https://www.aclweb.org/anthology/W17-4763.pdf
https://dl.acm.org/doi/pdf/10.1145/3109480
使用多级任务学习与堆栈传播的质量估计方法 Predictor-Estimator
Github:https://github.com/Unbabel/OpenKiwi
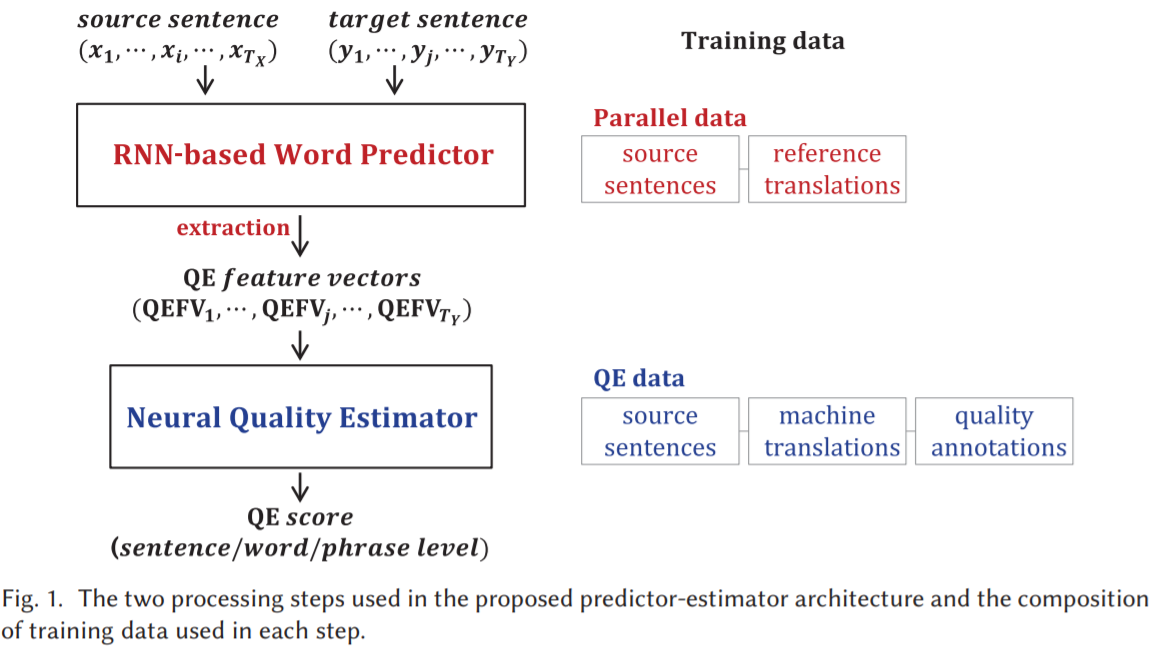
两段神经网络 QE 模型,多级任务学习估计句子、单词和短语的翻译质量,基于端到端的堆叠神经模型 Predictor-Estimator,训练时使用 stack propagation,可以在单级模式下联合训练单词预测模型和 QE 模型。使用带堆栈传播的多级任务学习,在WMT17 QE task 所有QE子任务(句子/单词/短语级)中实现了最佳性能。
1 Introduction
Predictor-Estimator 结构如下:
1) a neural word prediction model (word predictor),使用额外的大型平行语料库训练;
2) a neural QE model (quality estimator),使用有质量标注的有噪声的平行语料库 QE data 训练。
