大家好呀,我是不许????????????。今天让我们一起来学习线性表的存储结构这一块的内容❤️❤️❤️下面有图和例题源码。

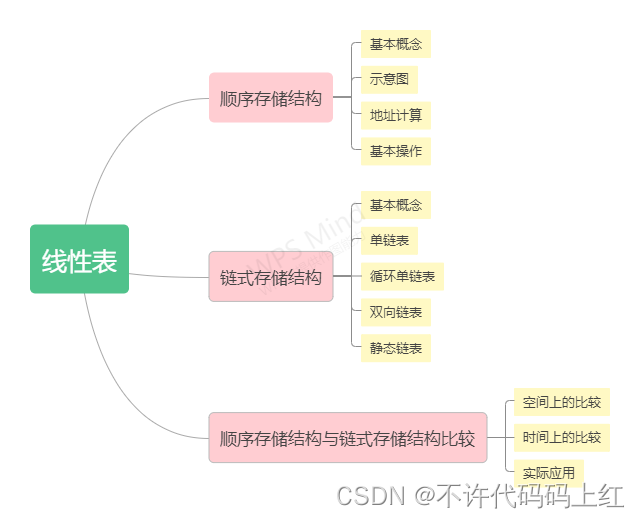
文章目录
- 一、线性表的顺序存储结构
- 1、线性表的顺序存储概念
- 2、存储结构示意图
- 3、地址计算
- 4、创建线性表
- a.通过变量定义语句
- b.通过指针变量定义语句
- 5、初始化线性表
- 6、向线性表插入元素
- 算法思想
- 7、查找某一元素位置
- 算法思想
- a.按序号查找
- b.按内容查找
- 根据输入下标得到对应值
- 根据输入值得到其下标
- 8、删除某一个元素
- 算法思想
- 9、线性顺序表的优缺点
- 优点
- 缺点
- 二、线性表的链式存储结构
- 1、线性表的链式存储概念
- 2、单链表
- LinkList和Node*
- 单链表概念
- 创建结构体
- 初始化单链表
- 查找
- 插入
- 删除
- 有序合并
- 3、循环单链表
- 循环链表概念
- 建立循环单链表
- 插入
- 删除
- 合并
- 计算长度
- 4、双向链表
- 双向链表概念
- 创建结构体
- 初始化
- 插入
- 删除
- 5、静态链表
- 静态链表概念
- 静态链表的创建
- 特点
- 三、顺序表与链表的比较
- 1、空间上
- 2、时间上
- 3、语言上
- 4、链式存储方式比较
一、线性表的顺序存储结构
1、线性表的顺序存储概念
????????????线性表中元素的位序是从1开始的,而数组中元素的下标是从0开始的
顺序存储:指用一组地址连续的存储单元依次存储线性表中的各个元素。
✨✨✨通常采用顺序存储结构的线性表又叫做顺序表
顺序表:关系线性化,结点顺序存。
2、存储结构示意图
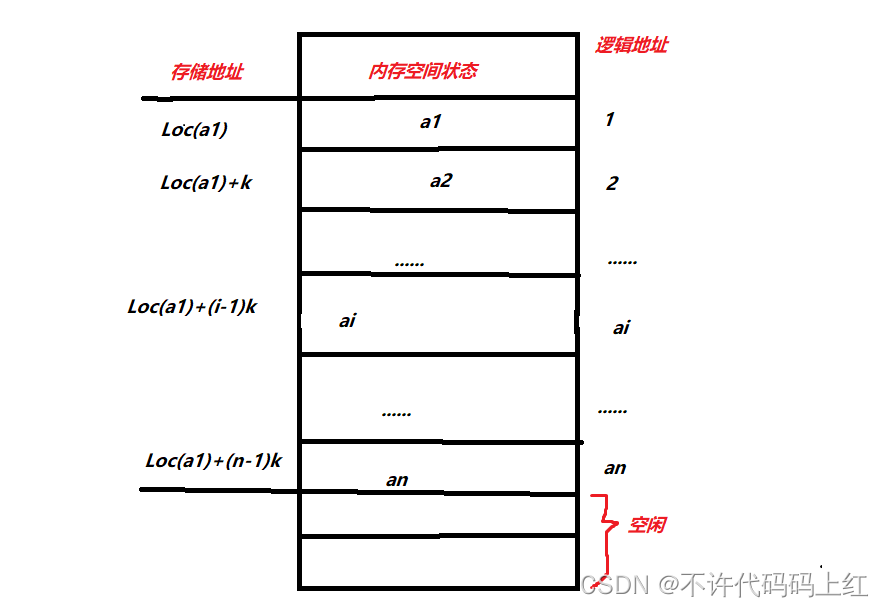
3、地址计算
假设线性表中有n个元素,每个元素占k个单元,第一个元素的地址为Loc(a1),则可通过如下公式计算出第i个元素的地址Loc(ai):
Loc(ai)=Loc(ai)=(i-1)*k
????????????Loc(ai)称为基地址
4、创建线性表
????????????结点类型定义:在实际的应用中,用户可以根据自己的需要来具体定义顺序表中元素的数据类型:
int、char、float或是一种struct结构类型
值得注意的是:
从数组中起始下标为0处开始存放线性表中第一个元素。因此需要区分元素的序号和该元素在数组中的下标位置之间对应的关系,即元素的序号为1,而元素在顺序表对应的数组data中的下标为0。
????????????类型与变量:类型是模板,变量是真正的存储空间
a.通过变量定义语句
????将L定义为SeqList类型变量
SeqList L;
????访问顺序表中序号为i的元素
L.data[i-1]
????得到顺序表中最后一个元素下标
L.last
????顺序表长度
L.last+1
