代码优化
我们的网页由结构层,表现层和行为层三部分组成,而每一层对应的实现代码分别为HTML(负责描绘出内容的结构),CSS(负责“如何显示有关内容”),JavaScript(负责“内容应如何对事件做出反应”)。针对每一层就行代码优化,可以提升我们的网页性能。
HTML优化
针对HTML的优化,大致围绕以下几点:
1.减少iframes的使用
在日常开发中我们应当避免使用或者极大程度上减少iframes的使用。因为iframes所加载的文档会阻塞主文档的加载(可以改为延迟加载iframe),此外通过给iframe文档生成元素,其开销大于主文档中生成元素的操作。
2.压缩空白符和删除多余的注释
尽量减少HTML文档的大小,如果你使用的是webpack等构建工具,这个可以很好实现。
3.避免节点深层级嵌套
对DOM元素的结构不要为了嵌套而进行嵌套,尽量减少元素之间的嵌套,深层级嵌套会增加解析时间。例如React中提供Fragment,Vue中提供了template来减少过多的嵌套。
4.删除元素默认属
不同的DOM元素在不同的浏览器中往往会有不同的默认属性,导致表现也不相同。应当删除这些差异,保证所有浏览器中表现一致,消除默认属性给开发带来的困扰。推荐一个好的实现:normalize.css
5.避免table布局
table布局是一个古老的布局,不多说,除了祖传项目中,劝你不要用这个布局。
6.CSS和JavaScript尽量外链
尽量减少行间CSS和JavaScript代码的书写(还是有特殊操作的,比如首屏渲染时,loading动画的实现)。此外使用link加载CSS的时候尽量放在head标签里面,而JavaScript的加载尽量放在文档最底部,如果有特殊情况可以使用async和defer(之前说过,JavaScript的加载会阻塞渲染)。
CSS优化
针对CSS的优化,很早之前我们还是停留在CSS选择器选择上面,但是随着浏览器的发展CSS选择器对性能的影响已经很小了(意思是:还是要注意下,咳咳咳)。
除此以外,CSS的优化大致围绕以下几点:
1.降低CSS对渲染的阻塞
尽早的去加载CSS,可以尽早的完成CSS的解析。同时避免加载当前页面没有使用到的CSS代码。(React,Vue等都已经实现路由懒记载方案,用于加载当前路由所需的CSS代码,也就是css按需加载)。
2.利用GPU完成动画
关于元素的几何属性操作,尽量使用transform完成。
3.使用contain属性
直接去看这个地址吧,什么情况下使用请自行进行搜索引擎编程。(实在是没什么好讲的)
使用font-display属性
文章后面会有详解
JavaScript优化
前面的HTML和CSS代码的优化只是开胃小菜,大菜还的看JavaScript。这一节我们来看看如何如何JavaScript代码,并简单的介绍一下大名鼎鼎的V8引擎,看看从V8的编译原理中我们能得到哪些优化手段。
JavaScript的开销和如何缩短解析时间
同大小下,JavaScript的加载,编译解析到最后的执行,远远大于HTML,CSS,图片等资源。所以先看一下JavaScript的开销到底在哪儿。
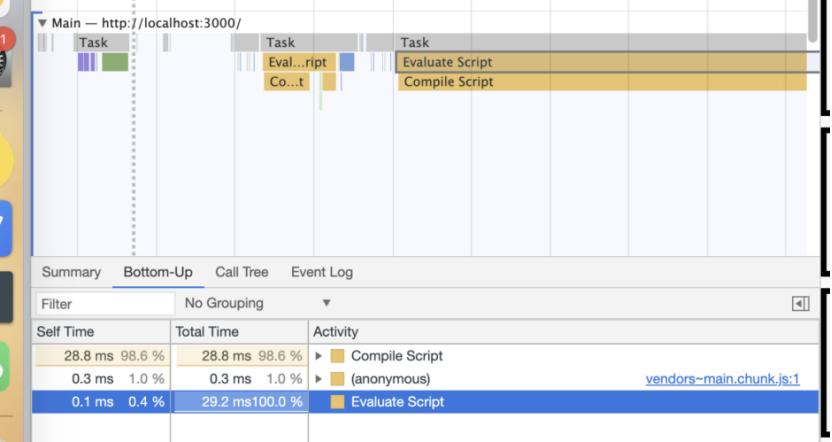
上图可以清楚看出JavaScript在相关阶段的耗时时间。
所以从大体上来说我们需要做的就是减少各个阶段的耗时。
从加载整体上我们需要做到以下几点:
- 代码拆分(Code splitting)
- 按需加载
- 树摇(Tree shaking)代码减重
如果你使用的是webpack等构建工具,那么可以很好的实现,如果不是,那么推荐你使用构建工具来开发项目,用了的人都说好。
从解析执行整体上来说,我们需要减少主线程工作量:
-
避免长任务(long task)
长任务会过多的占用每一帧处理各种任务的时间,会导致页面卡顿,其他任务无法快速相应的问题。