Predictor-Estimator 使用单词预测作为 pre-task,有助于提高 QE 的性能。在第一阶段,双向和双语 RNN 的单词预测器(基于注意力的RNN encoder-decoder),使用 unbounded 的源和目标上下文预测目标单词,QEFVs 是从单词预测到 QE 的近似知识传递。在第二阶段,QEFVs 作为质量估计器的输入,用于评估句子/单词/短语级的翻译质量。
Predictor
使用源上下文 x 和目标上下文 y-j 预测 j 位置的目标词 yj 的条件概率为:
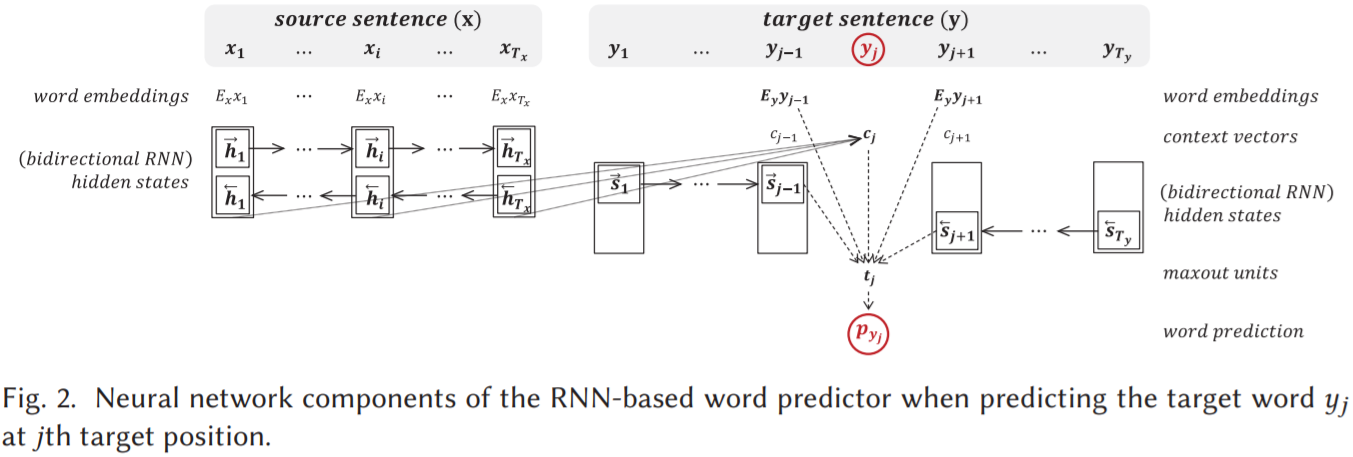
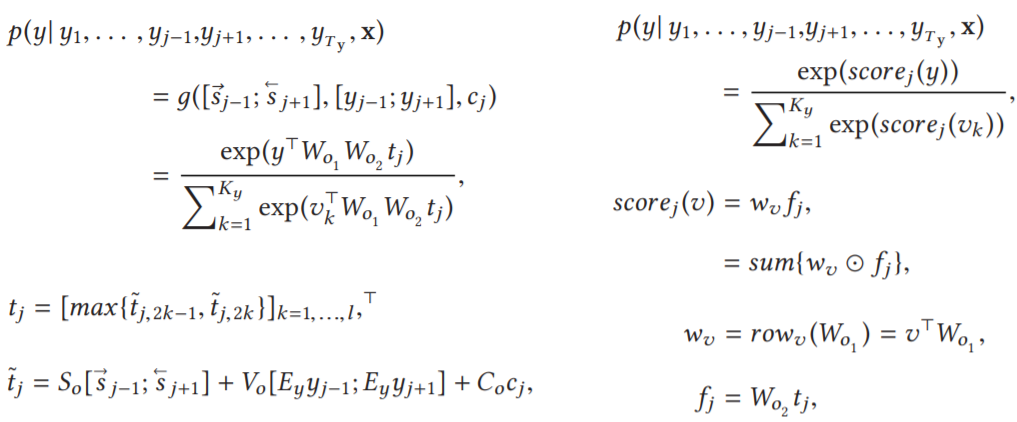
左右两个公式是等价的,第一个中的 g 是一个非线性函数,cj 是源上下文向量,由注意力机制产生,Wo1∈R^Ky×q, Wo2∈R^q×l, So∈R^2l×2n, Vo∈R^2l×2m, Co∈R^2l×2n 是相邻层间的权值矩阵,m为嵌入字的维数,n为前向和后向 RNNs 的隐状态维数,l 为 maxout 的维数,q 是最后一个连接到输出层的隐含层的维数。第二个中的 wv 是隐藏层到输出层的输出为词 v 的权重矩阵,fj 是目标句 j 位置的 q 维隐表征。
注意到平行语料库和 QE data 之间存在差异:平行语料库目标句都是正确的,而 QE data 中可能是正确的、也可能是错误的,因此不希望直接使用 QE 任务的预测结果。