b.通过指针变量定义语句
????将L定义为指向SeqList类型的指针变量
SeqList L1.*L;
L=&L1;
????访问顺序表中序号为i的元素
L->data[i-1]
????得到顺序表长度
L->last+1
#define MAXSIZE 100 // 表中最大元素个数
typedef int ElemType; // 设置表中元素类型为整型
typedef struct {
ElemType data[MAXSIZE + 1]; // 下标0处存放监视哨,数组元素存储1~n单元
int length;
} SqList;
5、初始化线性表
void InitSq(SqList *L)
{
L->length=0;
printf("初始化之后,数组的长度为:%dn",L->length);
printf("-------------------------------------------------n");
}
6、向线性表插入元素
算法思想
用顺序表作为线性表的存储结构时,由于结点的物理顺序必须和结点的逻辑顺序保持一致,因此必须将原来表中位置n,n-1,…,i上的结点依次后移到位置n+1,n,…i+1上,空出第i个位置,然后在该位置插入新结点。当i=n+1时无需移动。
void InsertSq(SqList *L,int i,ElemType e)
{
//首先要判断这个顺序表是否满了
if(i>L->length+1||i<=0)
{
printf("i=%d插入位置不存在n当前表的长度为:%dn",i,L->length);
printf("-------------------------------------------------n");
}
else
{
for(int k=L->length-1;k>=i-1;k--)
{
L->data[k+1]=L->data[k]; //把它后面的都往后移动一位
}
L->data[i-1]=e;
L->length++;//因为此时我们插入了一个元素,数组的长度要加1.
}
}
InsertSq(&s,1,66); //插入一个元素

7、查找某一元素位置
算法思想
查找运算可以采取顺序查找,从第一个元素开始,依次将表中的元素与e相比较,如果相等,查找成功,返回该元素在表中的序号。
a.按序号查找
GetData(L,i):查找顺序表L中第i个数据元素
根据顺序表L的存储特点,表中元素在L的data数组中顺序存放,故GetData的核心语句为L.data[i-1]。
b.按内容查找
Locate(L,e):查找顺序表L中与给定值e相等的数据元素
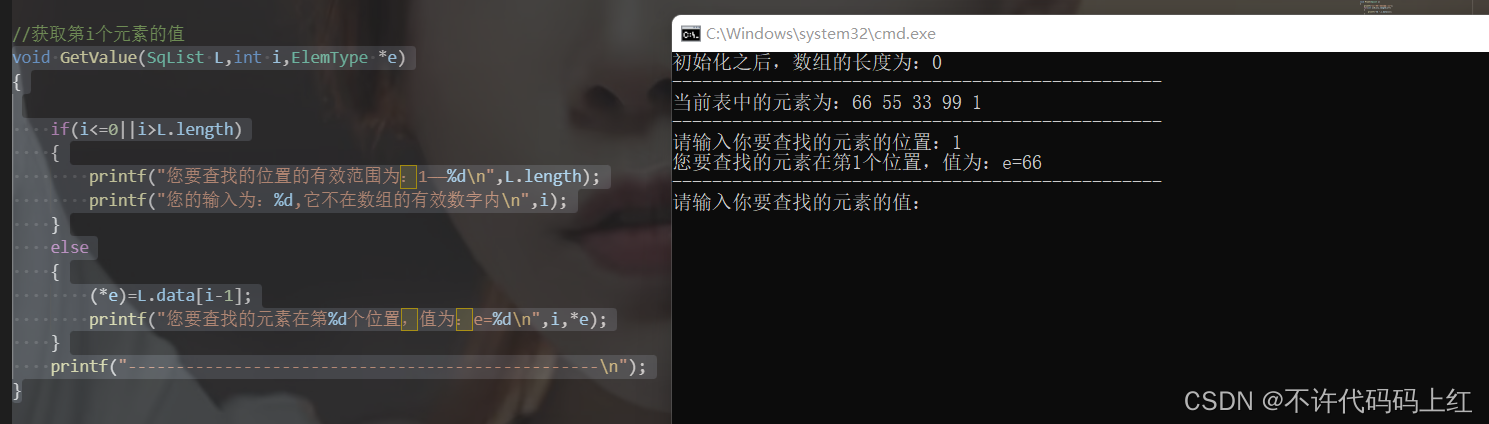
根据输入下标得到对应值
void GetValue(SqList L,int i,ElemType *e)
{
if(i<=0||i>L.length)
{
