博主个人网站原文链接:https://www.yourmetaverse.cn/nlp/1/
使用stable diffusion webui在本地搭建中文的AI绘图模型
Stable diffusion是一种随机过程,它是通过在随机分数阶微分方程中引入稳定分布来描述随机漂移和扩散的过程。它通常用于描述具有长程依赖性的复杂系统,因为该过程允许在长时间尺度上出现缓慢变化的漂移和扩散。
在stable diffusion中,扩散系数不是一个常数,而是随时间变化的,这种变化是根据分式阶微分方程中的阶数来控制的。这种分数阶微分方程包含一个称为稳定分布的函数,它描述了随机过程中涉及的随机变量的概率分布。
由于stable diffusion具有长程依赖性,它可以用于描述各种现象,如金融市场波动、气候变化、信号传输等。
最近一段时间大火的AI绘画引起了各界人士的关注,但是stable diffusion开源的都是英文的模型,本文参考封神榜团队开源的太乙模型以及相关代码,利用stable diffusion web ui搭建一个中文的AI绘图模型,在本地实现AI绘画。如下就是使用AI作画绘制的图形。


想体验的可以通过下面的链接进行体验(想更好地体验建议参考第三章指南),想自己搭建本地的webui可以参考后面的实例。
太乙:https://huggingface.co/IDEA-CCNL/Taiyi-Stable-Diffusion-1B-Chinese-v0.1
太乙-动漫:https://huggingface.co/IDEA-CCNL/Taiyi-Stable-Diffusion-1B-Anime-Chinese-v0.1
1. 准备条件
(1)git工具安装
安装git工具用来下载相关项目文件,使用如下命令安装:(对于linux系统命令不熟悉的可以去apt-get(Advanced Package Tool)软件包管理命令和linux下常用命令详解)
apt-get install git
(2)模型下载
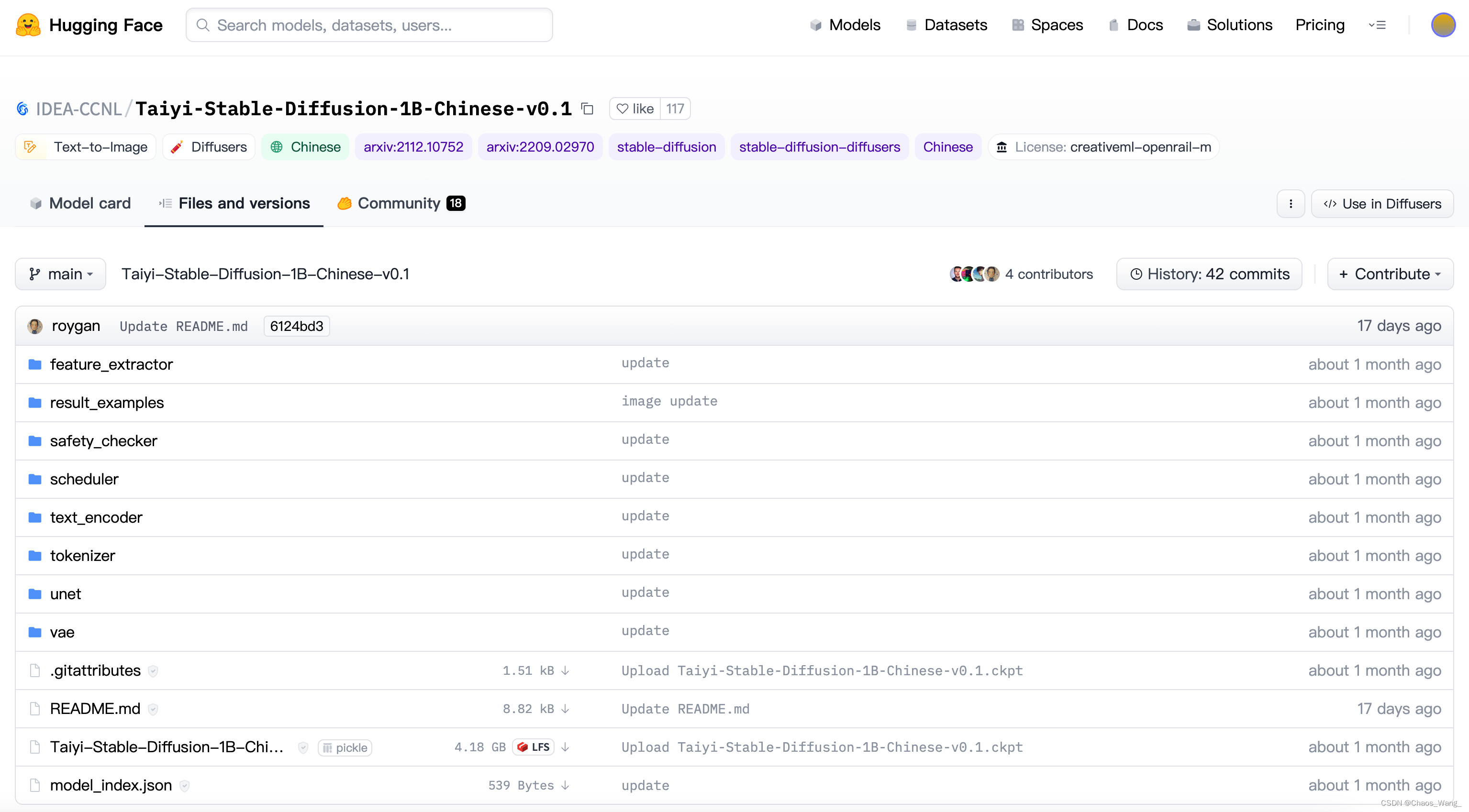
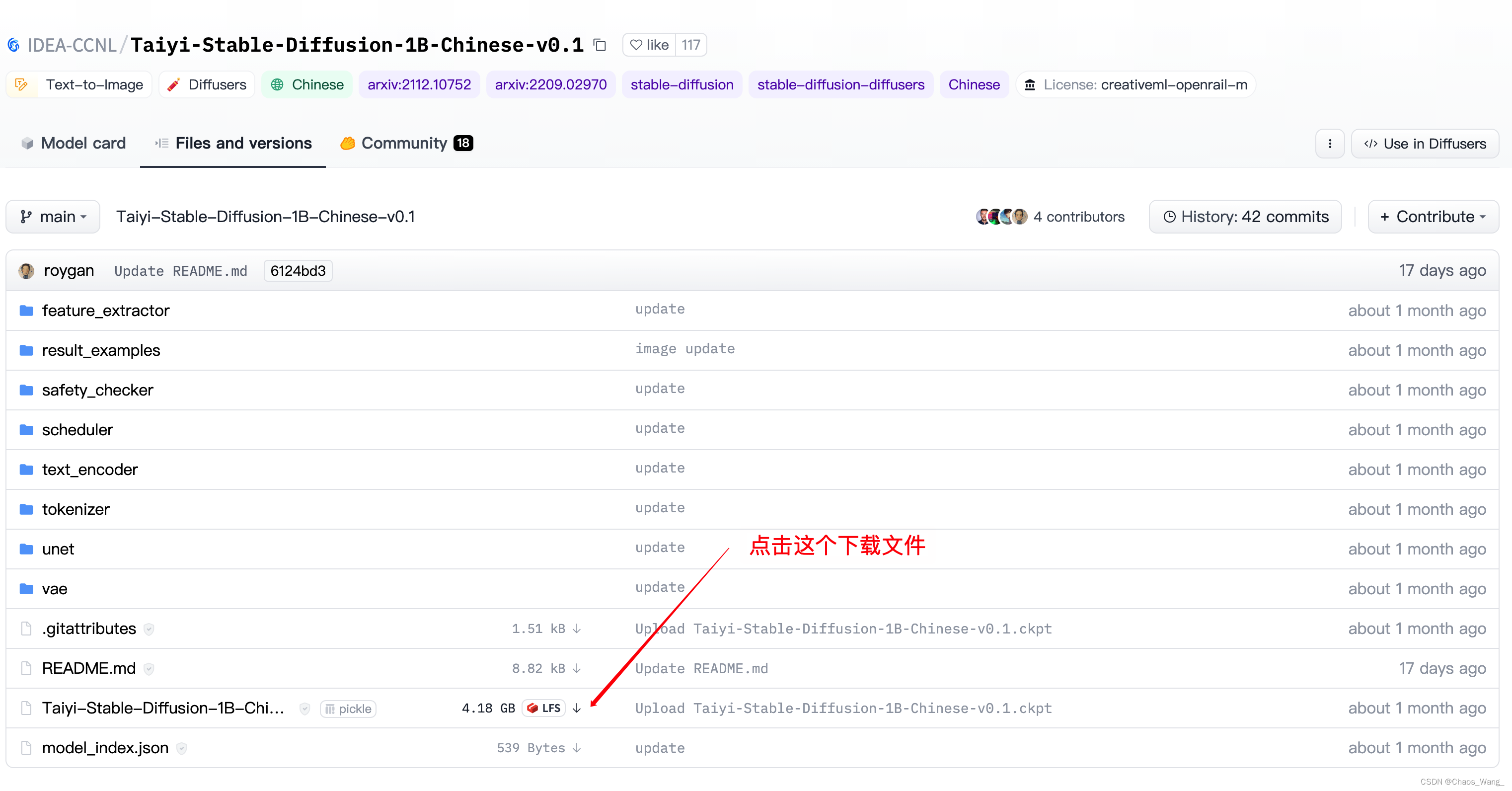
将这个页面的文件和文件夹下的文件均下载到本地,命名和路径均保持原样:
点击向下的下载箭头下载文件,如下所示:
2. 搭建过程(更新)
使用git工具下载项目文件到本地文件夹,命令如下:
git clone https://github.com/IDEA-CCNL/stable-diffusion-webui.git
然后进入该文件夹:
cd stable-diffusion-webui
step2:运行自动化脚本
运行webui.sh安装一些python环境
bash webui.sh
这个时候如果遇到root用户的报错,如下:
ERROR: This script must not be launched as root, aborting...
可以注释掉webui.sh的63-74行的内容,如下所示:
## Do not run as root
#if [[ $(id -u) -eq 0 ]]
#then
# printf "n%sn" "${delimiter}"
# printf "e[1me[31mERROR: This script must not be launched as root, aborting...e[0m"
# printf "n%sn" "${delimiter}"
# exit 1
#else
