1、RDD的局限性
- RDD仅表示数据集,RDD没有元数据,也就是说没有字段语义定义。
- RDD需要用户自己优化程序,对程序员要求较高。
- 从不同数据源读取数据相对困难。
- 合并多个数据源中的数据也较困难。
2 DataFrame和Dataset
(1)DataFrame
由于RDD的局限性,Spark产生了DataFrame。
DataFrame=RDD+Schema
其中Schema是就是元数据,是语义描述信息。
在Spark1.3之前,DataFrame被称为SchemaRDD。以行为单位构成的分布式数据集合,按照列赋予不同的名称。对select、filter、aggregation和sort等操作符的抽象。
- 内部数据无类型,统一为Row
- DataFrame是一种特殊类型的Dataset
- DataFrame自带优化器Catalyst,可以自动优化程序。
- DataFrame提供了一整套的Data Source API。
(2)Dataset
由于DataFrame的数据类型统一是Row,所以DataFrame也是有缺点的。
-
- Row运行时类型检查
比如salary是字符串类型,下面语句也只有运行时才进行类型检查。
- Row运行时类型检查
dataframe.filter("salary>1000").show()- Row不能直接操作domain对象
- 函数风格编程,没有面向对象风格的API
所以,Spark SQL引入了Dataset,扩展了DataFrame API,提供了编译时类型检查,面向对象风格的API。
Dataset可以和DataFrame、RDD相互转换。
DataFrame = Dataset[Row]可见DataFrame是一种特殊的Dataset。
3 为什么需要DataFrame和Dataset?
我们知道Spark SQL提供了两种方式操作数据:
- SQL查询
- DataFrame和Dataset API
既然Spark SQL提供了SQL访问方式,那为什么还需要DataFrame和Dataset的API呢?
这是因为SQL语句虽然简单,但是SQL的表达能力却是有限的(所以Oracle数据库提供了PL/SQL)。DataFrame和Dataset可以采用更加通用的语言(Scala或Python)来表达用户的查询请求。此外,Dataset可以更快扑捉错误,因为SQL是运行时捕获异常,而Dataset是编译时检查错误。
4 基本步骤
- 创建SparkSession对象
SparkSession封装了Spark SQL执行环境信息,是所有Spark SQL程序唯一的入口。 - 创建DataFrame或Dataset
Spark SQL支持多种数据源 - 在DataFrame或Dataset之上进行转换和Action
Spark SQL提供了多钟转换和Action函数 - 返回结果
保存结果到HDFS中,或直接打印出来 。
步骤1:创建SparkSession对象
val spark=SparkSessin.builder
.master("local")
.appName("spark session example")
.getOrCreate()注意:SparkSession中封装了spark.sparkContext和spark.sqlContext
后面所有程序或程序片段中出现的spark变量均是SparkSession对象
将RDD隐式转换为DataFrame
import spark.implicits._步骤2:创建DataFrame或Dataset
提供了读写各种格式数据的API,包括常见的JSON,JDBC,Parquet,HDFS
步骤3:在DataFrame或Dataset之上进行各种操作 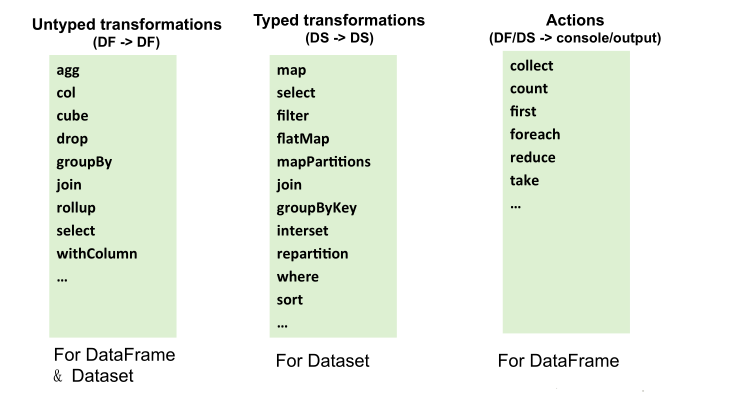
5 实例演示
(1)进入spark-shell
[root@node1 ~]# spark-shell
17/10/13 10:05:57 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Spark context Web UI available at http://192.168.80.131:4040
Spark context available as 'sc' (master = local[*], app id = local-1507903559300).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_ / _ / _ `/ __/ '_/
/___/ .__/_,_/_/ /_/_ version 2.2.0
/_/
Using Scala version 2.11.8 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_112)
Type in expressions to have them evaluated.