printf("您要查找的位置的有效范围为:1——%dn",L.length);
printf("您的输入为:%d,它不在数组的有效数字内n",i);
}
else
{
(*e)=L.data[i-1];
printf("您要查找的元素在第%d个位置,值为:e=%dn",i,*e);
}
printf("-------------------------------------------------n");
}
根据输入值得到其下标
int FindValue(SqList L,ElemType x)
{
int i=0;
while(i<L.length&&L.data[i]!=x)//循环遍历数组,如果不相等就循环找下一个
{
i++;
}
if(i>=L.length) //遍历完数组还是没有找到
{
return -1;
}
return i; //返回元素X所在的数组下标值
}

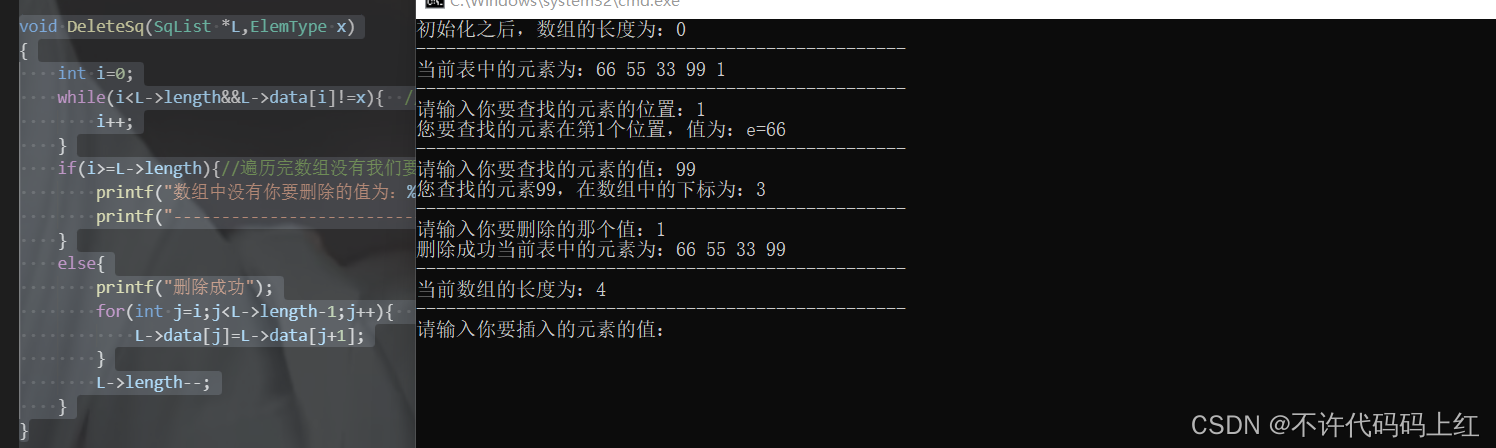
8、删除某一个元素
算法思想
用顺序表作为线性表的存储结构时,由于结点的物理顺序必须和结点的逻辑顺序保持一致,因此当需要删除第i个元素时,必须将原表中位置在i+1,i+2,…,n-1,n上的结点,依次向前移动一位。
void DeleteSq(SqList *L,ElemType x)
{
int i=0;
while(i<L->length&&L->data[i]!=x){ //从头开始遍历,如果没找到,在符合条件下一直循环
i++;
}
if(i>=L->length){//遍历完数组没有我们要删除的那个值
printf("数组中没有你要删除的值为:%d的元素n",x);
printf("-------------------------------------------------n");
}
else{
printf("删除成功");
for(int j=i;j<L->length-1;j++){ //把后一个值赋值到它的前一个元素所在的位置,所以到L->length-2即可。
L->data[j]=L->data[j+1];
}
L->length--;
}
}
9、线性顺序表的优缺点
优点
1、无须为表示结点间的逻辑关系而增加额外的存储空间。
2、可以方便地随机存取表中的任一元素。
缺点
1、插入或删除运算不方便,除了表尾的位置外,在表的其他位置上进行插入或删除操作都必须移动大量的结点。
2、由于顺序表要求占用连续的存储空间,存储分配只能预先进行静态分配。因此当表长变化比较大时,难以确定合适的存储规模。若按可能达到的最大长度预先分配表空间,则可能造成一部分空间的长期闲置而得不到充分利用;若事先对表长估计不足,则插入操作可能使表长超过预先分配的空间而造成溢出。
二、线性表的链式存储结构
1、线性表的链式存储概念
????????????链式存储结构,又叫链接存储结构。在计算机中用一组任意的存储单元存储线性表的数据元素(这组存储单元可以是连续的,也可以是不连续的).