# printf "n%sn" "${delimiter}"
# printf "Running on e[1me[32m%se[0m user" "$(whoami)"
# printf "n%sn" "${delimiter}"
#fi
如果遇到下面的报错:
ImportError: libGL.so.1: cannot open shared object file: No such file or directory
可以运行下面命令
#物理机上运行:
pip install opencv-python-headless
#docker环境运行:
apt-get install ffmpeg libsm6 libxext6 -y
apt-get install libgl1
如果遇到下面错误:
ERROR: python3-venv is not installed, aborting...
可以试试把weiui.sh脚本里面97-103行的内容注释掉看是否能够运行,如下所示:
#if ! "${python_cmd}" -c "import venv" &>/dev/null
#then
# printf "n%sn" "${delimiter}"
# printf "e[1me[31mERROR: python3-venv is not installed, aborting...e[0m"
# printf "n%sn" "${delimiter}"
# exit 1
#fi
最后运行以下命令启动webui
bash webui.sh --listen --port 12345
或者使用以下命令启动webui
./venv/bin/python launch.py --ckpt repositories/Taiyi-Stable-Diffusion-1B-Chinese-v0.1/Taiyi-Stable-Diffusion-1B-Chinese-v0.1.ckpt --listen --port 12345
2. 搭建过程(原始)
step1:下载项目文件
使用git工具下载项目文件到本地文件夹,命令如下:
git clone https://github.com/IDEA-CCNL/stable-diffusion-webui.git
然后进入该文件夹:
cd stable-diffusion-webui
step2:运行自动化脚本
运行webui.sh安装一些python环境
bash webui.sh
之后会遇到以下的报错:
No checkpoints found. When searching for checkpoints, looked at:
- file /xxx/stable-diffusion-webui/model.ckpt
- directory /xxx/stable-diffusion-webui/models/Stable-diffusion
Can't run without a checkpoint. Find and place a .ckpt file into any of those locations. The program will exit.
