeNameEquals(ele, BEAN_ELEMENT)) { processBeanDefinition(ele, delegate); } // 解析beans标签, 其实就是递归走了一次解析流程 else if (delegate.nodeNameEquals(ele, NESTED_BEANS_ELEMENT)) { // 这个方法眼熟吧?实际上我们就是从这个方法跟下来的 doRegisterBeanDefinitions(ele); }}protected void processBeanDefinition(Element ele, BeanDefinitionParserDelegate delegate) { // 具体的解析过程,将会把bean标签解析并封装到BeanDefinition中 BeanDefinitionHolder bdHolder = delegate.parseBeanDefinitionElement(ele); if (bdHolder != null) { // 对bean标签解析出来的BeanDefinition进行装饰,用的很少 bdHolder = delegate.decorateBeanDefinitionIfRequired(ele, bdHolder); try { // Register the final decorated instance. // 注册BeanDefinition BeanDefinitionReaderUtils.registerBeanDefinition(bdHolder, getReaderContext().getRegistry()); } ... }}2. bean标签解析
再正真解析bean标签前,我们先看一下spring的bean标签都有哪些属性和默认子标签
一些描述 参数类型,用于缺人唯一的方法 逐一说一下bean标签中属性作用:
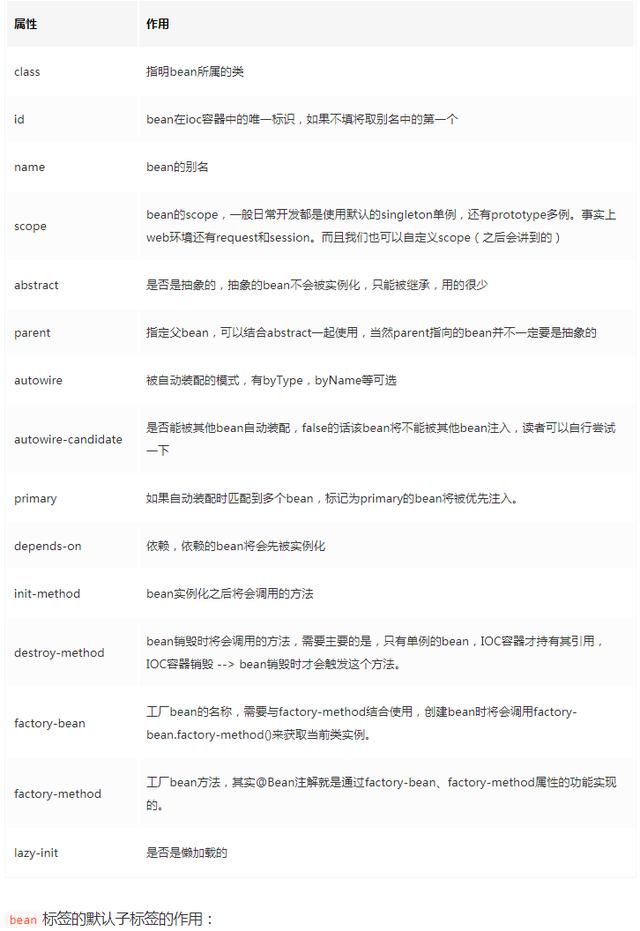
bean标签的默认子标签的作用:

继续往下看解析过程org.springframework.beans.factory.xml.BeanDefinitionParserDelegate#parseBeanDefinitionElement
public BeanDefinitionHolder parseBeanDefinitionElement(Element ele, @Nullable BeanDefinition containingBean) { String id = ele.getAttribute(ID_ATTRIBUTE); String nameAttr = ele.getAttribute(NAME_ATTRIBUTE);// 处理别名 List aliases = new ArrayList<>(); if (StringUtils.hasLength(nameAttr)) { String[] nameArr = StringUtils.tokenizeToStringArray(nameAttr, MULTI_VALUE_ATTRIBUTE_DELIMITERS); aliases.addAll(Arrays.asList(nameArr)); }// 默认id为beanName String beanName = id; if (!StringUtils.hasText(beanName) && !aliases.isEmpty()) { // 如果不配置id,将会取第一个别名当做beanName beanName = aliases.remove(0); // ... } if (containingBean == null) { // 校验beanName、alias是否重复 // 实际上有一个set用来存所以用过的name,避免重复 BeanDefinitionParserDelegate#usedNames checkNameUniqueness(beanName, aliases, ele); }// 要解析元素了,解析xml获取一个beanDefinition AbstractBeanDefinition beanDefinition = parseBeanDefinitionElement(ele, beanName, containingBean); if (beanDefinition != null) { // ... 跳过一些逻辑 String[] aliasesArray = StringUtils.toStringArray(aliases); // 把beanDefinition封装成Holder return new BeanDefinitionHolder(beanDefinition, beanName, aliasesArray); } return null;}解析方法parseBeanDefinitionElement中我们将把xml bean标签中的信息解析并封装到 一个BeanDefinition中,而之后(初始化流程),我们将会根据BeanDefinition中的属性来创建bean实例。现在,先让我们看一下这个BeanDefinition的结构:
// 默认使用的是 GenericBeanDefinitionpublic class GenericBeanDefinition extends AbstractBeanDefinition { // 这个子类中只有一个parentName属性,明显对应bean标签的parent属性 @Nullable private String parentName;}// 找父类,基本可以看到属性和bean标签的内容是一一对应的,不过meta子标签的信息还在父类里面public abstract class AbstractBeanDefinition extends BeanMetadataAttributeAccessorimplements BeanDefinition, Cloneable { @Nullableprivate volatile Object beanClass;@Nullableprivate String scope = SCOPE_DEFAULT;private boolean abstractFlag = false;@Nullableprivate Boolean lazyInit;private int autowireMode = AUTOWIRE_NO;private int dependencyCheck = DEPENDENCY_CHECK_NONE;@Nullableprivate String[] dependsOn;private boolean autowireCandidate = true;private boolean primary = false;// qualifier子标签信息private final Map qualifiers = new LinkedHashMap<>();@Nullableprivate Supplier> instanceSupplier;private boolean nonPublicAccessAllowed = true;private boolean lenientConstructorResolution = true;@Nullableprivate String factoryBeanName;@Nullableprivate String factoryMethodName;// constructor-arg 子标签的信息@Nullableprivate