????????????链式存储是最常用的动态存储方法。
????????????为了克服顺序表的缺点,可以采用链式方式存储线性表。
????从链接方式分:
单链表、循环链表、双链表
????从实现角度分:
动态链表、静态链表。
????特点:
1、比顺序存储结构的存储密度小(链式存储结构中每个结点都由数据域与指针域两部分组成,相比顺序存储结构增加了存储空间)。
2、逻辑上相邻的节点物理上不必相邻。
3、插入、删除灵活 (不必移动节点,只要改变节点中的指针)。
4、查找节点时链式存储要比顺序存储慢。
5、每个节点是由数据域和指针域组成。
6、由于簇是随机分配的,这也使数据删除后覆盖几率降低,恢复可能提高。
2、单链表
LinkList和Node*
特别强调一下:
LinkList与Node都是结构指针类型,这两种类型是等价的。通常习惯上用LinkList说明指针变量,强调它是某个单链表的头指针变量。
LinkList L :L为单链表的头指针
Node L :L为指向单链表中结点的指针变量
单链表概念
单链表:
单链表是一种链式存取的数据结构,用一组地址任意的存储单元存放线性表中的数据元素。链表中的数据是以结点来表示的,每个结点的构成:元素(数据元素的映象) + 指针(指示后继元素存储位置),元素就是存储数据的存储单元,指针就是连接每个结点的地址数据。
此线性表的每个结点只有一个next指针域。
结点:
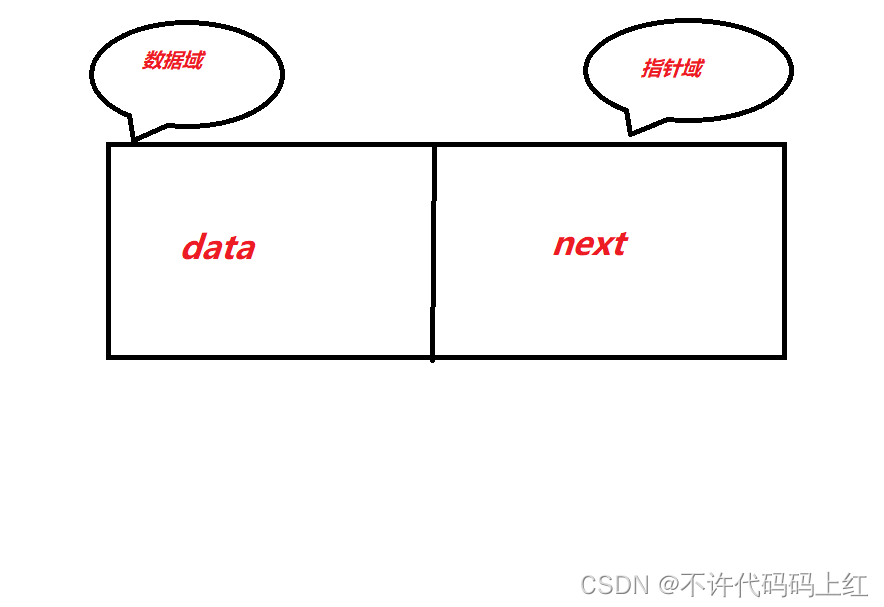
创建结构体
typedef struct Link {
int elem;
struct Link *next;
}link;
初始化单链表
建立单链表:
1、头插法建表
算法思想
从一个空表开始,每次读入数据,生成新结点,将读入的数据存放在新结点的数据域中,然后将新结点插入到当前链表的表头结点之后,直到读入结束标志为止
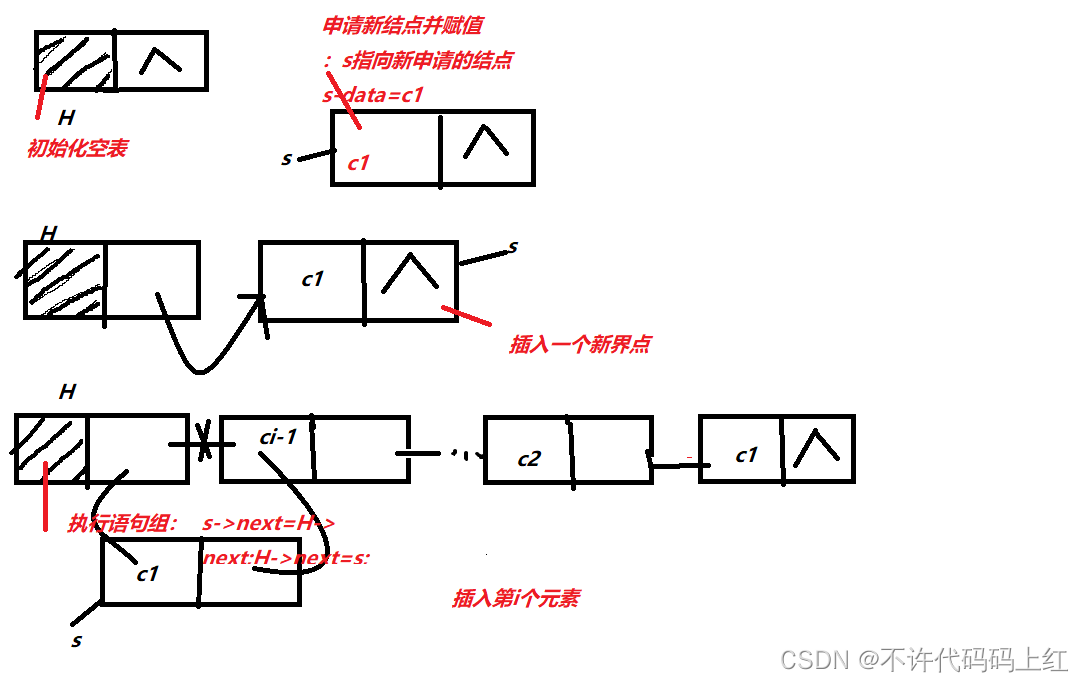
注意:采用头插法得到的单链表的逻辑顺序与输入元素顺序相反,亦称为头插法建表为逆序建表法。
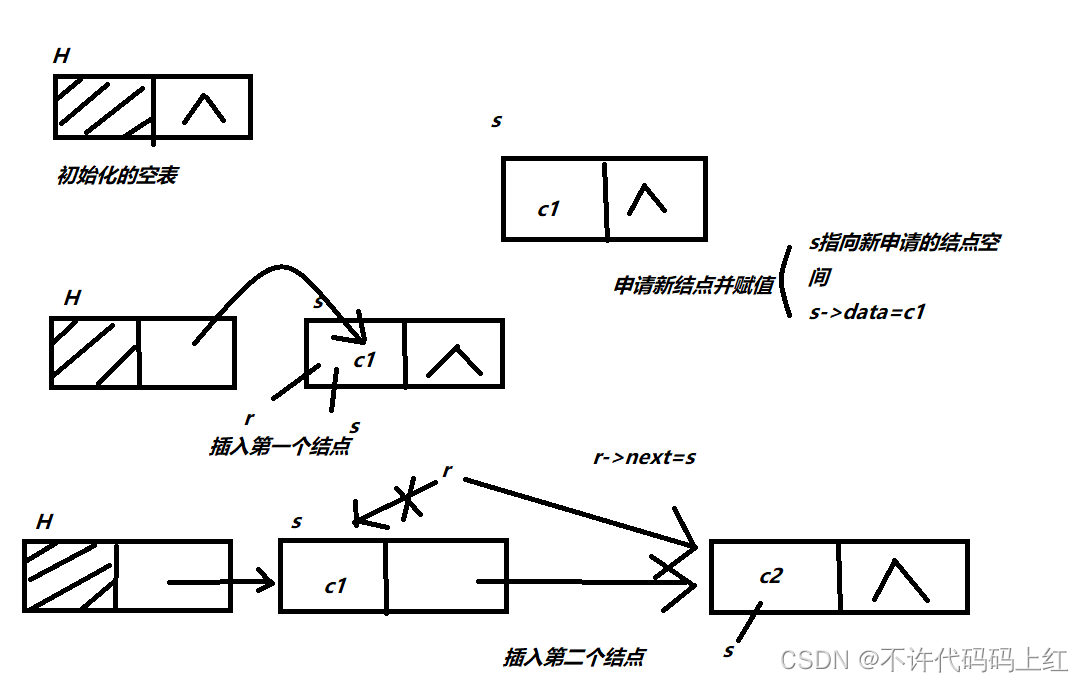
2、尾插法建表
算法思想:将新结点插到当前单链表的表尾上。为此需要增加一个尾指针r,使之指向当前单链表的表尾。
link * initLink() {
link * p = (link*)malloc(sizeof(link));//创建一个头结点
link * temp = p;//声明一个指针指向头结点,用于遍历链表
//生成链表
for (int i = 1; i < 5; i++) {
link *a = (link*)malloc(sizeof(link));
a->elem = i;
a->next = NULL;
temp->next = a;
temp = temp->next;
}
return p;
}

查找
1、按序号查询
算法思想
在单链表中,由于每个结点的存储位置都放在其前一个结点的next域中,所以即使知道被访问的结点序号i,也不能像顺序表那样直接按序号i访问一维数组中的相应元素,实现随机存取,而只能从链表的头指针出发,顺链域next逐个结点往下搜索,直到搜索到第i个结点为止。
2、按值查询
算法思想
按值查找是指在单链表中查找是否有值等于e的结点。查找过程从单链表的头指针指向的头结点出发,顺链逐个将结点值和给定值e比较,返回查找结果。
int selectElem(link * p, int elem) {
link * t = p;
int i = 1;
while (t->next) {
t = t->next;
if (t->elem == elem) {
return i;
}
i++;
}
return -1;
}

插入
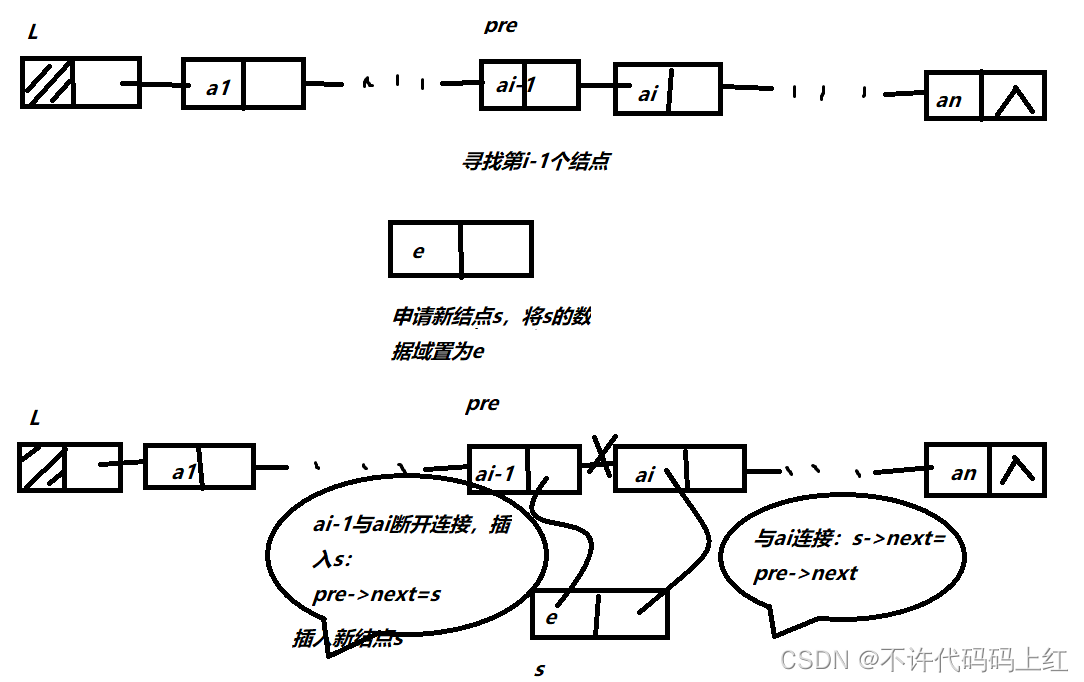
算法思想
1、查找,在单链表中找到第i-1个结点并由指针pre指示
2、申请,申请新结点s,将其数据域的值置为e
3、插入挂链,通过修改指针域将新结点s挂入单链表L
link * insertElem(link * p, int elem, int add) {
link * temp = p;//创建临时结点temp
//首先找到要插入位置的上一个结点
for (int i = 1; i < add; i++) {
temp = temp->next;
if (temp == NULL) {
printf("插入位置无效n");
return p;
}
}
//创建插入结点c
link * c = (link*)malloc(sizeof(link));