这个是正常的,官方给的readme文件中也有说明,需要将项目文件修改一些内容已经把之前下载好的模型文件放进来。
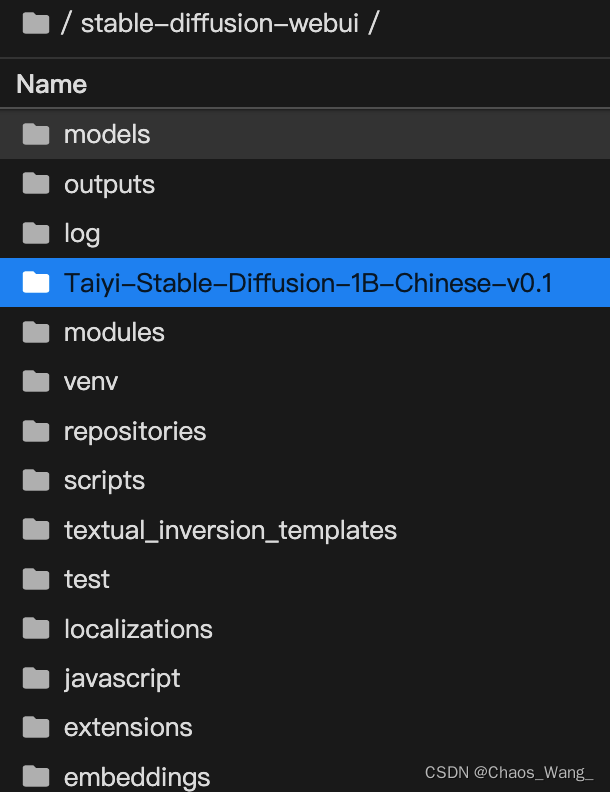
step3:将模型文件放到项目中
在项目的根目录下,新建一个名为’Taiyi-Stable-Diffusion-1B-Chinese-v0.1’文件夹,将准备阶段下载好的模型文件放到该文件夹里:
如下所示:
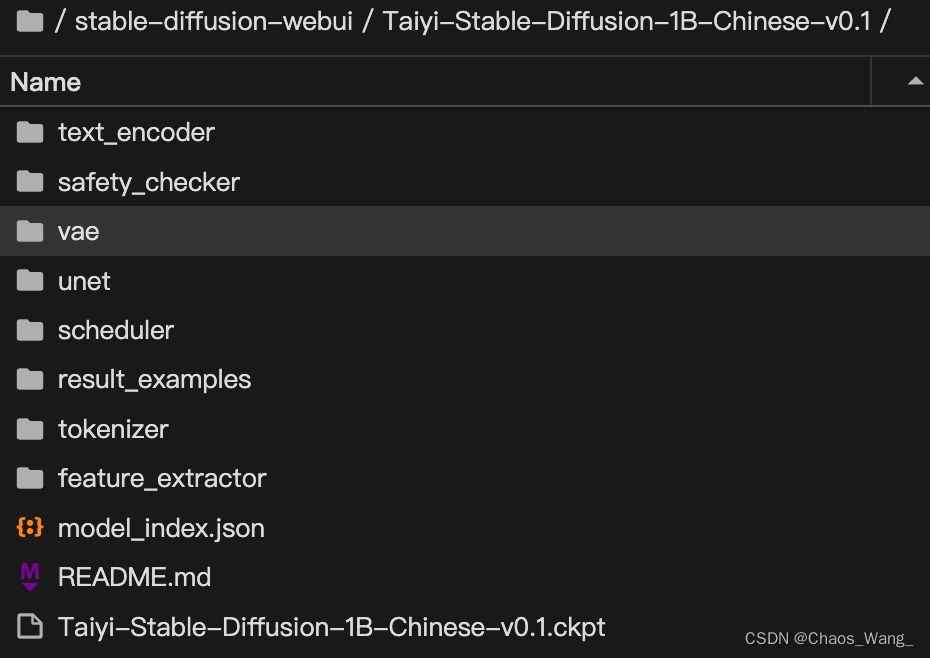
然后将之前下载好的模型文件放到该文件夹里面,注意需要将所有的文件按照原样放到里面,如下所示:
step4:更改相关配置
然后将官方说明的一些文件进行替换,主要有两个文件,一个是:
stable-diffusion-webui/repositories/stable-diffusion/configs/stable-diffusion/v1-inference.yaml,将其替换成stable-diffusion-webui/repositories/stable-diffusion-taiyi/configs/stable-diffusion/v1-inference.yaml
命令如下(执行以下命令时需要你在项目文件夹的根路径下,即stable-diffusion-webui路径下):
cp ./repositories/stable-diffusion-taiyi/configs/stable-diffusion/v1-inference.yaml ./repositories/stable-diffusion/configs/stable-diffusion/v1-inference.yaml
一个是:
stable-diffusion-webui/repositories/stable-diffusion/ldm/modules/encoders/modules.py,将其替换成stable-diffusion-webui/repositories/stable-diffusion-taiyi/ldm/modules/encoders/modules.py
命令如下(执行以下命令时需要你在项目文件夹的根路径下,即stable-diffusion-webui路径下):
cp ./repositories/stable-diffusion-taiyi/ldm/modules/encoders/modules.py ./repositories/stable-diffusion/ldm/modules/encoders/modules.py