Type :help for more information.
scala> 这里的Spark session对象是对Spark context对象的进一步封装。也就是说Spark session对象(spark)中的SparkContext就是Spark context对象(sc),从下面输出信息可以验证。
scala> spark.sparkContext
res0: org.apache.spark.SparkContext = org.apache.spark.SparkContext@7bd7c4cf
scala> println(sc)
org.apache.spark.SparkContext@7bd7c4cf
scala>(2)导入org.apache.spark.sql.Row
scala> import org.apache.spark.sql.Row
import org.apache.spark.sql.Row(3)定义case class
scala> case class User(userID:Long,gender:String,age:Int,occupation:String,zipcode:String)
defined class User
scala> val usersRDD=sc.textFile("file:///root/data/ml-1m/users.dat")
usersRDD: org.apache.spark.rdd.RDD[String] = file:///root/data/ml-1m/users.dat MapPartitionsRDD[3] at textFile at <console>:25
scala> usersRDD.count(4)case class作为RDD的schema
scala> val userRDD =usersRDD.map(_.split("::")).map(p=>User(p(0).toLong,p(1).trim,p(2).toInt,p(3),p(4)))
userRDD: org.apache.spark.rdd.RDD[User] = MapPartitionsRDD[5] at map at <console>:29(5)通过RDD.toDF将RDD转换为DataFrame
scala> val userDF=userRDD.toDF
userDF: org.apache.spark.sql.DataFrame = [userID: bigint, gender: string ... 3 more fields](6)查看DataFrame所以方法
输入userDF.,然后tab键,可以看到DataFrame所以方法
scala> userDF.
agg cube hint randomSplitAsList take
alias describe inputFiles rdd takeAsList
apply distinct intersect reduce toDF
as drop isLocal registerTempTable toJSON
cache dropDuplicates isStreaming repartition toJavaRDD
checkpoint dtypes javaRDD rollup toLocalIterator
coalesce except join sample toString
col explain joinWith schema transform
collect explode limit select union
collectAsList filter map selectExpr unionAll
columns first mapPartitions show unpersist
count flatMap na sort where
createGlobalTempView foreach orderBy sortWithinPartitions withColumn
createOrReplaceGlobalTempView foreachPartition persist sparkSession withColumnRenamed
createOrReplaceTempView groupBy printSchema sqlContext withWatermark
createTempView groupByKey queryExecution stat write
crossJoin head randomSplit storageLevel writeStream
scala>(7)输出DataFrame的Schema
scala> userDF.printSchema
root
|-- userID: long (nullable = false)
|-- gender: string (nullable = true)
|-- age: integer (nullable = false)
|-- occupation: string (nullable = true)
|-- zipcode: string (nullable = true)(8)DataFrame的其他方法
scala> userDF.first
res5: org.apache.spark.sql.Row = [1,F,1,10,48067]
scala> userDF.take(10)
res6: Array[org.apache.spark.sql.Row] = Array([1,F,1,10,48067], [2,M,56,16,70072], [3,M,25,15,55117], [4,M,45,7,02460], [5,M,25,20,55455], [6,F,50,9,55117], [7,M,35,1,06810], [8,M,25,12,11413], [9,M,25,17,61614], [10,F,35,1,95370])
scala>(9)查看DataFrame可以转化的数据格式
输入userDF.write.,然后tab键,可以看到DataFrame可以转化的数据格式
scala> userDF.write.
