- 正则表达式
- grep
- sed (Stream EDitor:流编辑)
- awk
1.正则表达式
1.1元字符定义及使用场景
定义:元字符是这样一类字符,它们表达的是不同于字面本身的含义 ; 被vim、sed、awk、grep调用 ;在 mysql、oracle、php、python ,Apache,Nginx... 需要正则
1.2元字符分类之--基本正则表达式元字符
^ 行首定位符
$ 行尾定位符
. 匹配任意单个字符
* 匹配前导符0到多次.* 任意多个字符
[ ] 匹配指定范围内的一个字符
[ - ] 匹配指定范围内的一个字符,连续的范围
[^] 匹配不在指定组内的字符
用来转义元字符 ('' "" ),脱意符
< 词首定位符
> 词尾定位符
() (..) 匹配稍后使用的字符的标签
x{m} 字符x重复出现m次
x{m,} 字符x重复出现m次以上
x{m,n} 字符x重复出现m到n次
1.3元字符分类之--扩展正则表达式元字符
+ 匹配1~n个前导字符
? 匹配0~1个前导字符
a|b 匹配a或b
() 组字符
1.4示例
grep love 1.txt 找love
/^love/ 以love开头
/love$/ 以love结尾
/l.ve/ l开始,一个任意字符,ve结尾
/lo*ve/ l开始,零个或多个o,ve结尾
/[Ll]ove/ 大L 或者小L 开头的 ove
/love[a-z]/ love最后一个小写字母
/love[^a-zA-Z0-9]/ love最后一个(不是字母或者数字),而是符号
/.*/ 所有行 [root@localhost ~]# egrep ".*" 1.txt | wc
/^$/ 空行
/^[A-Z]..$/ 开头一个大写,最后2个任意字符
/^[A-Z][a-z ]*3[0-5]/ 一个大写开头,0到多个小写或空格,3,最后是0-5的一个数字
/[a-z]*./ 0到多个小写字母,最后一个点
/^ *[A-Z][a-z][a-z]$/ 0到多个空格开头,一个大写,一个小写,再一个小写结尾
/^[A-Za-z]*[^,][A-Za-z]*$/ 0到多个字母开头,非逗号,0到多个英文结尾
/<fourth>/ 找个单词
/<f.*th>/ 找单词
/5{2}2{3}./ 5两次2三次和一个点
/^[ t]*$/ 0到多个 ,空格或tab的行
/^#/ 井号开头的行
/^[ t]*#/ 有0到多个,空格或者tab开头的行,的注释行
:1,$ s/([Oo]ccur)ence/1rence/ 多个r
:1,$ s/(square) and (fair)/2 and 1/ 换个位置
2.grep
2.1目的
过滤,查找文档中的内容
2.2分类
egrep 扩展支持正则 ; fgrep 就不支持正则 ; grep
2.3返回值
0 是找到了 表示成功; 1 是没有 表示在所提供的文件无法找到匹配的pattern ;2 找到地儿不对
测试:
2.4参数
grep -q 静默
grep -v 取反
grep -R 可以查目录下面的文件
grep -o 只找到这个关键字就可以
grep -B2前两行
grep -A2后两行
grep -C2上下两行
egrep -l 只要文件名
egrep -n 带行号
2.sed (Stream EDitor:流编辑)
2.1简介
sed 是一种在线的、非交互式的编辑器,它一次处理一行内容。处理时,把当前处理的行存储在临时缓冲区中,称为“模式空间”(pattern space),接着用sed命令处理缓冲区中的内容,处理完成后,把缓冲区的内容送往屏幕。
接着处理下一行,这样不断重复,直到文件末尾。文件内容并没有改变,除非你使用重定向存储输出。Sed主要用来自动编辑一个或多个文件;简化对文件的反复操作;
2.2格式
1 sed 选项 命令 文件 sed [options] 'command' file(s)
2 sed 选项 –f 脚本 文件 sed [options] -f scriptfile file(s)
2.3返回值
都是0,对错不管。只有当命令存在语法错误时,sed的退出状态才是非0
2.4sed和正则表达式
与grep一样,sed在文件中查找模式时也可以使用正则表达式(RE)和各种元字符。正则表达式是括在斜杠间的模式,用于查找和替换,以下是sed支持的元字符。
使用基本元字符集 ^, $, ., *, [], [^], < >,(),{}