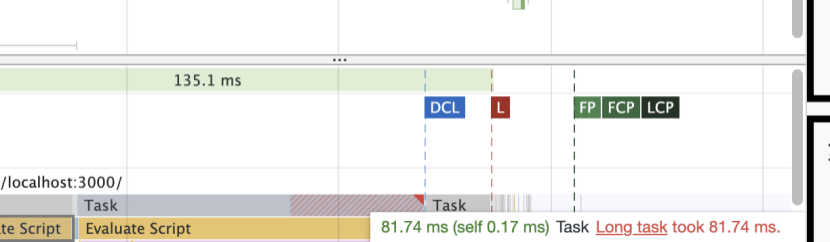
在performance面板主线程中如果Task右上角有红色的三角形,那么该任务就是一个长任务。 -
避免超过1KB的行间脚本
所谓行间脚本就是用一个script标签包裹的javaScript代码,浏览器引擎是无法针对这类JavaScript脚本进行优化的,如果你的行间脚本越大,那么解析的就越久。 -
使用requestAnimationFrame和requestidlecallback)进行任务调度
了解V8
正如本节开始之前所说,对于V8我们只是简单了解一下,并不是从头到位讲什么是V8(能力不够,哎诶…)。
请记住V8(本身是一个虚拟机)是一个解析编译javaScript的引擎。目前知道这里就行了(如果你还不是一个Node的高玩,手动狗头和滑稽)。
V8的内存限制
内存泄漏也是面试经常问到的,确实这个很重要,但是针对于网页来说,不用过多担心,因为我们访问一个网站基本上就是用完即走(关闭浏览器)只要不是网站的开发人员故意为之,那么基本就不会出现内存泄漏的问题。
V8中对内存的使用有着明确的限制:64位系统下约为1.4GB,32位系统下约为0.7GB。JavaScript对象基本上都是通过V8自己的方式来进行分配和管理的,这套管理机制在浏览器应有场景下绰绰有余(所以不必太过于担心),但是你是一个名Node开发工程师,那就不太行(滑稽),但是还是有相应的解决办法的。
至于V8为什么要采用这种限制,是因为V8最初就是为浏览器而设计的,不太可能用到大量内存的场景。V8的限制值已经够网页使用了。深一点的原因即使V8的垃圾回收机制的限制:以1.5GB的垃圾回收堆内存为例,V8做一次小的垃圾回收需要50ms以上,做一次非增量式的垃圾回收需要1秒以上,在垃圾回收期间,JavaScript线程暂停执行,应用的性能和响应的能力会直线下降,所以选择限制了内存的使用。(无奈之举)
V8的垃圾回收机制
V8的垃圾回收策略主要基于分代式垃圾回收机制,这是由于对象的生命周期长短不一,现代的垃圾回收算法按照对象的存活时间将内存的垃圾回收进行不同的分代,针对不同的分代的内存使用更高效的算法。
- V8的内存分代
V8中将内存分为新生代和老生代两代:

新生代中的对象为存活时间较短的对象,老生代中的对象为存活时间较长或常驻内存的对象。V8堆内存的是由新生代的内存空间和老生代的内存空间相加得到的。默认情况下,V8堆内存的最大值在64为系统上为1464M,32位系统上则为732M。 - Scavenge算法
新生代中的对象主要通过Scavenge算法进行垃圾回收。Scavenge具体实现中主要使用了Cheney算法。先看一下该算法下,V8堆内存的分布:
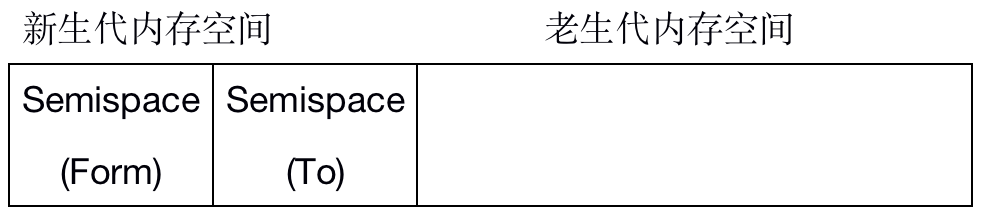
Cheney算法采用复制的方式实现垃圾回收,其把新生代堆内存一分为二,形成两个semisapce空间,Form空间代表正在使用的堆内存,To空间代表闲置状态。分配对象的时候先是在Form空间进行分配,当开始垃圾回收的时候,检查Form空间中的存活对象并将其复制到To空间,将非存活对象进行释放。完成复制以后,将Form和To两个空间的角色完成翻转(即原先的Form空间变成To空间,To空间变成Form空间)。当一个对象经过多次复制翻转以后还是存活状态,那么它将会被认为生命周期较长的对象,则会被移动到老生代中,采用新的算法进行管理,这一个过程成为晋升(晋升需要满足两个条件,该对象是否被Scavenge算法操作过,To空间所使用占比是否超过25%:To空间使用超过25%的话,会影响后续内存的分配,如果都满足的话,这个对象将会移动到老生代中)。
Scavenge是典型的牺牲空间换取时间的算法(因为新生代中只有一半的堆内存的到使用),所以无法大规模地应用到所有的垃圾回收中,但是由于新生代中对象的生命周期较短,非常适合这个算法。
Mark-Sweep和Mark-Compact