然后修改下面的配置文件:
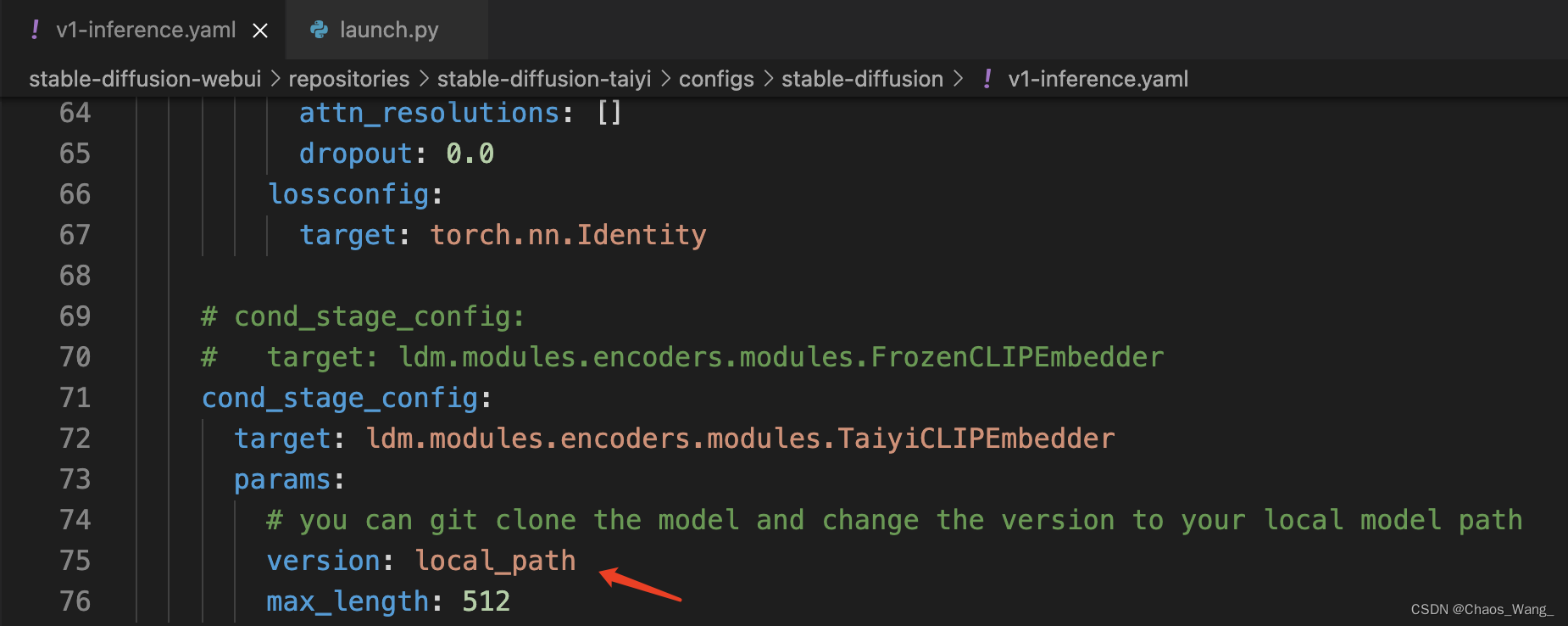
将local_path设置为之前下载的文件Taiyi-Stable-Diffusion-1B-Chinese-v0.1.ckpt的绝对路径
step5:运行脚本
运行以下脚本配置相关环境(执行以下命令时需要你在项目文件夹的根路径下,即stable-diffusion-webui路径下):
cd repositories/stable-diffusion
pip install -e .
cd ../../
最后执行以下命令即可在本地调用太乙模型实现AI作画:
python launch.py --ckpt ./Taiyi-Stable-Diffusion-1B-Chinese-v0/Taiyi-Stable-Diffusion-1B-Chinese-v0.1.ckpt --listen --port 12345 #端口可以自定义
然后在本地电脑输入:localhost:12345即可访问web ui界面做各种中文AI绘图的操作。具体详见第三章。
下面是一些常见的参数设置:
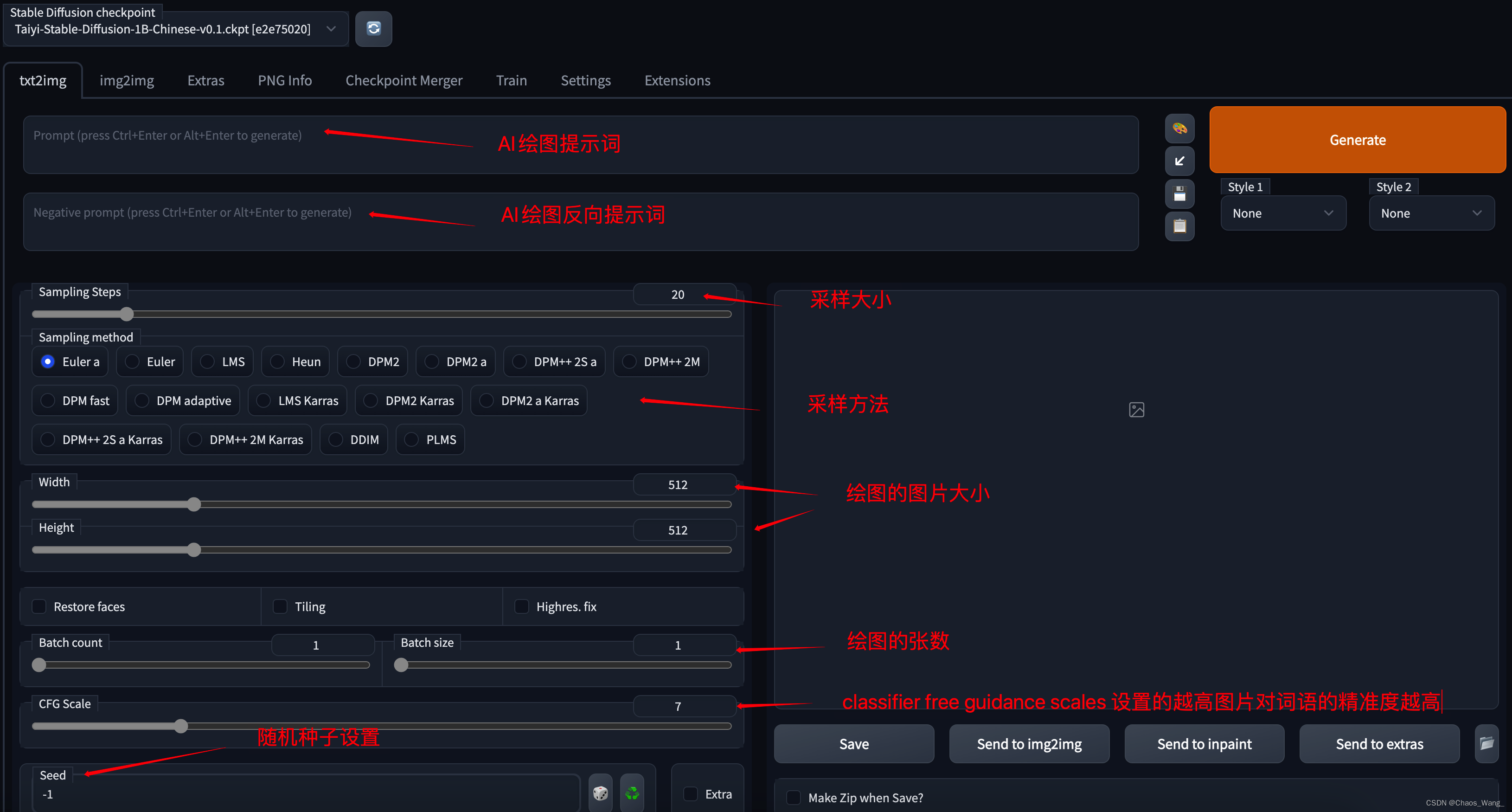
设置好参数后点击generate即可生成图片。
3. 调教(调戏)AI绘画
具体作画过程可以参考官方给的手册:腾讯文档】太乙绘画使用手册1.1
这里总结了一下主要有以下几点需要注意的地方:
1.画幅大小设置为512×512最佳。
2.建议不用任何中文标点符号。
3.赋予某种属性(4k壁纸, 插画, 油画等)可以帮助消除白边。
4.选择20-25之间作为采样迭代步数。
最后官方给了三种绘画场景,分别是:
古诗词
科幻
歌词
下面分别是官方给的几个AI生图的参考:
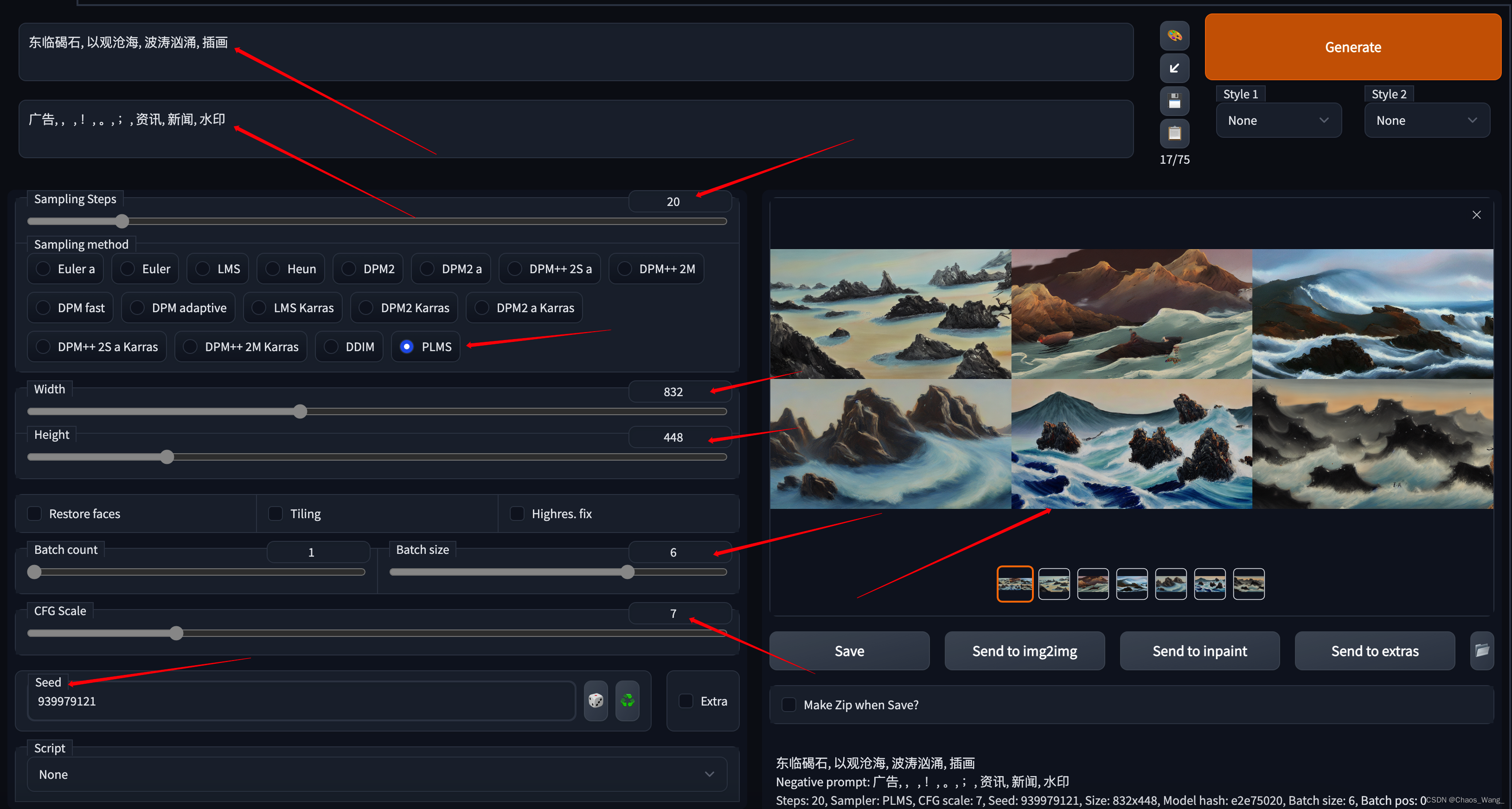
(1)古诗词风格

生图参数:
东临碣石, 以观沧海, 波涛汹涌, 插画
Negative prompt: 广告, ,, !, 。, ;, 资讯, 新闻, 水印
Steps: 20, Sampler: PLMS, CFG scale: 7, Seed: 939979121, Size: 832x448, Model hash: e2e75020, Batch size: 6, Batch pos: 0
如下所示:
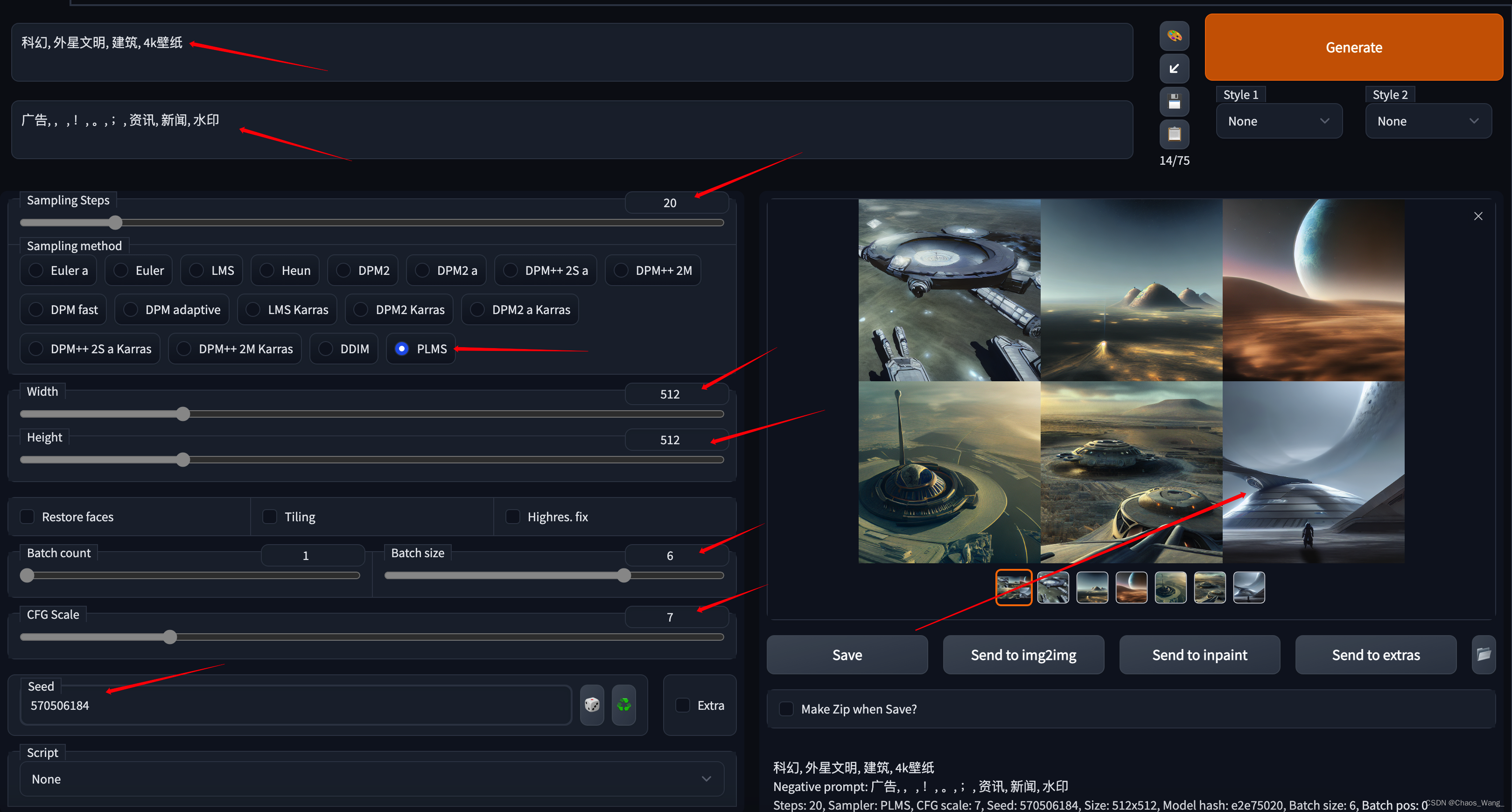