两类 QEFVs:pre-prediction QEFVs (Pre-QEFVs) 和 post-prediction QEFVs (Post-QEFVs)。
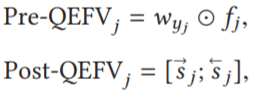
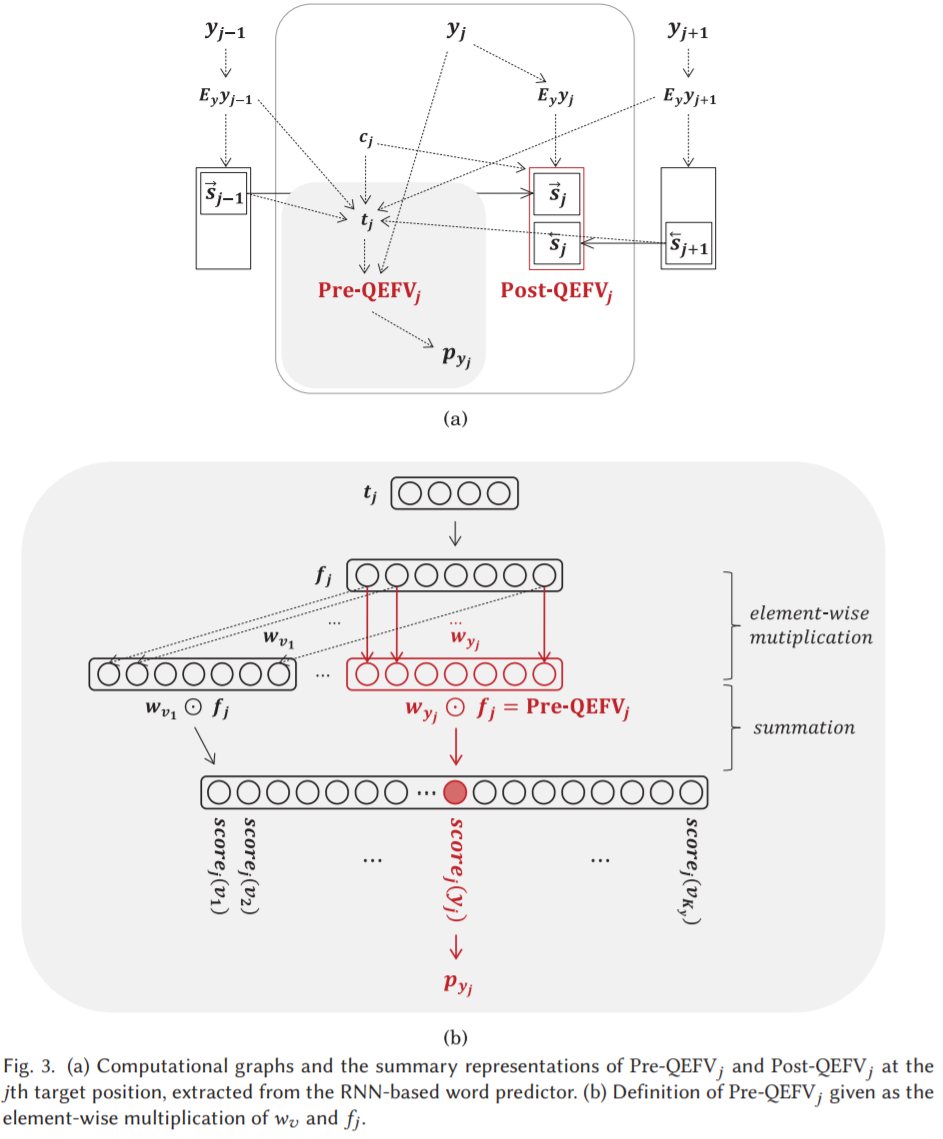
图3(a) 为单词预测器提取的第 j 个目标位置的 Pre-QEFVs 和 Post-QEFVs 的计算图,(b) 为根据 wv 和 fj 的元素乘积计算 Pre-QEFV。
Estimator
句子级QE 可视为监督回归任务,评估翻译的 HTER 得分。首先将所有 QEFVs 转换为单个汇总向量 s,然后对其使用逻辑回归。假设 QEFVs (QEFV_1, ..., QEFV_Ty) 是 y 的 QEFV 序列,QEFVs 是根据 Pre-QEFVs、Post-QEFVs 或它们的组合提取的,则句子级 QE 模型 QEsentence (y, x) 定义为:
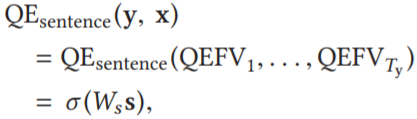
图4(a) - (c) 分别为 FNN、RNN 和 Bi-RNN 三种方法,即 s 为:FNN 隐状态的平均、RNN 最后一个时间步的隐状态、Bi-RNN 最后一个时间步前后向隐状态的连接。

单词级 QE 为二分类任务,将 QEFVs 作为输入序列,生成两类标记 OK/BAD,第 j 个目标位置的二分类函数 QE_wordj (y, x) 为:
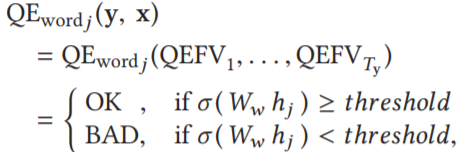
短语级 QE ,将单词级序列标记扩展,输入是短语级 QEFVs 序列,是其组成单词的词级 QEFVs 中归纳所得(平均值)。令 QEFV'_phk 为目标中第 k 个短语 phk 的短语级 QEFV,(QEFV'_1, ..., QEFV'_phk, ..., QEFV'_Py) 是给定的短语级 QEFVs 序列,短语级模型 QE_phrasek (y, x),即第 k 个短语的二分类模型为:
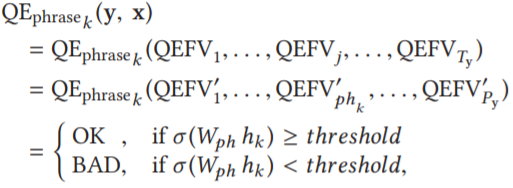
除了输入为短语级之外,其余部分与单词级模型相同,仍使用 FNN、RNN 或 Bi-RNN 三种模型。
Stack propagation 是一种高效的联合学习方法,支持沿着堆叠模型反向传播,在词性标注或解析模型之间随机切换更新。原始 Predictor-Estimator 结构中,单词预测器和质量估计器是单独训练的,在训练质量估计器时的反向传播并没有降低单词预测器网络的质量。由于叠词预测器和质量估计器之间存在连续可微的联系,我们利用堆栈传播来联合学习预测器-估计器中的两阶段模型。此外,我们部署了带有堆栈传播的多级任务学习,其中不仅使用特定于任务的训练示例,还使用QE子任务的所有其他训练示例来训练特定于任务的PredictorEstimator。