老生代中主要采用Mark-Sweep和Mark-Compact算法来完成来及回收的。
Mark-Sweep分为标记和清除两个阶段,在标记阶段中会遍历老生代堆内存中所有存活的对象,在清除阶段,只清除没有被标记的对象。下面是Mark-Sweep在老生代空间标记后的示意图:

黑色部分代表标记为死亡的对象。
其实在结合Scavenge算法可以看出,Scavenge中只复制存活的对象,而Mark-Sweep只标记死亡的对象。恰恰新生代中存活对象只占很少部分,在老生代中死亡对象也只占小部分,所以这两种方式能够高效处理垃圾回收。
从中也可以看出,Mark-Sweep在进行一次标记清除后,内存空间会出现不连续的状态,形成了内存空间碎片,会对后续的内存分配造成问题,如果后面出现需要分配一个大对象的情况,那么此时的碎片可能都无法满足,从而提前触发垃圾回收,造成一次比不要的回收。
为了解决Mark-Sweep带来的内存碎片问题,V8中在老生代中还使用了Mark-Compact算法。该算法也会给对象打上死亡标记,但是其会触发一个整理过程。在对象被标记死亡后,会将活动中的对象往一端移动,移动完成后,直接清理掉边界以外的内存,实现垃圾回收。
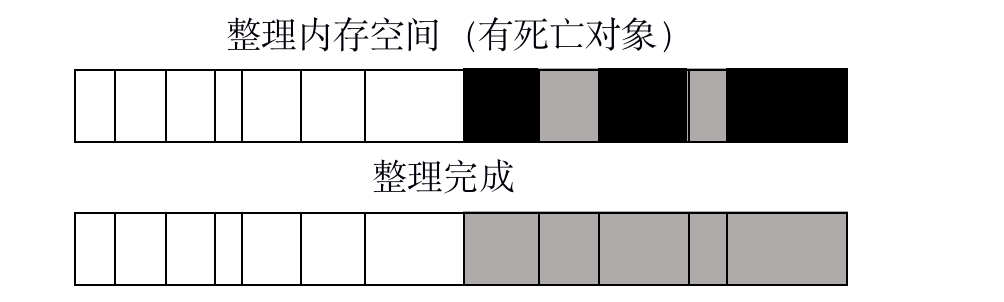
白色代表存活对象,黑色代表被标记的死亡对象,浅色格式代表存活对象移动后留下的空洞。
可以看出经过整理以后,很好地解决了Mark-Sweep带来的内存碎片问题。
由于Mark-Compact需要移动对象,其速度相对于上面其他两种是最慢的,所以该算法只有在新生代对象晋升到老生代空间,空间不足以给对象分配时才会使用该算法。
高效使用内存
先通过一个代码了解一下最基本的内存回收过程:
var foo = function () {
var local = {};
}
foo函数在每次调用的时候就会创建一个作用域,函数执行完成以后,作用域销毁,同时在该作用域声明的局部变量也会跟着作用域的销毁而销毁。对于local这个局部变量引用的对象可以看出其存活时间非常短,所以其会被分配在新生代中的Form空间,在作用域销毁以后,该对象会在下次来及回收时被释放。
老生代对象的主动释放
我们要想一下哪些操作会产生老生代对象,根据分配在老生代空间的对象的特点来看,我们可以知道全局(如果网页中就是window,Node指的是global)定义的变量和闭包中才会产生常驻内存的对象。
如果要等待老生代对象被动释放,在网页中只有关闭网页(javaScript的执行线程退出),Node中则相关进程退出,这些对象才能得到释放。
在开发中我们可以主动去释放这些变量:
window.__name = 'name';
delete window.__name;
// 或者
window.__name = null;
通过delete操作符和重新赋值的方式都可以主动去释放老生代对象,但是delete操作有可能干扰V8的优化,所以推荐使用重新赋值的方式解除老生代对象的引用。
闭包通常会跟内存泄漏联系在一起,其实实际上闭包不一定会产生内存泄漏。还是说一下什么是闭包:外部作用域访问内部作用域中变量的方法叫做闭包。
所以来看看闭包是如何实现让对象常驻内存的:
var foo = function () {
var local = {}
return function () {
console.log(local);
}
}
var bar = foo();
bar();
上述代码中,foo函数执行的时候声明了一个作用域(该作用域称之为内部作用域),其内部声明了local变量(现在在新生代中),返回了一个匿名函数(称之为中间函数),匿名函数有访问local变量的能力(也只能通过这个中间函数访问local,中间函数形成的作用域叫做外部作用域),然后函数结束完。