(2)科幻风格

生图参数:
科幻, 外星文明, 建筑, 4k壁纸
Negative prompt: 广告, ,, !, 。, ;, 资讯, 新闻, 水印
Steps: 20, Sampler: PLMS, CFG scale: 7, Seed: 570506184, Size: 512x512, Model hash: e2e75020, Batch size: 6, Batch pos: 0
如下所示:
(3)歌词风格

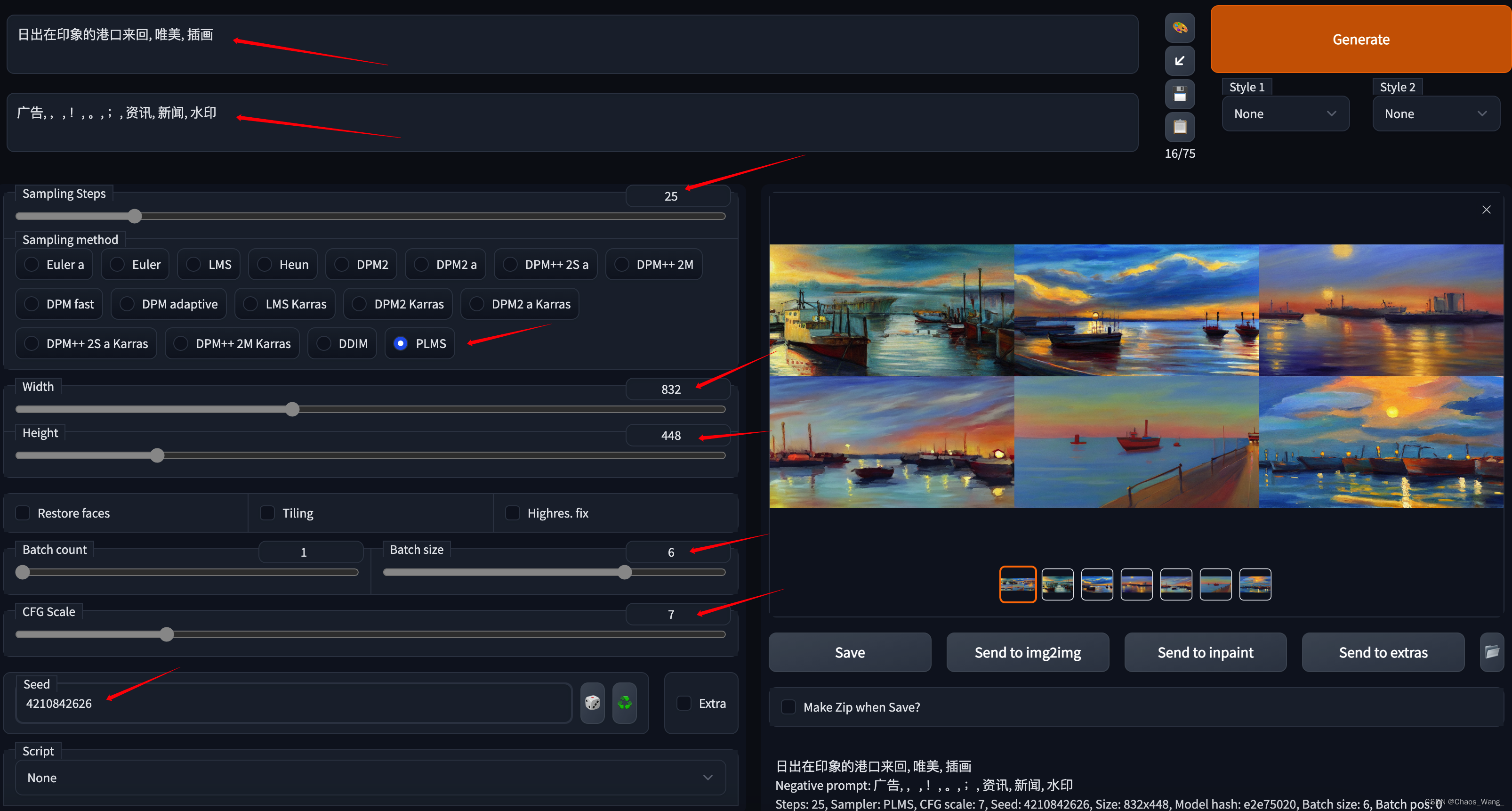
生图参数:
日出在印象的港口来回, 唯美, 插画
Negative prompt: 广告, ,, !, 。, ;, 资讯, 新闻, 水印
Steps: 25, Sampler: PLMS, CFG scale: 7, Seed: 4210842626, Size: 832x448, Model hash: e2e75020, Batch size: 6, Batch pos: 0
如下所示:
4. 其他AI绘画api集合
(1)达摩院通义文生图大模型
ModelScope 社区成立于 2022 年 6 月,是一个模型开源社区及创新平台,由阿里巴巴达摩院,联合 CCF开源发展委员会,共同作为项目发起方。社区联合国内 AI 领域合作伙伴与高校机构,致力于通过开放的社区合作,构建深度学习相关的模型开源,并开源相关模型服务创新技术,推动模型应用生态的繁荣发展。
(2)「文心·一格」——基于百度文心大模型能力的AI艺术和倡议辅助平台

文心一格,是基于文心大模型能力的AI艺术和创意辅助平台。
在这里您可以生成不同风格、独一无二的创意画作,为设计提供灵感、为创作带来更多创意!
(3)华为云 文字生成图片Stable Diffusion

(4)midjourney
Midjourney是一个独立的研究实验室,探索新的思想媒介,扩展人类物种的想象力。
我们是一个自筹资金的小型团队,专注于设计、人力基础设施和人工智能。我们有11名全职员工和一群出色的顾问。
(5)ERNIE-ViLG AI 作画大模型

文心 ERNIE-ViLG 2.0 采用基于知识增强算法的混合降噪专家建模,是全球首个知识增强的 AI 作画大模型,也是目前全球参数规模最大的 AI 作画大模型,在文本生成图像公开权威评测集 MS-COCO 和人工盲评上均超越了 Stable Diffusion、DALL-E 2 等模型,取得了当前该领域的世界最好效果,并在语义可控性、图像清晰度、中国文化理解等方面展现出了显著优势。
