一.基本算子

中文翻译:

二.updateStateByKey
updateStateByKey操作可以保持任意状态,同时不断用新信息更新它。要使用此功能,必须执行两个步骤。
- 定义状态-状态可以是任意数据类型。
- 定义状态更新功能-使用功能指定如何使用输入流中的先前状态和新值来更新状态。
在每个批次中,Spark都会对所有现有密钥应用状态更新功能,而不管它们是否在批次中具有新数据。如果更新函数返回,None将删除键值对。
让我们用一个例子来说明。假设要保持在文本数据流中看到的每个单词的连续计数。此处,运行计数是状态,它是整数。将更新函数定义为:
def updateFunction(newValues: Seq[Int], runningCount: Option[Int]): Option[Int] = {
val newCount = ... // add the new values with the previous running count to get the new count
Some(newCount)
}
这适用于包含单词的DStream【wordcount会把单词映射为(word, 1)对的DStream】。
调用如下:
val runningCounts = pairs.updateStateByKey[Int](updateFunction _)
将为每个单词调用更新函数,每个单词newValues的序列为1(来自各(word, 1)对),并且runningCount具有先前的计数。
请注意,使用updateStateByKey需要配置检查点目录。
ssc.checkpoint("D:\checkpoint")
完整代码:
package spark2.streaming
import org.apache.log4j.{Level, Logger}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* Created by Administrator on 2020/5/7.
*/
object UpdateStateByKey {
/**
* 累加
* @param newValues 当前周期新数据的值
* @param runningCount 历史累计值
* @return
*/
def updateFunction(newValues : Seq[Int], runningCount : Option[Int]) : Option[Int] = {
val preCount = runningCount.getOrElse(0)
val newCount = newValues.sum
Some(newCount + preCount) // 累加
}
Logger.getLogger("org").setLevel(Level.WARN) // 设置日志级别
def main(args: Array[String]) {
val conf = new SparkConf().setMaster("local[2]").setAppName(s"${this.getClass.getSimpleName}")
val ssc = new StreamingContext(conf,Seconds(5))
// 设置检测点
ssc.checkpoint("E:\checkpoint")
val lines = ssc.socketTextStream("master",9999) // 与nc端口对应
val words = lines.flatMap(_.split(" "))
var pairs = words.map(word=>(word,1)).reduceByKey(_+_)
// 累加
pairs = pairs.updateStateByKey[Int](updateFunction _) // 必须设置检查点
pairs.foreachRDD(row => row.foreach(println))
ssc.start()
ssc.awaitTermination()
ssc.stop()
}
}
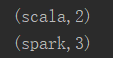
执行结果:


三.Transform
transform操作【及其类似的变体transformWith】允许将任意RDD-to-RDD功能应用于DStream。它可用于应用DStream API中未公开的任何RDD操作。例如,将数据流中的每个rdd与另一个数据集连接在一起的功能未直接在DStream API中公开。但是,可以轻松地使用transform来执行此操作。这实现了非常强大的可能性。例如,可以通过将输入数据流与预先计算的垃圾邮件信息【也可能由Spark生成】结合在一起,然后基于该信息进行过滤来进行实时数据清理。
val spamInfoRDD = ssc.sparkContext.newAPIHadoopRDD(...) // RDD containing spam information
val cleanedDStream = wordCounts.transform { rdd =>
rdd.join(spamInfoRDD).filter(...) // join data stream with spam information to do data cleaning
...
}
请注意,在每个批处理间隔中都会调用提供的函数。这使得可以执行随时间变化的RDD操作,即可以在批之间更改RDD操作,分区数,广播变量等。
完整代码:
package spark2.streaming
import org.apache.log4j.{Level, Logger}
import org.apache.spark.sql.SparkSession
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* Created by Administrator on 2020/6/23.
*/
object StreamingTransform {
Logger.getLogger("org").setLevel(Level.WARN) // 设置日志级别
def main(args: Array[String]) {
val spark = SparkSession.builder()
.appName(s"${this.getClass.getSimpleName}")
.master("local[2]")
.getOrCreate()
val sc = spark.sparkContext
/**
* 生成数据集,黑名单,写在ssc之前,避免多次执行
*/
val array = Array[String]("spark,1", "flink,0", "storm,0")
val filters = sc.parallelize(array).map(row => (row.split(",")(0), row.split(",")(1).toInt))
filters.count()
filters.foreach(println)
val ssc = new StreamingContext(sc,Seconds(5))
val lines = ssc.socketTextStream("master",9999) // 与nc端口对应
val words = lines.flatMap(_.split(" "))
val pairs = words.map(word=>(word, 1)).reduceByKey(_+_)
/**
* 关联
*/
pairs.foreachRDD(rdd =>{
val mid = rdd.leftOuterJoin(filters).map(row =>{
val filter = row._2._2 match { // 模式匹配
case Some(a) => a
case None => 0
}
(row._1, row._2._1, filter)
})
.filter(_._3 == 1) // filter == 1
.map(row => (row._1, row._2))
mid.foreach(println)
})
ssc.start()
ssc.awaitTermination()
ssc.stop()
}
}
执行结果:
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
20/06/23 20:20:43 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
(flink,0)
(spark,1)
(storm,0)
20/06/23 20:21:01 WARN RandomBlockReplicationPolicy: Expecting 1 replicas with only 0 peer/s.
20/06/23 20:21:01 WARN BlockManager: Block input-0-1592914861200 replicated to only 0 peer(s) instead of 1 peers
(spark,1)
20/06/23 20:21:33 WARN RandomBlockReplicationPolicy: Expecting 1 replicas with only 0 peer/s.
20/06/23 20:21:33 WARN BlockManager: Block input-0-1592914893200 replicated to only 0 peer(s) instead of 1 peers
(spark,2)
最后
以上就是激情小丸子最近收集整理的关于Sparkstreaming常用算子详解的全部内容,更多相关Sparkstreaming常用算子详解内容请搜索靠谱客的其他文章。








发表评论 取消回复