还记得我们上面那个内存回收的基本示例吗?应该是foo执行完以后,作用域就释放了对吧。但是我们定义了变量bar接受了这个中间函数,也就是变量bar引用了中间函数。这个时候就出现了变化,bar的存在(我们并没有对bar重新赋值或者delete操作)使得中间函数引用存在,所以中间函数作用域不会被销毁,中间函数拥有访问local的能力,那么内部变量local所在的作用域也不会被销毁(大哥,你不能死啊,你死了local就不在了,别人会说我javaScript闭包是唬人的拉),那么local对象也不会被释放。
所以在经过几次垃圾回收以后,新生代中发现这堆玩意儿还存在,好吧让你晋升到老生代中去,至此闭包实现了对象常驻内存。只有中间函数不再被引用后,相应的对象才会被逐渐释放。(所以面试中有关于闭包和内存相关的问题,知道该怎么回答了吧。手动狗头,咳咳咳)
V8编译原理
简单对V8的编译原理和过程介绍以下:
源码=》抽象语法树(AST)=》字节码(byteCode)=》机器码
在编译过程中会进行优化,但是运行时候的可能会产生反优化(应当避免)。
V8对JavaScript作出的优化
现在我们来看看V8到底作出了哪些优化(包括但不限于以下介绍):
- 脚本流:V8会对JavaScript进行边下载先解析的流式处理。
- 缓存字节码:当JavaScript被解析成字节码的时候,会对经常使用到的字节码进行缓存,下次使用加快。
- 懒解析(lazy parsing):主要是针对函数进行懒解析,当函数真正用到的时候再去解析,整体解析提速。
- 优化隐藏类(hide class)
- 垃圾回收机制(上面已经说过)
针对于懒解析(lazy parsing)与之对应的还有一个饥饿解析(eager parsing,编译过程中需要解析这个函数,运行时候不需要在解析)。如果你知道你定义的函数会立即被使用到,那么你可以通过代码V8使用饥饿解析:
var foo = (function () {
console.log('开启饥饿解析')
})
只需要将函数包裹在()内,V8就知道该怎么做了,注意这可不是自执行函数的写法哟。
隐藏类就是隐藏类型,从我们学习JavaScript开始就知道JavaScript中只有基本数据类型和引用数据类型,哪来的什么隐藏类型。这个隐藏类型是浏览器处理JavaScript时候使用的,了解隐藏类,我们可以在日常开发中合理使用隐藏类,避免隐藏类的调整,达到优化的效果。看一段代码:
class Person { // HC0
constructor(name, age) {
this.name = name; // HC1
this.age = age; // HC2
}
}
const xiaoming = new Person('小明', 23);
const xiaogang = new Person('小刚', 20);
在创建Person的时候会创建隐藏类HC0(名称不重要),
然后该给实例赋值name这个过程会创建HC1,同样对于age会创建HC2。现在已有了三个隐藏类,如果后续的创建按照隐藏类的顺序来执行的话,那么就会复用以上隐藏类达到优化效果。
在看一个反例:
var zhangsan = { name: '张三' }; // HC0
zhangsan.age = 24; // HC1
var lisi = { age: 20 }; // HC2
lisi.name = '李四'; // HC3
当我们创建张三的时候,指定了name属性创建了HC0,
然后添加age属性创建了HC1。但是创建lisi的时候,首先指定的是age属性,和zhangsan顺序不一样所有无法复用HC0,导致创建新HC2,之后给lisi指定了name属性,同样优化顺序的问题,创建了HC3。如果lisi的创建按照zhangsan的创建来的话,那么就会复用HC0和HC1,不会新建HC2和HC3。隐藏类的复用与创建隐藏类时候的顺序有关。