文心 ERNIE-ViLG 2.0 通过视觉、语言等多源知识指引扩散模型学习,强化文图生成扩散模型对于语义的精确理解,以提升生成图像的可控性和语义一致性。同时,ERNIE-ViLG 2.0 首次引入基于时间步的混合降噪专家模型来提升模型建模能力,让模型在不同的生成阶段选择不同的“降噪专家”网络,从而实现更加细致的降噪任务建模,提升生成图像的质量。
(6)智源研究院大模型研究团队开源的双语 AltDiffusion 模型

FlagStudio 项目致力于贡献优秀AI生成艺术作品。此双语文生图模型项目基于 stable diffusion,由BAAI旗下的FlagAI团队提供支持,相关代码和模型权重在AltDiffusion中进行开源。
(7)二次元人物绘画网站

Draft是一个由工程师和设计师组成的年轻团队,我们在实际工作过程中,深刻感受到了AI生成对设计和创意工作带来的影响。
例如,过去我们团队的原画师/3D建模师/平面设计师在找灵感的时候,会上A站和Pinterest上搜索,在一些知名设计师的作品基础上构思方案。
而现在,在AI模型中只需要输入关键词,就能得到包含“创意”“设计思路”的图片,一张不满意,可以继续生成。在AI大批量生成方案的帮助下再进行设计构思,比以往手动搜集和在草稿纸上比划,我们发现新的方法更先进。
(8)Stable Diffusion 2 Demo

(9)stablediffusionweb
(10)novelai
NovelAI是一项每月订阅的服务,用于人工智能辅助的写作、讲故事、虚拟陪伴,或者只是一个由GPT驱动的沙盒,供您发挥想象力。
我们的人工智能算法基于你自己的作品创造出类似人类的写作,使任何人,无论能力如何,都能创作出高质量的文学作品。通过使用我们自己的人工智能模型,在真实的文学作品上进行训练,我们的自然语言处理游乐场提供了前所未有的自由度。AI无缝地适应你的输入,保持你的观点和风格。
(11)dreamstudio
(12)Disco Diffusion
Disco Diffusion 是发布于 Google Colab 平台的一款利用人工智能深度学习进行数字艺术创作的工具,它是基于 MIT 许可协议的开源工具,可以在 Google Drive 直接运行,也可以部署到本地运行,目前最新的版本是 Disco Diffusion v5.2。
用白话讲 Disco Diffusion 的基本工作就是把你给出的 Prompts(提示/描述)由文字信息变成图像信息,把你用文字描述的画面「画」出来。