c->elem = elem;
//向链表中插入结点
c->next = temp->next;
temp->next = c;
return p;
}

删除
算法思想
1、查找,找到要删除的结点的上一个结点
2、删除第i个结点并释放空间
link * delElem(link * p, int add) {
link * temp = p;
//遍历到被删除结点的上一个结点
for (int i = 1; i < add; i++) {
temp = temp->next;
if (temp->next == NULL) {
printf("没有该结点n");
return p;
}
}
link * del = temp->next;//单独设置一个指针指向被删除结点,以防丢失
temp->next = temp->next->next;//删除某个结点的方法就是更改前一个结点的指针域
free(del);//手动释放该结点,防止内存泄漏
return p;
}

有序合并
#include<stdio.h>
#include<stdlib.h>
#define MAX 100
typedef struct Node{
int data;
struct Node* next;
}SLNode;
SLNode* head_create(){//创建头结点
SLNode* head = (SLNode*)malloc(sizeof(SLNode));
if(head==NULL) exit(1);
head->next=NULL;
return head;
}
SLNode* Node_insert(SLNode *head,int i,int x)//把x插入i位置 ,从头结点开始遍历
{
SLNode *p;p=head;//p指向头结点
int m=0;
while(m<i-1)//遍历到i-1位
{
p=p->next;
m++;
}
SLNode *q = (SLNode*)malloc(sizeof(SLNode));
q->next=p->next;
p->next=q;
q->data=x;
}
void print_SL(SLNode *head)//打印链表
{
SLNode *p;p=head;
if(p==NULL) printf("单链表空!n");
else{
printf("head");
p=p->next;
}
while(p!=NULL)
{
printf("->%d",p->data);
p=p->next;
}
printf("n");
}
SLNode* destroy(SLNode *head)//摧毁链表
{
SLNode *p,*q;
p=head->next;
head->next=NULL;
q=NULL;
while(q!=NULL)
{
q=p;
p=p->next;
free(q);
q=NULL;
}
printf("sucess!");
}
SLNode* merge(SLNode *head1,SLNode *head2,SLNode *head3)
{
SLNode *p1,*p2,*p3;
p1=head1->next,p2=head2->next;p3=head3;
while(p1!=NULL&&p2!=NULL)
{
if(p1->data<=p2->data)
{
p3->next=p1;
p3=p3->next;
p1=p1->next;
}
if(p1->data > p2->data)
{
p3->next=p2;
p3=p3->next;
p2=p2->next;
}
if(p1!=NULL) p3->next=p1;
if(p2!=NULL) p3->next=p2;
}
}
main()
{
SLNode *SL1=head_create();
for(int i=1;i<10;i++)
{
Node_insert(SL1,i,i*i);//把i^2插入i的位置
}
printf("单链表1为:n");
print_SL(SL1);
SLNode *SL2=head_create();
for(int i=1;i<10;i++)
{
Node_insert(SL2,i,i*6);//把i^2插入i的位置
}
printf("单链表2为:n");
print_SL(SL2);
//合并单链表,将表二插到表3中
SLNode *SL3=head_create();
printf("n合并两个单链表为:n");
merge(SL1,SL2,SL3) ;
print_SL(SL3);
//摧毁链表
destroy(SL1);
destroy(SL2);