在看看上面的Person,我们在实例化其对象时,一定是可以复用相关隐藏类的(以相同的顺序初始化对象成员),可以得出在兼容性允许的情况下,尽量使用最新ECMAscript规范的JavaScript,其不仅仅是提供了新的特性,同时还让我们的代码越来越迎合V8。
具体代码的优化
下面我们来看看一些具体JavaScript代码优化(包括但不限于以下介绍)。
对象实例化后避免添加新属性
var lisi = { age: 20 };
lisi.name = '李四';
这段代码看起来没有问题,但实际上还是有问题,第一行我们对lisi进行了实例化,其age属性是In-object属性,访问它比较快,但是name属性现在Normal/Fase属性,存储在property store里面,需要通过描述数组去间接查找,访问速度较慢。
var lisi = {name:'李四',age:20} // good
尽量使用数组(Array)代替类数组(Array-like)
类数组结构类似于数组,其可以通过下标去访问内部元素,也有length属性,常见的类数组有arguments,DOM元素集合。如果要遍历类数组的话,一般我们会使用for循环。但是我们想在类数组上使用数组相关方法的时候,我们会进行一定hack:
var doms = document.getElementsByClassName('test');
Array.prototype.forEach.call(doms, (dom, index) => {
console.log(dom, index);
})
这种使用call来执行数组的forEach方法,没有在真实数组上使用forEach的效率高,所以需要把类数组转化成数组:
1.使用Array.from进行转换
doms = Array.from(doms);
使用数组的slice方法进行转换
doms = [].slice.call(doms) // or doms = [].slice.apply(doms)
使用展开元素符进行转换
doms = [...doms];
这里进行类数组转化的代价是比影响优化的代价小。
避免数组越界访问
对于数组越界访问不单单是得到undefined,而且数组在越界访问时,会沿着原型链去查找,这是无意义的消耗。
避免元素类型转换
这里元素类型转换就可能发生我们之前所有的V8中的反优化:
var add2arg = function (num1, num2) {
return num1 + num2;
}
const t0 = performance.now();
for (var i = 0; i < 10000; i++) {
add2arg(1, 2);
}
for (var i = 0; i < 10000; i++) {
add2arg(1, 2);
}
const t1 = performance.now();
console.log('执行时间:', t1 - t0);
这里的add2arg函数接受两个number类型的参数,在执行后,V8已经记住了其特性,对其作出优化。

现在新增一行代码:
var add2arg = function (num1, num2) {
return num1 + num2;
}
const t0 = performance.now();
for (var i = 0; i < 10000; i++) {
add2arg(1, 2);
}
add2arg(1, '2');
for (var i = 0; i < 10000; i++) {
add2arg(1, 2);
}
const t1 = performance.now();
console.log('执行时间:', t1 - t0);
现在我们在两个for循环中间加上了一行代码,改变第二个参数的类型,这里会导致两个问题,第一计算结果会被因为隐式类型转换,导致返回结果不正确;第二v8会针对此执行重新作出优化,触发反优化(add2arg之前已经优化过了,这里改变了元素类型,导致重新优化)。当执行第二个循环的时候又触发反优化,导致整体执行效率变低:

其实这种不小心篡改数据类型的情况经常发生,推荐使用TypeScript进行开发(用了都说好,也可以看出新的东西为什么会被人接受,其后面的设计是真的妙不可言,你以为你看到别人的设计在第三层,其实别人的设计在大气层。敢说之前打死你都不知道类型约束还能优化性能,而这一切在TS中是那么的自然)
避免全局变量
我们应当避免全局变量的声明,如果一定要使用的话请最少程度上声明全局变量:
window.name = 'render';
window.sayName = function () {
console.log(window.name);
}
可以给一个单独的命名空间,一个好的实践如下:
window.renderApplication = {
name: 'render',
sayName: function () {
console.log(this.name)
}
}
这样子不仅减少了老生代空间存在的对象,同时使用了命名空间还能有效防止后面修改之前定义的name属性和sayName方法。
避免全局查找
使用全局的变量和函数开销肯定要比局部的开销更大,因为要涉及到作用域链向上的查找:
function updateUI() {
var imgs = document.getElementsByTagName('img');
for (var i = 0; i < imgs.length; i++) {
imgs[i].title = document.title + "image" + i;
}
}
这段代码实现了动态修改img元素title属性的功能,但是当网页中图片很多的时候,那么document的引用就会执行多次或者上百次,但是当前函数作用域内是没有document的,所以会执行多次作用域链查找。
function updateUI() {
var imgs = document.getElementsByTagName('img');
var doc = document;
for (var i = 0; i < imgs.length; i++) {
imgs[i].title = doc.title + "image" + i;
}
}
进行如上修改以后,只会执行一次全局查找,改进了updateUI函数的性能。
避免with语句
with和函数类似的会创建额外的作用域,会导致全局查找,而且其内部的代码阅读性也会变差:
function updateBody() {
with (document.body) {
alert(tagName);
innerHTML = 'Hello world';
}
}
上面代码中,如果你不细心的话很难快速知道tagName和innerHTML属性是属于哪一个对象。
function updateBody() {
var body = document.body;
alert(body.tagName);
body.innerHTML = 'Hello world';
}
这段代码可阅读性比上面的要好,同时使用body将document.body存储在局部作用域内,避免了额外的全局查找。更详细解析请查看这里
避免不必要的属性查找
有时候我们需要获取浏览器地址中的相关参数,来做一些额外的操作:
var query = window.location.href.substring(window.location.href.indexOf("?"))
上述代码有两个问题,第一:当行代码太长,不利于阅读;第二:对于window.location.href的查找进行了两次,进行了过多的属性查找。
var url = window.location.href;
var query = url.substring(url.indexOf("?"))