(13)DALL·E 2
DALL·E2是一款基于机器学习的文本到图像人工智能艺术生成器,在网上引发了恐惧和敬畏(请参阅我们挑选的DALL·e2创作的最奇怪的人工智能艺术)。它由人工智能公司开放人工智能创建,是一种生成工具,这意味着它可以从零开始生成艺术,也可以对现有作品进行编辑或修改。它实际上并不“知道”它在创造什么,但它是基于它已经提供的6.5亿个图像和字幕组合的庞大数据库进行假设的。
这个名字是“Dali”(如萨尔瓦多)和皮克斯的“WALL-E”的组合词。顾名思义,这是该工具的第二次迭代,似乎是对第一次迭代的重大改进,第一次迭代往往会生成颗粒状图像,而且需要很长时间。
它绝不是唯一一个基于文本提示的生成性人工智能艺术创作者。Artbreeder最近推出了Artbreedr拼贴画,它将文本提示与拼贴画般的设计过程相结合。有可能使DALL·E 2与众不同的是,结果似乎避免了通常与人工智能艺术相关的神秘谷效应。

(14)Tiamat
Tiamat是一款人工智能绘画(AI绘画)工具,其模型和算法完全都是国内本土研发的,操作也很简单,只要输入你想要的画面关键词,然后等待5分钟就可以一幅不错的艺术画作。
Tiamat其实相当于支持中文的强化版 Disco Diffusion,生成图片的速度非常快,操作也很简单。
输入关键词,然后等待5分钟就可以一幅不错的艺术画作。同时,大家还可以调整类似 生成数量、图片比例等简单参数指令。
这款工具还有一个更高阶的玩法,可以以某张照片或草稿图作为垫图,让AI基于这张垫图进行二次创作。目前,Tiamat正在内测中。
(15)Parti

Parti,全名叫「Pathways Autoregressive Text-to-Image」,是谷歌大脑老大Jeff Dean提出的多任务AI大模型蓝图Pathway的一部分。 Parti是一个自回归模型,它的方法首先将一组图像转换为一系列代码条目,类似于拼图。然后将给定的文本提示转换为这些代码条目并「拼成」一个新图像。 换言之,Parti将「文本到图像的生成」转换成一个「序列到序列」的建模问题,类似于机器翻译——这使得它能够受益于大型语言模型(如PaLM),这对于处理长而复杂的文本提示和生成高质量的图像至关重要。 在这种情况下,目标输出是图像token的序列,而不是另一种语言的文本token。 Parti通过使用功能强大的图像标记器「ViT-VQGAN」将图像编码为离散token序列,并利用其重建图像token序列的能力,使其成为高质量、视觉多样化的图像。