bucketBy format jdbc mode options parquet save sortBy
csv insertInto json option orc partitionBy saveAsTable text
scala>(10)将DataFrame数据以JSON格式写入HDFS
scala> userDF.write.json("/tmp/json")
scala>(11)查看HDFS
[root@node1 ~]# hdfs dfs -ls /tmp/json
Found 2 items
-rw-r--r-- 3 root supergroup 0 2017-10-13 10:31 /tmp/json/_SUCCESS
-rw-r--r-- 3 root supergroup 442408 2017-10-13 10:31 /tmp/json/part-00000-6f19a241-2f72-4a06-a6bc-81706c89bf5b-c000.json
[root@node1 ~]# (12)也可以写入本地
scala> userDF.write.json("file:///tmp/json")[root@node1 ~]# ls /tmp/json
part-00000-66aa0658-0343-4659-a809-468e4fde23a5-c000.json _SUCCESS
[root@node1 ~]# tail -5 /tmp/json/part-00000-66aa0658-0343-4659-a809-468e4fde23a5-c000.json
{"userID":6036,"gender":"F","age":25,"occupation":"15","zipcode":"32603"}
{"userID":6037,"gender":"F","age":45,"occupation":"1","zipcode":"76006"}
{"userID":6038,"gender":"F","age":56,"occupation":"1","zipcode":"14706"}
{"userID":6039,"gender":"F","age":45,"occupation":"0","zipcode":"01060"}
{"userID":6040,"gender":"M","age":25,"occupation":"6","zipcode":"11106"}
[root@node1 ~]# (13)查看Spark SQL可以读的数据格式
scala> val df=spark.read.
csv format jdbc json load option options orc parquet schema table text textFile
scala>(14)将JSON文件转化为DataFrame
scala> val df=spark.read.json("/tmp/json")
df: org.apache.spark.sql.DataFrame = [age: bigint, gender: string ... 3 more fields]
scala> df.take(2)
res9: Array[org.apache.spark.sql.Row] = Array([1,F,10,1,48067], [56,M,16,2,70072])
scala>(15)再将DataFrame转化为ORC格式数据(该格式文件是二进制文件)
scala> df.write.orc("file:///tmp/orc")
[root@node1 ~]# ls /tmp/orc
part-00000-09cf3025-cc71-4a76-a35d-a7cef4885be8-c000.snappy.orc _SUCCESS
[root@node1 ~]#(16)读取目录/tmp/orc下的所有orc文件
scala> val orcDF=spark.read.orc("file:///tmp/orc")
orcDF: org.apache.spark.sql.DataFrame = [age: bigint, gender: string ... 3 more fields]
scala> orcDF.first
res11: org.apache.spark.sql.Row = [1,F,10,1,48067]
scala>6 select和filter
(1)select
scala> userDF.select("UserID","age").show
+------+---+
|UserID|age|
+------+---+
| 1| 1|
| 2| 56|
| 3| 25|
| 4| 45|
| 5| 25|
| 6| 50|
| 7| 35|
| 8| 25|
| 9| 25|
| 10| 35|
| 11| 25|
| 12| 25|
| 13| 45|
| 14| 35|
| 15| 25|
| 16| 35|
| 17| 50|
| 18| 18|
| 19| 1|
| 20| 25|
+------+---+
only showing top 20 rows
scala> userDF.select("UserID","age").show(2)
+------+---+
|UserID|age|
+------+---+
| 1| 1|
| 2| 56|
+------+---+
only showing top 2 rows
scala> userDF.selectExpr("UserID","ceil(age/10) as newAge").show(2)
+------+------+
|UserID|newAge|
+------+------+
| 1| 1|
| 2| 6|
+------+------+
only showing top 2 rows
scala> userDF.select(max('age),min('age),avg('age)).show(2)
+--------+--------+------------------+
|max(age)|min(age)| avg(age)|
+--------+--------+------------------+
| 56| 1|30.639238410596025|
+--------+--------+------------------+
**(2)filter**
scala> userDF.filter(userDF("age")>30).show(2)
+------+------+---+----------+-------+