修改以后不仅代码阅读性变高,同时避免了不必要的属性查找。
惰性载入函数
由于不同浏览器之间存在行为差异,要想一个功能能在多种浏览器上运行,我们往往需要使用if语句,对浏览器进行能力检测,针对不同情况进行不同处理。
function createXHR() {
if (typeof XMLHttpRequest != 'undefined') {
return new XMLHttpRequest();
} else if (typeof ActiveXObject != 'undefined') {
if (typeof arguments.callee.activeXString != 'string') {
var versions = [
'MSXML2.XMLHttp.6.0',
'MSXML2.XMLHttp.3.0',
'MSXML2.XMLHttp',
],
i, len;
for (i = 0, len = versions.length; i < len; i++) {
try {
new ActiveXObject(versions[i]);
arguments.callee.activeXString = versions[i];
break;
} catch (ex) {
// 跳过
}
}
}
return new ActiveXObject(arguments.callee.activeXString);
} else {
throw new Error('No XHR object available.')
}
}
以上代码是创建一个XHR对象,首先检查内置的XHR,然后测试有没有基于ActiveX的XR,都没有的话就跑出一个错误。仔细观察我们可以发现,这种浏览器能力检测,一旦执行一次以后,浏览器的能力也就确定下来了,如果下次在想获取XHR对象,那么又要进行大量的if判断(有if判断性能一定比没有任何判断性能低)。
这个时候可以使用惰性载入优化该函数,使其分支判断只执行一次:
function createXHR() {
if (typeof XMLHttpRequest != 'undefined') {
createXHR = function () {
return new XMLHttpRequest();
}
} else if (typeof ActiveXObject != 'undefined') {
createXHR = function () {
if (typeof arguments.callee.activeXString != 'string') {
var versions = [
'MSXML2.XMLHttp.6.0',
'MSXML2.XMLHttp.3.0',
'MSXML2.XMLHttp',
],
i, len;
for (i = 0, len = versions.length; i < len; i++) {
try {
new ActiveXObject(versions[i]);
arguments.callee.activeXString = versions[i];
break;
} catch (ex) {
// 跳过
}
}
}
return new ActiveXObject(arguments.callee.activeXString);
}
} else {
createXHR = function () {
throw new Error('No XHR object available.')
}
}
return createXHR();
}
现在createXHR函数在执行一次以后,客户端能力就确定了,后面就直接变成新的函数,新的函数里面只包括当前客户端能力相关的代码,没有了额外的分支判断,提升了性能。
优化循环
我们来看看在JavaScript中如何优化循环。
- 减值迭代:大多数循环使用一个从0开始,增加到到某个特定值的迭代器。在很多情况下,从最大值开始,在循环中不断减值的迭代器更加高效。
- 简化终止条件:由于每次循环过程都会计算终止条件,所以必须保证它尽可能最快。也就是避免属性查找等其他高复杂度的操作。
- 简化循环体:循环体是执行最多的,所以要确保其被最大幅度地优化。 确保没有有些可以被很容器移除循环的密集运算。
- 使用后测试循环:最常用的for循环和while循环都是前测试循环。而如do-while这种后测试循环,可以避免最初终止条件的计算,因此运行更快。
看一个最普通的for循环:
for (var i = 0; i < values.length; i++) {
process(values[i]);
}
如果循环的操作值处理和顺序无关,那么可以修改为减值迭代:
for (var i = values.length - 1; i >= 0; i--) {
process(values[i]);
}
如果已经明确至少要循环一次,那么还可以修改为后测试循环:
var i = values.length - 1;
if (i > -1) {
do {
process(values[i])
} while (--i >= 0)
}
展开循环
当循环的次数是确定的,消除循环并使用多次函数往往更快。假设我们已经知道要循环3次,那么优化循环中的例子可以修改如下:
process(values[0]);
process(values[1]);
process(values[2]);
针对于大数据集的循环操作,我们可以使用一种叫Duff装置的技术来展开循环。Duff装置的基本概念是通过计算迭次的次数是否为8的倍数将一个循环展开为一些列语句。假设我们的values中存储了大量数据,那么使用Duff装置优化如下:
var values = [];