2 Improving Predictor-Estimator with Stack Propagation
2.1 Base Model
即原始的 Predictor-Estimator,单独训练单词预测器和质量估计器,Pre&Post-QEFV / Bi-RNN model,单词预测器中提取 Pre&Post-QEFV,质量估计器使用 Bi-RNN。Pre&Post-QEFV 是单词预测器中的总结表征,涉及到从每个目标词预测中近似的转移知识,包括 word prediction-based weight-inclusive indirect representation -- Pre-QEFV 和 direct hidden state -- Post-QEFV。
2.2 Using Stack Propagation
堆叠的单词预测器和质量估计器之间具有连续可微的链接,联合学习两阶段模型,使用堆栈传播交替对单词预测或 QE 目标进行随机更新,实现从质量估计器到单词预测器的反向传播。
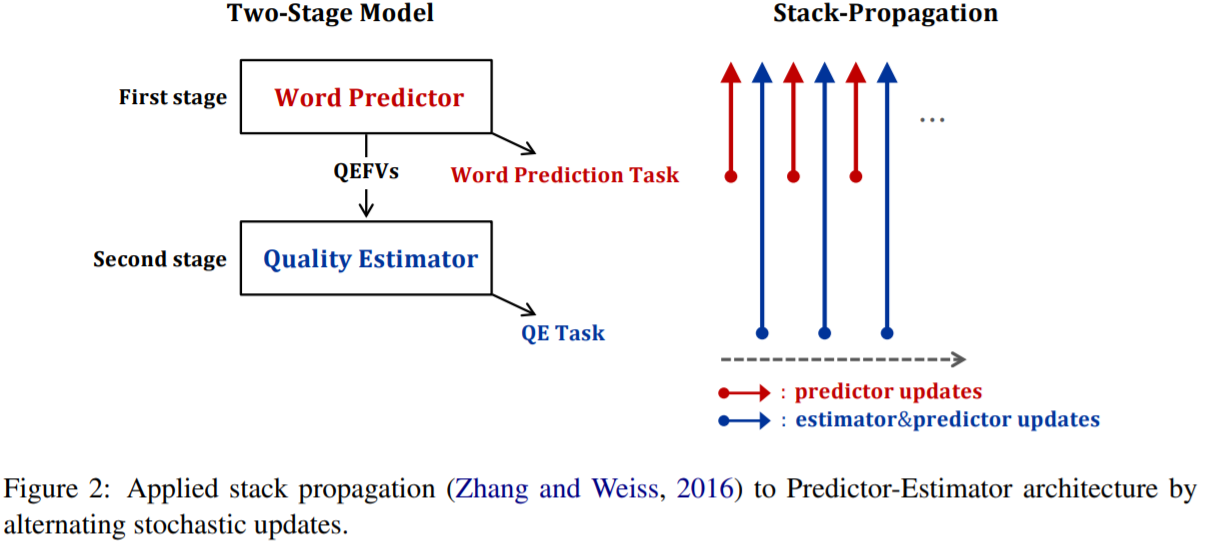
2.3 Using Multilevel Task Learning with Stack Propagation