ConstructorArgumentValues constructorArgumentValues;// property子标签的信息@Nullableprivate MutablePropertyValues propertyValues;// lookup-method、replaced-method子标签的信息private MethodOverrides methodOverrides = new MethodOverrides();@Nullableprivate String initMethodName;@Nullableprivate String destroyMethodName; @Nullableprivate String description;// 加载这个beanDefinition的资源 -> 哪个xml@Nullableprivate Resource resource;}// BeanMetadataAttributeAccessor extends AttributeAccessorSupportpublic abstract class AttributeAccessorSupport implements AttributeAccessor, Serializable {// 保存beanDefinition的元数据信息/** Map with String keys and Object values. */好,我们继续往下解析bean标签
public AbstractBeanDefinition parseBeanDefinitionElement( Element ele, String beanName, @Nullable BeanDefinition containingBean) {// ... // 获取class属性 String className = null; if (ele.hasAttribute(CLASS_ATTRIBUTE)) { className = ele.getAttribute(CLASS_ATTRIBUTE).trim(); } // 获取parent属性 String parent = null; if (ele.hasAttribute(PARENT_ATTRIBUTE)) { parent = ele.getAttribute(PARENT_ATTRIBUTE); } try { // 创建了一个BeanDefinition,感兴趣的同学可以跟一下,实际上就是创建了一个 // GenericBeanDefinition 并且把 parent set 进去了 AbstractBeanDefinition bd = createBeanDefinition(className, parent);// 解析bean标签上的属性 scope, autowrite等 // 感兴趣的同学可以跟一下,就是把值从xml中解析出来塞到beanDefinition而已 parseBeanDefinitionAttributes(ele, beanName, containingBean, bd); // description属性 bd.setDescription(DomUtils.getChildElementValueByTagName(ele, DESCRIPTION_ELEMENT)); // 解析meta子标签 parseMetaElements(ele, bd); // 解析lockup-method子标签 parseLookupOverrideSubElements(ele, bd.getMethodOverrides()); // 解析replaced-method子标签 parseReplacedMethodSubElements(ele, bd.getMethodOverrides());// 解析constructor-arg子标签 parseConstructorArgElements(ele, bd); // 解析property子标签 parsePropertyElements(ele, bd); // 解析qualifier子标签 parseQualifierElements(ele, bd); bd.setResource(this.readerContext.getResource()); bd.setSource(extractSource(ele)); return bd; } // ... return null;}// 因为解析的流程其实都差不多,这边简单挑几个有代表性的看一下public void parseMetaElements(Element ele, BeanMetadataAttributeAccessor attributeAccessor) { NodeList nl = ele.getChildNodes(); for (int i = 0; i < nl.getLength(); i++) { Node node = nl.item(i); // 循环所有bean标签的子标签,找到mate标签 if (isCandidateElement(node) && nodeNameEquals(node, META_ELEMENT)) { Element metaElement = (Element) node; String key = metaElement.getAttribute(KEY_ATTRIBUTE); String value = metaElement.getAttribute(VALUE_ATTRIBUTE); // 封装成BeanMetadataAttribute BeanMetadataAttribute attribute = new BeanMetadataAttribute(key, value); attribute.setSource(extractSource(metaElement)); // 记住我们的beanDefinition是继承BeanMetadataAttributeAccessor的 // 所以这里其实也是放到beanDefinition中了 attributeAccessor.addMetadataAttribute(attribute); } }}public void parseLookupOverrideSubElements(Element beanEle, MethodOverrides overrides) { NodeList nl = beanEle.getChildNodes(); for (int i = 0; i < nl.getLength(); i++) { Node node = nl.item(i); // 循环所有bean标签的子标签,找到lockup-method标签 if (isCandidateElement(node) && nodeNameEquals(node, LOOKUP_METHOD_ELEMENT)) { Element ele = (Element) node; String methodName = ele.getAttribute(NAME_ATTRIBUTE); String beanRef = ele.getAttribute(BEAN_ELEMENT); // 封装成LookupOverride LookupOverride override = new LookupOverride(methodName, beanRef); override.setSource(extractSource(ele)); overrides.addOverride(override); } }}// 我们这里看一下MethodOverrides的结构// 首先MethodOverrides是在beanDefinition创建的时候就初始化的private MethodOverrides methodOverrides = new MethodOverrides();public class MethodOverrides {// 其实就是一个MethodOverride列表private final Set overrides = new CopyOnWriteArraySet<>();// ...