使用扩展元字符集 ?, +, |, ( )使用扩展元字符的方式:
+ 转义
sed -r 加-r
2.5测试
(1)删除命令:d
sed -r '/root/d' passwd 匹配删除“root”行
sed -r '3d' passwd 删除第三行
sed -r '3{d}' passwd 删除第三行
# sed -r '3{d;}' passwd {存放sed的多个命令} 3{h;d},h暂存空间
sed -r '3,$d' passwd 删除3到最后一行
sed -r '$d' passwd 删除最后一行
(2)替换命令:s
sed -r 's/root/aofa/' passwd 把“root“换成”aofo“
sed -r 's/^root/aofa/' passwd 以root开始的词组,替换成aofa
sed -r 's/root/aofa/g' passwd 全局替换"root"成为"sofo"
sed -r 's/[0-9][0-9]$/&.5/' passwd 查找双数 结尾的词组;&:替换成 双数.5;&有查询结果的含义。
VI中也有类似功能。
:% s/.*/#&/g &:查询结果的含义
:% s/(.*)/#1/g 每一行;换成
sed -r 's/(mail)/E1/g' passwd ()括号组合字符,1调用括号sed -r 's#(mail)#E1#g' passwd 分隔符可以换成井号
(3)读文件命令:r
sed -r '$r 1.txt' passwd 最后一行,读取新文件1.txt
sed -r '/root/r 1.txt' passwd 正则搜寻root;在root后面读取新文件
***在当前文件中,读取其他文件“部分”内容。
(4)写文件命令:w(另存为)
sed -r 'w 111.txt' 1.txt 把1.txt全部内容 写入111.txt
sed -r '/root/w 123.txt' passwd 把1.txt 写入111.txt
sed -r '1,5w 123.txt' passwd 把1,5行另存为123.txt
(5)追加命令: a(之后)
# sed -r '2a123' passwd 2行后面,加上123行
# sed -r 'a123' passwd 每行后面,都加上123行
sed -r '2a 1111
> 3333333
> 444444' passwd 插入段落,请使用转义掉回车,不要忘了分号结束
(6)插入命令: i(之前)
# sed -r '2iaaaaaaaa' passwd 在第二行插入新行aaaaaaaaaa
(7)替换整行命令: c
# sed -r '2caaaaaaaa' passwd 把第二行替换成aaaaaaaaa
sed -r '2c3333
> 44444' passwd 一行替换多行 是将一行替换成,多行。
(8)获取下一行命令:n
# sed -r '/root/{n;d}' passwd n下一行的意思。找root行,然后下一行,删除
# sed -r '/root/{n;s/bin/ding/g}' passwd {命令组合} 找到root行,下一行查找替换
(9)反向选择: !
# sed -r '2,$!d' passwd 原本的意思是删除第二行到最后一行,加入”!“之后就是删除第一行
(10)多重编辑 : e
# sed -r -e '1,3d' -e '4s/adm/admin/g' passwd 删除1到3行,再把第4行adm换成admin
# sed -r '1,3d;4s/adm/admin/g' passwd 同上,第4行整行匹配替换
# sed -r '2s/bin/ding/g;2s/nologin/bash/' passwd 第二行bin换成ding,nologin换成bash
# sed -r '2{s/bin/ding/g;s/nologin/bash/}' passwd 括号省了范围
(11)暂存空间 hHGgx
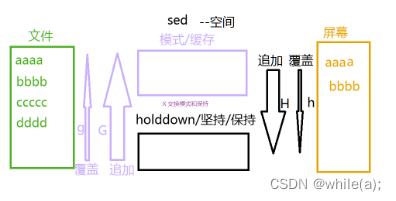
暂存和取用命令:h覆盖暂存空间 H追加暂存空间 g覆盖行 G追加行