堆栈传播的多任务学习使用所有 QE 子任务(句子/单词/短语级)的数据训练特定任务的预测器,基于的思想是,各级的标注是比较 post-editing 与翻译输出计算 HTER。各级的共同部分有:1) 单词预测器 2) 质量估计器的输入和隐藏状态,只有输出层不同。训练时不仅使用特定任务的数据,还使用其他子任务的数据训练公共部分,可以在各级之间学习有用的关系。
3 Experimental Results
- 句子级评估标准:
(1) Pearson’s r correlation [primary metric]:对目标翻译的预测 HTER 分数和真实 HTER 分数之间的线性相关性的度量。
(2) Mean Absolute Error, MAE:目标翻译的预测HTER分数与真实HTER分数的平均绝对差值。
(3) RMSE:目标翻译的预测HTER分数和真实HTER分数之间的平均平方误差的平方根。
(4) Spearman's ρ correlation:测量预测排名之间的等级相关和目标的真实排名翻译。
(5) DeltaAvg:根据目标译文的真实排名来衡量预测的目标译文排名的价值。
- 单词/短语级评估标准:
(1) F1-BAD 和 F1-OK 的乘积 (F1-mult) [primary metric]: 考虑两个平衡的分量。
(2) F1-BAD:BAD 标签的 F1-score。
(3) F1-OK:OK 标签的 F1-score。
3.1 Experimental settings