|userID|gender|age|occupation|zipcode|
+------+------+---+----------+-------+
| 2| M| 56| 16| 70072|
| 4| M| 45| 7| 02460|
+------+------+---+----------+-------+
only showing top 2 rows
scala> userDF.filter("age>30 and occupation=10").show(2)
+------+------+---+----------+-------+
|userID|gender|age|occupation|zipcode|
+------+------+---+----------+-------+
| 4562| M| 35| 10| 94133|
| 5223| M| 56| 10| 11361|
+------+------+---+----------+-------+
scala>(3)select和filter组合
scala> userDF.select("userID","age").filter("age>30").show(2)
+------+---+
|userID|age|
+------+---+
| 2| 56|
| 4| 45|
+------+---+
only showing top 2 rows
scala> userDF.filter("age>30").select("userID","age").show(2)
+------+---+
|userID|age|
+------+---+
| 2| 56|
| 4| 45|
+------+---+
only showing top 2 rows7 groupBy
scala> userDF.groupBy("age").count.show
+---+-----+
|age|count|
+---+-----+
| 1| 222|
| 35| 1193|
| 50| 496|
| 45| 550|
| 25| 2096|
| 56| 380|
| 18| 1103|
+---+-----+
scala> userDF.groupBy("age").agg(count('gender),countDistinct('occupation)).show
+---+-------------+--------------------------+
|age|count(gender)|count(DISTINCT occupation)|
+---+-------------+--------------------------+
| 1| 222| 13|
| 35| 1193| 21|
| 50| 496| 20|
| 45| 550| 20|
| 25| 2096| 20|
| 56| 380| 20|
| 18| 1103| 20|
+---+-------------+--------------------------+
scala> userDF.groupBy("age").agg("gender"->"count","occupation"->"count").show
+---+-------------+-----------------+
|age|count(gender)|count(occupation)|
+---+-------------+-----------------+
| 1| 222| 222|
| 35| 1193| 1193|
| 50| 496| 496|
| 45| 550| 550|
| 25| 2096| 2096|
| 56| 380| 380|
| 18| 1103| 1103|
+---+-------------+-----------------+
scala> 8 join
问题:求解看过movieID=2116电影的观众的性别与年龄的分布。
(1)Users DataFrame
scala> userDF.printSchema
root
|-- userID: long (nullable = false)
|-- gender: string (nullable = true)
|-- age: integer (nullable = false)
|-- occupation: string (nullable = true)
|-- zipcode: string (nullable = true)
scala>(2)Ratings DataFrame
scala> case class Rating(userID:Long,movieID:Long,Rating:Int,Timestamp:String)
defined class Rating
scala> val ratingsRDD=sc.textFile("file:///root/data/ml-1m/ratings.dat")
ratingsRDD: org.apache.spark.rdd.RDD[String] = file:///root/data/ml-1m/ratings.dat MapPartitionsRDD[65] at textFile at <console>:25
scala> val ratingRDD =ratingsRDD.map(_.split("::")).map(p=>Rating(p(0).toLong,p(1).toLong,p(2).toInt,p(3)))
ratingRDD: org.apache.spark.rdd.RDD[Rating] = MapPartitionsRDD[67] at map at <console>:29
scala> val ratingDF=ratingRDD.toDF
ratingDF: org.apache.spark.sql.DataFrame = [userID: bigint, movieID: bigint ... 2 more fields]
scala> scala> ratingDF.printSchema
root
|-- userID: long (nullable = false)
|-- movieID: long (nullable = false)
|-- Rating: integer (nullable = false)
|-- Timestamp: string (nullable = true)
scala>(2)join