# sed -r 'g' passwd 为什么是空白一片
# sed -r 'G' passwd G是从暂存空间,追加到模式空间。
# sed -r '1h;$G' passwd 第一行覆盖到暂存空间;将暂存空间的内容追加到最后一行
# sed -r '1h;2G;3G;$G' passwd 第一行覆盖到暂存空间,2后面多一行,3后面多一行,10后面多一行
# sed -r '1{h;d};$G' passwd 第一行进入暂存空间,第一行在模式空间中删除,将暂存空间最佳到最后一行。
# sed -r '1h;2,$g' passwd 第一行进入暂存空间;将暂存空间覆盖在,2到最后一行,
# sed -r '1h;2,3H;$G' passwd 第一行进入暂存空间;2,3行追加进攒存空间;将暂存的内容追加到最后一行
# sed -r '4h;5x;6G' passwd 第四行进入暂存空间;将模式空间第五行和暂存空间互换,将暂存空间的内容追加到第六行。
(12)测试
删除配置文件中#号注释行 # sed -r '/^#/d' /etc/samba/smb.conf
祖传牛皮癣专治老中医 # sed -r '/^[ t]*#/d' space.txt 删除:以0个和多个空,或者tab,以及#号开始的行
删除配置文件中//号注释行 # sed -r 'Y^[ t]*//Yd' space.txt 由于分隔符也是/,所以使用自定义分隔符Y。
删除无内容空行 # sed -r '/^[ t]*$/d' space.txt $即代表空行。
删除注释行及空行另类写法:
# sed -ri '/^[ t]*#/d; /^[ t]*$/d' /etc/vsftpd/vsftpd.conf 都是删除#行和空行
# sed -ri '/^[ t]*#|^[ t]*$/d' /etc/vsftpd/vsftpd.conf 都是删除#行和空行,区别在于使用了 “A|B” A或B
# sed -ri '/^[ t]*($|#)/d' /etc/vsftpd/vsftpd.conf 第三行用括号和$|#进行双选。()进行了组词
修改文件:
# sed -ri '$achroot_local_user=YES' /etc/vsftpd/vsftpd.conf 在最后一行追加
# sed -ri '/^SELINUX=/cSELINUX=disabled' /etc/selinux/config 换行c
给文件行添加注释:
# sed -r '2,6s/^/#/' a.txt 找到2到6行,把开始换成#
# sed -r '2,6s/(.*)/#1/' a.txt ()内容可以被1引用
# sed -r '2,6s/.*/#&/' a.txt &匹配前面查找的内容
多个#换成一个#:
# sed -r 's/^#*/#/g' 文件名
# sed -r '30,50s/^[ t]*#*/#/' /etc/nginx.conf
# sed -r '2,8s/^[ t#]*/#/' /etc/nginx.conf
sed中使用外部变量:
追加变量 # sed -r "1a$var1" /etc/hosts 第一行后追加变量$var1 注意调用变量时,使用单引号是错误的。
4.awk
4.1前言
awk 是一种编程语言,用于在linux/unix下对文本和数据进行处理。
数据可以来自标准输入、一个或多个文件,或其它命令的输出。
它支持用户自定义函数和动态正则表达式等先进功能,
awk的处理文本和数据的方式是这样的,
它逐行扫描文件,从第一行到最后一行,
寻找匹配的特定模式的行,并在这些行上进行你想要的操作。
如果没有指定处理动作,则把匹配的行显示到标准输出(屏幕),awk分别代表其作者姓氏的第一个字母。因为它的作者是三个人,
分别是Alfred Aho、Peter Weinberger、 Kernighan。
4.2工作原理
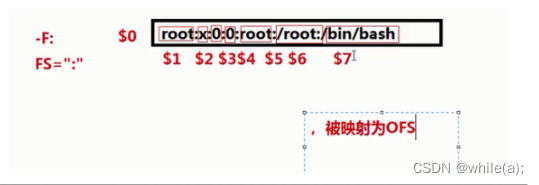
# awk -F: '{print $1,$3}' /etc/passwd
(1)awk使用一行作为输入,并将这一行赋给内部变量$0,每一行也可称为一个记录,以换行符结束(2)然后,行被:(默认为空格或制表符)分解成字段(或域),每个字段存储在已编号的变量中,从$1开始,
最多达100个字段(3)awk输出之后,将从文件中获取另一行,并将其存储在$0中,覆盖原来的内容,然后将新的字符串分隔
成字段并进行处理。该过程将持续到所有行处理完毕
4.3语法
awk [options] 'commands' filenames (推荐)
==options: 例如:-F 定义输入字段分隔符,默认的分隔符是空格或制表符(tab)