}// 继续看看MethodOverridepublic abstract class MethodOverride implements BeanMetadataElement {// 被代理/重写的方法名private final String methodName;// 是否是重载的方法 - 重载的方法处理起来要复杂点private boolean overloaded = true;// ...}// MethodOverride只有两个子类,LookupOverride 和 ReplaceOverride,看名字大家都知道对应哪个标签了public class LookupOverride extends MethodOverride { // 提供重写逻辑的bean的名称private final String beanName; // 可以看到,这个属性我们在解析xml的时候没有用到。 // 这个应该是用来支持注解@Lockup的,因为这个功能用的很少,我也没去深究,不过字段的含义还是很好理解的private Method method;}public class ReplaceOverride extends MethodOverride {// 提供重写逻辑的bean的名称private final String methodReplacerBeanName;// 之前有说过replaced-method是用于目标方法有重载的情况,这个参数类型列表就是用来区分重载的方法的 // 也是replaced-method标签的子标签arg-type中定义的private List typeIdentifiers = new LinkedList<>();}那么至此,我们的一个默认的bean标签就解析完毕了,并且把所有的信息封装到了一个BeanDefinition实例中,然后这个beanDefinition将会注册到我们的IOC容器中去,为下一步生成实例做准备。org.springframework.beans.factory.xml.DefaultBeanDefinitionDocumentReader#processBeanDefinition
protected void processBeanDefinition(Element ele, BeanDefinitionParserDelegate delegate) { // 具体的解析过程,将会把bean标签解析并封装到BeanDefinition中 BeanDefinitionHolder bdHolder = delegate.parseBeanDefinitionElement(ele); if (bdHolder != null) { // 对bean标签解析出来的BeanDefinition进行装饰,用的很少,但此处的是个spi很重要 // 这里下一期再讲 bdHolder = delegate.decorateBeanDefinitionIfRequired(ele, bdHolder); try { // Register the final decorated instance. // 注册BeanDefinition BeanDefinitionReaderUtils.registerBeanDefinition(bdHolder, getReaderContext().getRegistry()); } ... }}我们主要看一下注册beanDefinition的过程
public static void registerBeanDefinition( BeanDefinitionHolder definitionHolder, BeanDefinitionRegistry registry) throws BeanDefinitionStoreException { String beanName = definitionHolder.getBeanName(); // 注册bean registry.registerBeanDefinition(beanName, definitionHolder.getBeanDefinition()); String[] aliases = definitionHolder.getAliases(); if (aliases != null) { for (String alias : aliases) { // 注册别名 registry.registerAlias(beanName, alias); } }}public void registerBeanDefinition(String beanName, BeanDefinition beanDefinition) throws BeanDefinitionStoreException {// ... 这里去除掉了大部分的分支判断和异常处理逻辑,有兴趣的同学可以自行看一下 // registerBeanDefinition的主要逻辑其实是以下两段 // 将当前beanDefinition放入两个容器 this.beanDefinitionMap.put(beanName, beanDefinition); this.beanDefinitionNames.add(beanName); // 这里是把当前bean从 manualSingletonNames 中删除,简单看了下逻辑 // 对于通过 DefaultListableBeanFactory#registerSingleton(String beanName, Object singletonObject) // 直接注册到IOC容器中的单例bean,因为没有对应的beanDefinition,name相应的beanName会被记录到这个set // 而如果我们解析xml中获取到了相应的beanDefinition,就会将其从set中移除 // 这个逻辑可以不看,不是主流程 removeManualSingletonName(beanName);}四、总结
spring xml bean标签的解析就完整了,其实简单来讲,就是通过一系列手段,拿到xml bean标签中配置的各种属性,封装成一个BeanDefinition对象,然后把这个对象存到我们IOC容器的 beanDefinitionMap、beanDefinitionNames中。这两个容器在之后的bean实例创建的过程中将会用到。
作者:小希子
链接:https://juejin.im/post/5efd905bf265da22df3cc44a
来源:掘金
最后
以上就是暴躁花生最近收集整理的关于spring 源码深度解析_Spring源码解读 - IOC xml配置解析 - bean标签的解析一、前言二、一个简单的示例三、源码解析1. beanDefinition注册流程2. bean标签解析四、总结的全部内容,更多相关spring内容请搜索靠谱客的其他文章。








发表评论 取消回复