老板扔给了我一个陈年语料,让我通过文章标题回原网址爬取一下对应的doi号,文章很好定位,但是在解析标题的时候遇到了问题,a标签中混合了i、sub、sup标签,在使用xpath时不能直接使用text方法获取,所以在这里记录一下自己的解决方案。
(想不到,做完这个任务,我顺便学会了希腊字母的读音:^)
1 xpath定位
本篇博客以抓取我的主页中的某条标题为例。鼠标右键要爬的内容,点击“检查”,然后继续右键定位到的内容,选择copy,然后Copy Xpath,就可以获得xpath表达式讲真,作为懒人,我喜欢这个定位,这样就不用像beautifulSoup中那样一点点的写定位的元素了。具体操作如下图所示。
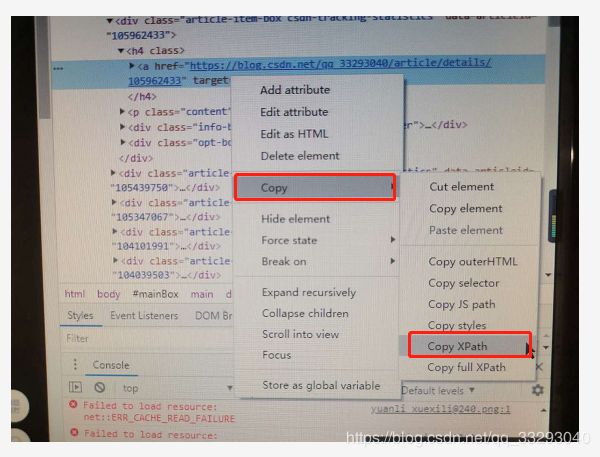 图1 获取XPath操作
图1 获取XPath操作
获得了XPath路径之后,就可以在直接使用lxml包进行解析。操作样例如下:
import requests
from lxml import html
etree = html.etree
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/79.0.3945.130 Safari/53
最后
以上就是能干大白最近收集整理的关于python xpath定位 嵌套标签_python爬虫中使用Xpath方法定位a标签中所有的子标签的方法...的全部内容,更多相关python内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复