使用 WMT17 QE 任务中的句子/单词/短语级 en-de、de-en 语料评估模型,训练语料为 WMT17 QE data 和各种平行语料库,包括 Europarl corpus, common crawl corpus, news commentary, WMT 17 翻译任务的 rapid corpus of EU press releases,和 WMT17 QE task 中的 src-pe 对。所有 Predictor-Estimator 模型都使用分别训练的单词预测器和质量估计器进行初始化。
3.2 Results of the Single Predictor-Estimator Models
表1为基本、单级堆叠传播和多级堆叠传播 Predictor-Estimator 的实验结果,基本模型性能较低,多级堆叠模型性能最好,在句子/单词/短语级任务中均有显著提高。
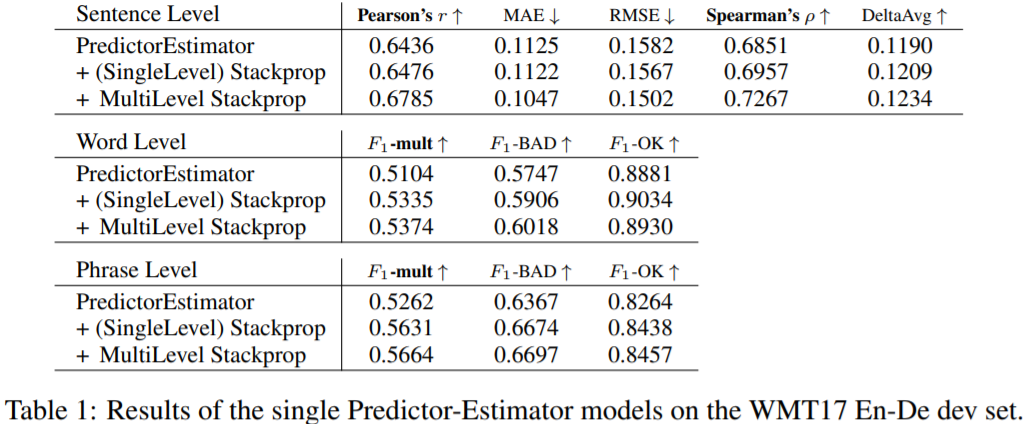
表2-3为 en-de、de-en QE 测试集在各级的实验结果。
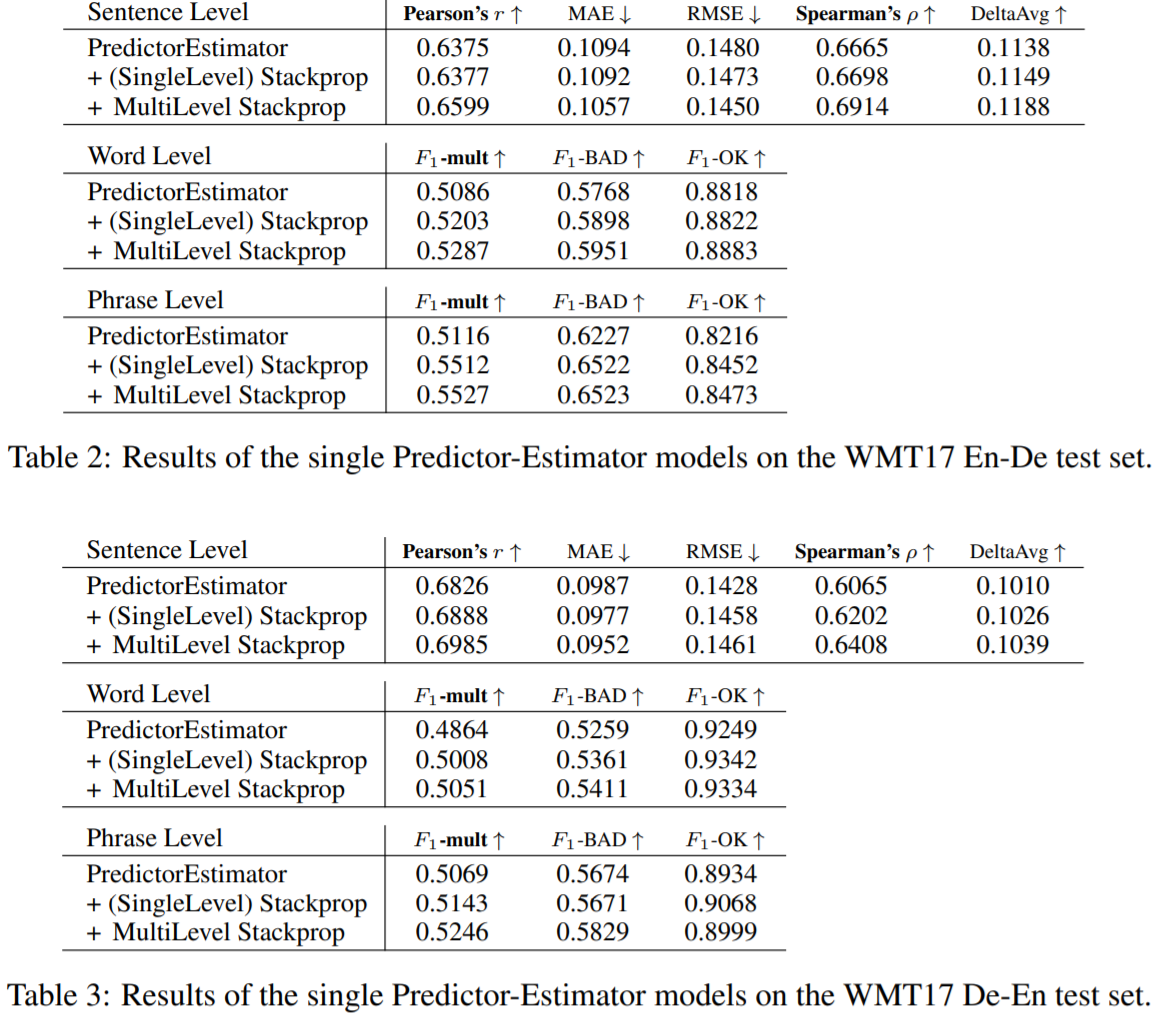
3.3 Results of Ensembles of Multiple Instances
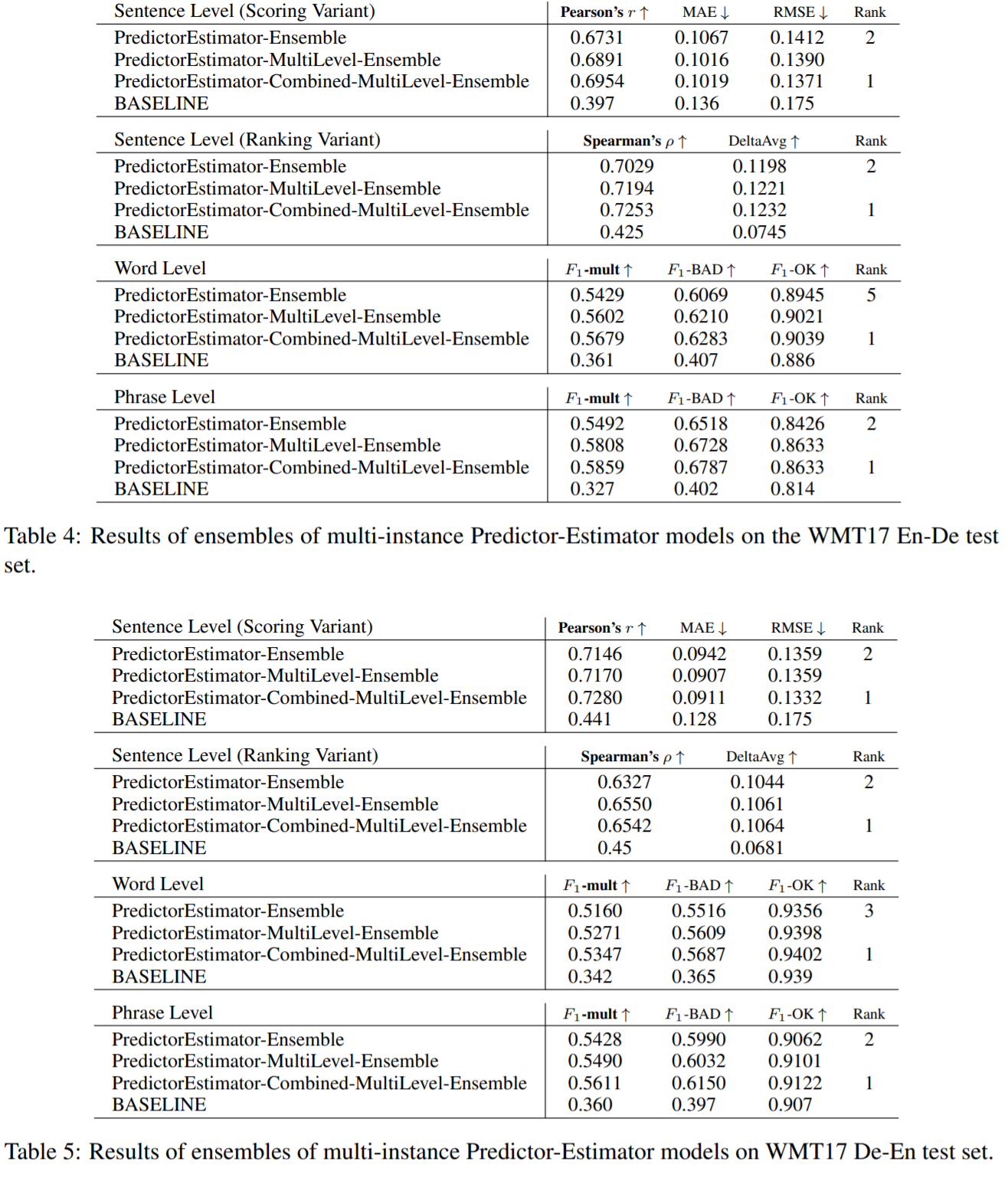
使用两种单一模型:最简单的基本模型,和最复杂的带堆栈传播的多级任务学习模型。为了产生集成结果,对每个预测得分进行平均,基本模型的集成是通过五种维数设置对每个模型的15个预测进行平均,产生3个具有不同变换训练示例的训练实例,称为 PredictorEstimator-Ensemble;复杂模型是用三种维数设置对每个模型的15个预测进行平均,产生5个具有不同变换训练示例的训练实例,称为 PredictorEstimator-Multilevel-Ensemble。还对 PredictorEstimator-Ensemble 和 PredictorEstimator-Multilevel-Ensemble 进行集成,称为 PredictorEstimator-Combined-Multilevel-Ensemble。
表4-5为句子/单词/短语级 en-de/de-en 测试集的多实例 Predictor-Estimator 实验结果,其中 PredictorEstimator-Combined-Multilevel-Ensemble 性能最好,在 WMT17 QE 所有子任务中排名第一。
最后
以上就是喜悦香氛最近收集整理的关于论文阅读——Predictor-Estimator using Multilevel Task Learning with Stack Propagation for Neural QE的全部内容,更多相关论文阅读——Predictor-Estimator内容请搜索靠谱客的其他文章。








发表评论 取消回复