var iterations = Math.floor(values.length / 8);
var leftover = values.length % 8;
var i = 0;
if (leftover > 0) {
do {
process(values[i++]);
} while (--leftover > 0)
}
do {
process(values[i++]);
process(values[i++]);
process(values[i++]);
process(values[i++]);
process(values[i++]);
process(values[i++]);
process(values[i++]);
process(values[i++]);
} while (--iterations > 0);
为了便于理解上述代码,我们假设values的长度为10(之所以是假设,因为Duff用于大数据集处理,如果数据很少,那么造成的额外开销反而得不偿失)。那么此时iterations=1,leftover=2。经历第一个do-wihle循环后,values[0]和values[1]得到处理,此时i为2,在进行第二个do-while循环,则刚好10个数据处理完。
仔细观察一下上面代码还存在优化的地方,如果我们的values是HTMLCollection对象,那么读取两次values的长度也是性能的开销,同时万一iterations的值为0(都知道了是大数据集,基本不会出现这种情况,但是万一获取values的时候出现了问题,那么就会有问题),那么第二个do-while循环的执行就会出现问题,修改如下:
var values = [];
var len = values.length;
var iterations = Math.floor(len / 8);
var leftover = len % 8;
var i = 0;
if (leftover > 0) {
do {
process(values[i++]);
} while (--leftover > 0)
}
if (iterations > 0) {
do {
process(values[i++]);
process(values[i++]);
process(values[i++]);
process(values[i++]);
process(values[i++]);
process(values[i++]);
process(values[i++]);
process(values[i++]);
} while (--iterations > 0);
}
避免双重解析
JavaScript代码想解析JavaScript的时候会存在双重解释惩罚。使用eval函数或者是Function构造函数以及使用setTimeout传一个字符串参数时,都会出现这种情况:
eval("alert('Hello world!')")
var sayHi = new Function("alert('Hello world!')");
setTimeout("alert('Hello world!')", 500);
上述的操作是不能在初始解析的过程中完成的,在JavaScript代码运行的同时必须启动一个新的解析器来解析这些字符串代码。启动新的解析器是有一定的开销的,所以要避免以上操作:
alert('Hello world!')
var sayHi = function () {
alert('Hello world!');
}
setTimeout(function () {
alert('Hello world!')
}, 500);
优化DOM交互
JavaScript常见的操作就有操作DOM元素,这个操作过程我们也是可以优化的。
1.使用文档碎片(documentFragment)批量创建元素
2.使用innerHTML来创建元素或者修改元素内容
3.使用事件代理(又称事件委托)
4.注意HTMLCollection:对HTMLCollection的访问都是在文档上的一个查询,有着不小的消耗,所以要最小化的访问HTMLCollection,还记得我们对Duff介绍中values.lenght的优化吗?那就是一个简单的优化。会返回HTMLCollection对象的操作如下:
- 进行了类似getElementsByTagName的调用;
- 获取了元素的childNodes属性;
- 获取了元素的attributes属性;
- 访问了特殊集合,如doucment.forms,document.images等;
最小化语句数
- 多个变量声明:在使用var或者let以及const,尽可能一次性的声明完成。
- 插入迭代值:参考Duff介绍中i++的处理,在计算结果的同时,让i自增或自减,减少语句。
- 使用数组和字面量
其他注意事项
- 尽可能使用原生方法:不管你的实现有多厉害和牛逼,但只要你的实现功能原生可以做到,那么请你使用原生,效率会高一点。
- Switch语句较快:如果存在大量的if-else语句,请用Switch语句来代替。还可以通过将case语句按照最不可能出现的顺序进行组织,达到进一步的优化。
- 位运算符较快:当进行数学运算的时候,位运算操作要比任何布尔运算或者算数运算要快。选择性地使用位运算替换算数运算可以极大提升复杂计算的性能。推荐一个好的例子:去查看React源码,在Diff的时候,给fiber节点加上标志的操作就是使用的位运算操作,通过各种状态掩码可以很好判断当前fiber的状态。
最后
以上就是瘦瘦流沙最近收集整理的关于5.JavaScript代码优化代码优化的全部内容,更多相关5内容请搜索靠谱客的其他文章。








发表评论 取消回复