destroy(SL3);
return 0;
}
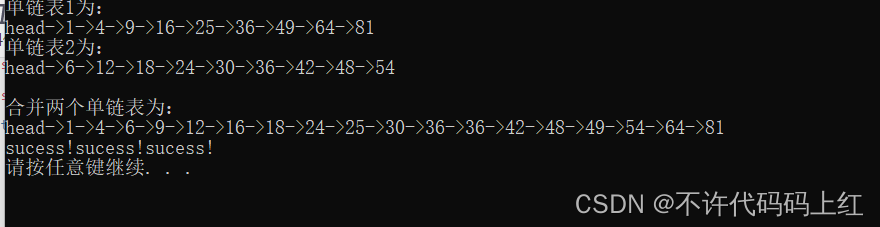
3、循环单链表
循环链表概念
循环链表是另一种形式的链式存储结构。它的特点是表中最后一个结点的指针域指向头结点,整个链表形成一个环。
????分类
(1)单循环链表:在单链表中,将终端结点的指针域NULL改为指向表头结点或开始结点即可
(2)多重链的循环链表:将表中结点链在多个环上
????判断空链表的条件是
head == head->next; rear ==rear->next;
????尾指针
用尾指针rear表示的单循环链表对开始结点a1和终端结点an查找时间都是O(1)。而表的操作常常是在表的首尾位置上进行,因此,实用中多采用尾指针表示单循环链表。带尾指针的单循环链表。
注意:判断空链表的条件为rear==rear->next;
建立循环单链表
void CreatCLLinkList(CLLinkList CL)
{
Node *rear,*s;
rear=CL;//rear指针动态指向当前表尾,其初始值指向头结点
int flag=1;
int x;
printf("Please input data and enter 0 end:n");
while(flag)
{
scanf("%d",&x);
if(x!=0)
{
s=(Node *)malloc(len);
s->data=x;
rear->next=s;
rear=s;
}
else
{
flag=0;
rear->next=CL;//最后一个节点的next域指向头结点
}
}
}
插入
#include<stdio.h>
#include<stdlib.h>
#define len sizeof(Node)
typedef struct Node
{
int data;
struct Node *next;
}Node,*CLLinkList;
void InitCLLinkList(CLLinkList *CL)
{
*CL=(CLLinkList)malloc(len);
(*CL)->next=*CL;
}
void CreatCLLinkList(CLLinkList CL)
{
Node *rear,*s;
rear=CL;//rear指针动态指向当前表尾,其初始值指向头结点
int flag=1;
int x;
printf("Please input data and enter 0 end:n");
while(flag)
{
scanf("%d",&x);
if(x!=0)
{
s=(Node *)malloc(len);
s->data=x;
rear->next=s;
rear=s;
}
else
{
flag=0;
rear->next=CL;//最后一个节点的next域指向头结点
}
}
}
void PrintCLLinkList(CLLinkList CL)
{
Node *p;
p=CL->next;
printf("You input data is:n");
for(;p!=CL;p=p->next)
{
printf("%-3d",p->data);
}
printf("n");
}
void InCLLinkList(CLLinkList CL,int i,int x)
{
Node *p,*s;
int k=0;
p=CL;
if(i<=0)
{
printf("You enter location illegal:n");
return;
}
while(p->next!=CL&&k<i-1)
{
k++;
p=p->next;
}
if(p==CL)
{
printf("The insert position is not reasonable:n");
return;
}
s=(Node *)malloc(len);
s->data=x;
s->next=p->next;
p->next=s;
printf("Insert successfullyn");
}
void Print_CLLinkList(CLLinkList CL)
{
Node *p;
p=CL->next;
printf("Now you input data is:n");
for(;p!=CL;p=p->next)
printf("%-3d",p->data);
}
int main()
{
int i,x;
CLLinkList CL;
InitCLLinkList(&CL);
CreatCLLinkList(CL);
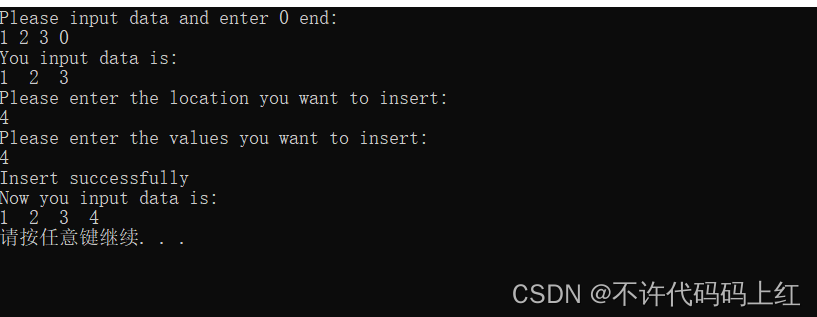