==command(时空):BEGIN{} {} END{}
BEGIN{} begin发生在行处理前(注意大写)
{} 行处理时,读一行执行一次
END{} 行处理后
4.4内部变量
(1)FS 输入字段分隔符(默认空格)

(2)OFS 输出字段分隔符

(3)RS 输入记录(行)分隔符,默认换行符

(4)ORS 输出记录(行)分隔符,默认换行符
(5)FNR 多文件独立编号 同下
(6)NR 多文件汇总编号

(7)NF 字段总数

4.5格式化输出
(1)print 函数

(2)printf 函数
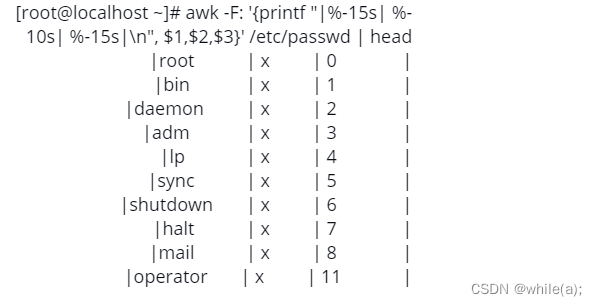
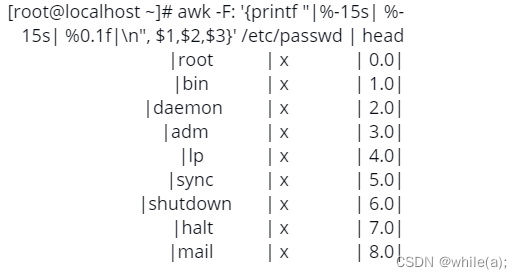
语法:
%s 字符类型
%d 数值类型
%f 浮点型,可以定义保留
占15字符
- 表示左对齐,默认是右对齐
printf默认不会在行尾自动换行,加n
, 逗号,输出字段分隔符
测试:

4.6模式(正则表达)和动作
(1)概念:
任何awk语句都由模式和动作组成。模式部分决定动作语句何时触发及触发事件。
如果省略模式部分,动作将时刻保持执行状态。每一行都会有动作。
模式可以是任何条件语句或复合语句或正则表达式。有模式的话,就是对模式对应的行进行动作。模式:可以是条件测试,正则,复合语句
动作:可以是打印,计算等。
(2)字符串比较:
字符串比较:
# awk '/^root/' /etc/passwd
# awk '$0 ~ /^root/' /etc/passwd
# awk '$0!~/^root/' /etc/passwd
# awk -F: '$1 ~ /^root/' /etc/passwd
(3)数值比较:
目的:
比较表达式采用对文本进行比较,只有当条件为真,才执行指定的动作。比较表达式使用关系运算符,用于比较数字与字符串。关系运算符:
语法
运算符 含义 示例
< 小于 x<y
<= 小于或等于 x<=y
== 等于 x==y
!= 不等于 x!=y
>= 大于等于 x>=y
> 大于 x>y示例
# awk -F: '$3 == 0' /etc/passwd
# awk -F: '$3 == 1' /etc/passwd
# awk -F: '$3 < 10' /etc/passwd
== 也可以用于字符串判断
# awk -F: '$7 == "/bin/bash"' /etc/passwd
# awk -F: '$1 == "alice"' /etc/passwd算术 运算:
语法
+ - * / %(模) ^(幂2^3)示例
# awk -F: '$3 * 10 > 500' /etc/passwd
(4)多条件
逻辑操作符和复合模式:
语法:
&& 逻辑与 a&&b
|| 逻辑或 a||b
! 逻辑非 !a练习:
# awk -F: '$1~/root/ && $3<=15' /etc/passwd
# awk -F: '$1~/root/ || $3<=15' /etc/passwd
# awk -F: '!($1~/root/ || $3<=15)' /etc/passwd范围模式:
语法:
awk '/从哪里/,/到哪里/' filename练习:
# awk -F: '/adm/,/lpd/' /etc/passwd
从adm到ldp,显示出来,注意避免匹配重复的字段。
4.7awk脚本编程
(1)变量
awk调用变量:
自定义内部变量 -v :
awk -v user=root -F: '$1 == user' /etc/passwd -v定义变量外部变量 “ ‘ ” :
1.双引号
# var="bash"
# echo "unix script" | awk "{print "123","$var"}"
123 bash
注意 awk调用外部变量时,外部使用双引号,内部也使用双引号,但需要转义内部的双引号2单引号
# var="bash"
# echo "unix script" |awk '{print $1,"'"$var"'"}'
unix bash
注意使用单引号时,内部需要用双引转义
(2)条件&判断
1.if语句:
格式:
{if(表达式){语句;语句;...}}示例: 如果$3是0,就说他是管理员
awk -F: '{if($3==0) {print $1 " is administrator."}}' /etc/passwd