(16)6pen.art
6pen 支持图像尺寸,参考图,随机种子等核心功能。另外,6pen支持中文,而且汇总了不同的绘画风格,用户在输入文字描述的同时,还可以选择水墨画、油画、素描等风格,同时还可以选择仙境、赛博朋克、超现实等风格修饰。
根据官方介绍,6pen还支持将你生成的作品投稿到有奖展览,在社区中展示,以创造更多价值。
(17)无界版图
无界版图是杭州超节点信息科技有限公司创立的数字版权在线拍卖平台,依托区块链技术在资产确权、拍卖⽅⾯的优势,全面整合全球优质艺术资源,致力于为艺术家、创作者提供数字作品的版权登记、保护、使⽤与拍卖等⼀整套解决⽅案,同时也是新媒体、设计、⼴告、各类垂直⾏业及个⼈⽤户购买诸如摄影、插画、纯艺术、数字艺术的聚集地。 杭州超节点信息科技有限公司目前已发展成集资讯内容、线下活动、培训、加速器和区块链技术落地应用于一体的生态体平台,全网覆盖用户超100万人,遍及中国大陆、韩国、日本、美国、香港等国家和地区。
(18)盗梦师
盗梦师是一个能根据输入文本生成图片的 AI 平台,属于AIGC(AI-Generated Content,即人工智能生成内容)的分支,由蓝振忠博士带领的西湖大学深度学习实验室和西湖心辰科技有限公司共同推出。
在用户发挥想象,输入文字描述后,盗梦师便可生成1:1、9:16和16:9三种比例的图片,还有24种绘画风格可以选择——除了基础的油画、水彩、素描等绘画种类,还包括赛博朋克、蒸汽波、像素艺术、吉卜力和 CG 渲染等特别风格。
如果用户有明确想要生成的艺术家风格,还能在毕加索、梵高、莫奈等11位艺术家中进行选择。
参考文献
[1] 封神榜团队开源代码参考 https://github.com/IDEA-CCNL/stable-diffusion-webui
[2] 封神榜团队开源太乙模型 https://huggingface.co/IDEA-CCNL/Taiyi-Stable-Diffusion-1B-Chinese-v0.1
[3] 【腾讯文档】太乙绘画使用手册1.1 https://docs.qq.com/doc/DWklwWkVvSFVwUE9Q
[4] AI画《三体》名场面 https://www.bilibili.com/video/BV1b14y1W7iq
最后
以上就是执着石头最近收集整理的关于使用stable diffusion webui在本地搭建中文的AI绘图模型的全部内容,更多相关使用stable内容请搜索靠谱客的其他文章。








发表评论 取消回复