PrintCLLinkList(CL);
printf("Please enter the location you want to insert:n");
scanf("%d",&i);
printf("Please enter the values you want to insert:n") ;
scanf("%d",&x);
InCLLinkList(CL,i,x);
Print_CLLinkList(CL);
free(CL);
return 0;
}
删除
#include<stdio.h>
#include<stdlib.h>
#define len sizeof(Node)
typedef struct Node
{
int data;
struct Node *next;
}Node,*LinkList;
void InitCLLinkList(LinkList *CL)
{
*CL=(LinkList)malloc(len);
(*CL)->next=*CL;
}
void CreatCLLinkList(LinkList CL)
{
int flag=1,x;
Node *rear,*s;
rear=CL;
printf("Please input data and enter 0 end:n");
while(flag)
{
scanf("%d",&x);
if(x!=0)
{
s=(Node *)malloc(len);
s->data=x;
rear->next=s;
rear=s;
}
else
{
rear->next=CL;
flag=0;
}
}
}
void DeleCLLinkList(LinkList CL,int i)
{
Node *p,*r;
p=CL;
int k=0;
if(i<0)
{
printf("You enput i illegal!n");
return;
}
while(p->next!=CL&&k<i-1)
{
p=p->next;
k++;
}
if(p->next==CL)
{
printf("Delete Node i illegal!n");
return;
}
r=p->next;
p->next=r->next;
free(r);
}
void PrintCLLinkList(LinkList CL)
{
Node *p;
for(p=CL->next;p!=CL;p=p->next)
{
printf("%3d",p->data);
}
}
int main()
{
LinkList CL;
int i;
InitCLLinkList(&CL);
CreatCLLinkList(CL);
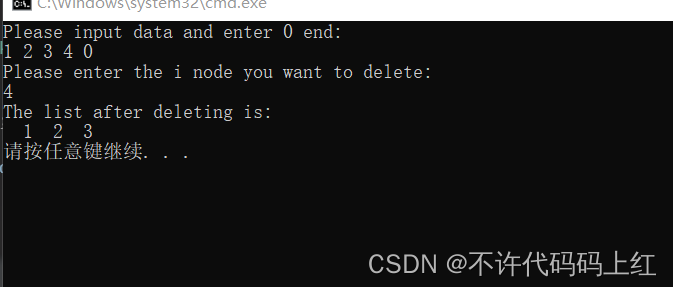
printf("Please enter the i node you want to delete:n");
scanf("%d",&i);
DeleCLLinkList(CL,i);
printf("The list after deleting is:n");
PrintCLLinkList(CL);
free(CL);
return 0;
}
合并
//头指针合并循环链表
#include<stdio.h>
#include<stdlib.h>
#define len sizeof(Node)
typedef struct Node
{
int data;
struct Node *next;
}Node,*CLLinkList;
void InitCL_aLinkList(CLLinkList *CL_a)
{
*CL_a=(CLLinkList)malloc(len);
(*CL_a)->next=*CL_a;
}
void InitCL_bLinkList(CLLinkList *CL_b)
{
*CL_b=(CLLinkList)malloc(len);
(*CL_b)->next=*CL_b;
}
void CreatCL_aLinkList(CLLinkList CL_a)
{
Node *p,*s;
int x,flag=1;
p=CL_a;
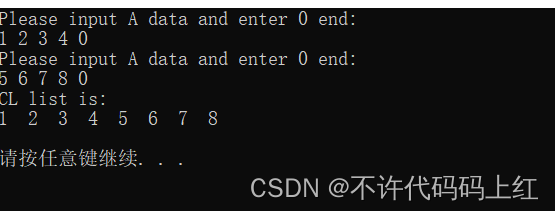
printf("Please input A data and enter 0 end:n");
while(flag)
{
scanf("%d",&x);
if(x!=0)
{
s=(Node *)malloc(len);
s->data=x;
p->next=s;
p=s;
}
else
{
p->next=CL_a;
flag=0;