2.if...else语句:
格式
{if(表达式){语句;语句;...}else{语句;语句;...}} {if(){}else{}}示例: 如果第三列是0,打印该行第一列,否则打印第七列,登录shell
awk -F: '{if($3==0){print $1} else {print $7}}' /etc/passwd
示例: 统计管理员和系统用户数量
awk -F: '{if($3==0){count++} else{i++}} END{print "管理员个数: "count ; print "系统用户数: "i}' /etc/passwd
3.if...else if...else语句:
格式:
if (条件){动作}elseif(条件){动作}else{动作}
if(){}else if (){}else if(){}else{}
示例: 显示出三种用户的信息;管理员:管理员ID为0;内置用户:用户ID<1000普通用户: 用户ID>999
[root@localhost ~]# awk -F: '{if($3==0){print $1," is admin "}else if ($3>999){print $1," is user"}else {print $1, " is sofo user"}}' /etc/passwd
示例: 统计出三种用户的数量;管理员数量:管理员ID为0;内置用户数量:用户ID<1000普通用户数量: 用户ID>999
awk -F: '{if($3==0){i++} else if($3>999){k++} else{j++}} END{print i; print k; print j}' /etc/passwd
awk -F: '{if($3==0){i++} else if($3>999){k++} else{j++}} END{print "管理员个数: "i; print "普通用个数: "k; print "系统用户: "j}' /etc/passwd
(3)循环
1.while:
示例:循环打印10个数字
awk 'BEGIN{ while(i<=10){print i; i++} }'
示例: 将每行打印10次
awk -F: '{ i=1;while(i<=9) {print $0; i++}}' passwd
2.for:
示例:循环打印5个数字
awk 'BEGIN{for(i=1;i<=5;i++){print i} }'
示例:将每行打印10次
awk -F: '{ for(i=1;i<=10;i++) {print $0} }' /etc/passwd
示例:打印每一行的每一列
awk -F: '{ for(i=1;i<=NF;i++) {print $i} }' passwd
(4)数组
1.定义数组:
示例: 将用户名定义为数组的值,打印第一个值
# awk -F: '{username[++i]=$1} END{print username[1]}' /etc/passwd
2.数组遍历:
示例:按索引遍历数组
# awk -F: '{username[x++]=$1} END{for(i in username) {print i,username[i]} }' /etc/passwd
(5)测试
1. 统计/etc/passwd中各种类型shell的数量
awk -F: '{shells[$NF]++} END{ for(i in shells){print i,shells[i]} }' /etc/passwd
$NF 最后一列的字段内容;{}行处理;把统计的对象,作为索引。每次递增。Print i 打印索引;Shells[i] 数组加索引,显示的就是值。
2. 统计Apache/Nginx日志中的访问前十 <统计日志>
cat access_log |awk '{ips[$1]++} END{for(i in ips){print i,ips[i]} }' |sort -k2 -rn |head
最后
以上就是悲凉篮球最近收集整理的关于shell编程--三剑客1.正则表达式2.grep2.sed (Stream EDitor:流编辑)4.awk的全部内容,更多相关shell编程--三剑客1.正则表达式2.grep2.sed 内容请搜索靠谱客的其他文章。








发表评论 取消回复