scala> val mergeredDF=ratingDF.filter("movieID=2116").join(userDF,"userID").select("gender","age").groupBy("gender","age").count
mergeredDF: org.apache.spark.sql.DataFrame = [gender: string, age: int ... 1 more field]
scala> mergeredDF.show
+------+---+-----+
|gender|age|count|
+------+---+-----+
| M| 18| 72|
| F| 18| 9|
| M| 56| 8|
| M| 45| 26|
| F| 45| 3|
| M| 25| 169|
| F| 56| 2|
| M| 1| 13|
| F| 1| 4|
| F| 50| 3|
| M| 50| 22|
| F| 25| 28|
| F| 35| 13|
| M| 35| 66|
+------+---+-----+
scala> 9 临时表
scala> userDF.createOrReplaceTempView("users")
scala> val groupedUsers=spark.sql("select gender,age,count(*) as num from users group by gender, age")
groupedUsers: org.apache.spark.sql.DataFrame = [gender: string, age: int ... 1 more field]
scala> groupedUsers.show
+------+---+----+
|gender|age| num|
+------+---+----+
| M| 18| 805|
| F| 18| 298|
| M| 56| 278|
| M| 45| 361|
| F| 45| 189|
| M| 25|1538|
| F| 56| 102|
| M| 1| 144|
| F| 1| 78|
| F| 50| 146|
| M| 50| 350|
| F| 25| 558|
| F| 35| 338|
| M| 35| 855|
+------+---+----+
scala>注意:在Spark程序运行中,临时表才存在。当Spark程序运行结束,临时表也被销毁。
10 Spark SQL的表
(1)Session范围内的临时表
- df.createOrReplaceTempView(“tableName”)
- 只在Session范围内有效,Session结束临时表自动销毁
(2)全局范围内的临时表
- df.createGlobalTempView(“tableName”)
- 所有Session共享
scala> userDF.createGlobalTempView("users")
scala> spark.sql("select * from global_temp.users").show
+------+------+---+----------+-------+
|userID|gender|age|occupation|zipcode|
+------+------+---+----------+-------+
| 1| F| 1| 10| 48067|
| 2| M| 56| 16| 70072|
| 3| M| 25| 15| 55117|
| 4| M| 45| 7| 02460|
| 5| M| 25| 20| 55455|
| 6| F| 50| 9| 55117|
| 7| M| 35| 1| 06810|
| 8| M| 25| 12| 11413|
| 9| M| 25| 17| 61614|
| 10| F| 35| 1| 95370|
| 11| F| 25| 1| 04093|
| 12| M| 25| 12| 32793|
| 13| M| 45| 1| 93304|
| 14| M| 35| 0| 60126|
| 15| M| 25| 7| 22903|
| 16| F| 35| 0| 20670|
| 17| M| 50| 1| 95350|
| 18| F| 18| 3| 95825|
| 19| M| 1| 10| 48073|
| 20| M| 25| 14| 55113|
+------+------+---+----------+-------+
only showing top 20 rows
scala> spark.newSession().sql("select * from global_temp.users").show
+------+------+---+----------+-------+
|userID|gender|age|occupation|zipcode|
+------+------+---+----------+-------+
| 1| F| 1| 10| 48067|
| 2| M| 56| 16| 70072|
| 3| M| 25| 15| 55117|
| 4| M| 45| 7| 02460|
| 5| M| 25| 20| 55455|
| 6| F| 50| 9| 55117|
| 7| M| 35| 1| 06810|
| 8| M| 25| 12| 11413|
| 9| M| 25| 17| 61614|
| 10| F| 35| 1| 95370|
| 11| F| 25| 1| 04093|
| 12| M| 25| 12| 32793|
| 13| M| 45| 1| 93304|
| 14| M| 35| 0| 60126|
| 15| M| 25| 7| 22903|
| 16| F| 35| 0| 20670|
| 17| M| 50| 1| 95350|
| 18| F| 18| 3| 95825|
| 19| M| 1| 10| 48073|
| 20| M| 25| 14| 55113|
+------+------+---+----------+-------+
only showing top 20 rows
scala> (3)将DataFrame或Dataset持久化到Hive中
df.write.mode(“overwrite”).saveAsTable(“database.tableName”)最后
以上就是踏实小海豚最近收集整理的关于Spark2.x学习笔记:Spark SQL程序设计的全部内容,更多相关Spark2.x学习笔记:Spark内容请搜索靠谱客的其他文章。








发表评论 取消回复