}
}
}
void CreatCL_bLinkList(CLLinkList CL_b)
{
Node *p,*s;
int x,flag=1;
p=CL_b;
printf("Please input B data and enter 0 end:n");
while(flag)
{
scanf("%d",&x);
if(x!=0)
{
s=(Node *)malloc(len);
s->data=x;
p->next=s;
p=s;
}
else
{
p->next=CL_b;
flag=0;
}
}
}
CLLinkList MergeCLLinkList(CLLinkList CL_a,CLLinkList CL_b)
{
Node *p,*q;
p=CL_a;
q=CL_b;
while(p->next!=CL_a)//找到LA的表尾,用p指向它
p=p->next;
while(q->next!=CL_b)//找到LB的表尾,用q指向它
q=q->next;
q->next=CL_a;//修改LB的表尾指针,使之指向表LA的头结点
p->next=CL_b->next; //修改LA的表尾指针,CL_b->next的意思是跳过CL_b头结点
free(CL_b);
return CL_a;
}
void PrintCLLinkList(CLLinkList CL)
{
printf("CL list is:n");
for(Node *p=CL->next;p!=CL;p=p->next)
printf("%-3d",p->data);
printf("n");
}
int main()
{
CLLinkList CL_a,CL_b,CL;
InitCL_aLinkList(&CL_a);
InitCL_bLinkList(&CL_b);
CreatCL_aLinkList(CL_a);
CreatCL_aLinkList(CL_b);
CL=MergeCLLinkList(CL_a,CL_b);
PrintCLLinkList(CL_a);
free(CL_a);
return 0;
}
计算长度
#include<stdio.h>
#define len sizeof(Node)
#include<stdlib.h>
typedef struct Node
{
int data;
struct Node* next;
}Node,*LinkList;
void InitCLLinkList(LinkList *CL)
{
*CL=(LinkList)malloc(len);
(*CL)->next=*CL;
}
//尾插法创建循环链表
void CreatCLLinkList(LinkList CL)
{
Node *s,*rear;
int flag=1;
rear=CL;
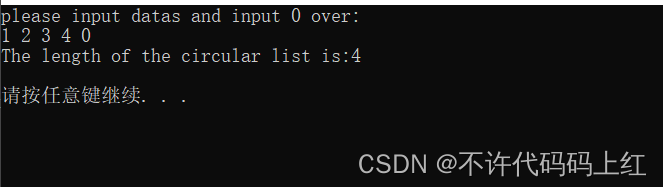
printf("please input datas and input 0 over:n");
int x;
while(flag)
{
scanf("%d",&x);
if(x!=0)
{
s=(Node *)malloc(len);
s->data=x;
rear->next=s;
rear=s;
}
else
{
flag=0;
rear->next=CL;
}
}
}
int LengthCLLinkList(LinkList CL)
{
int i=0;
Node *p;
p=CL->next;
while(p!=CL)
{
i++;
p=p->next;
}
return i;
}
int main()
{
LinkList CL;
int length;
InitCLLinkList(&CL);
CreatCLLinkList(CL);
length=LengthCLLinkList(CL);
printf("The length of the circular list is:%dn",length);
free(CL) ;
return 0;
}
4、双向链表
双向链表概念
双向链表也叫双链表,是链表的一种,它的每个数据结点中都有两个指针,分别指向直接后继和直接前驱。所以,从双向链表中的任意一个结点开始,都可以很方便地访问它的前驱结点和后继结点。一般我们都构造双向循环链表。
创建结构体
typedef struct line{
struct line * prior;
int data;
struct line * next;
}line;
初始化
line* initLine(line * head){
head=(line*)malloc(sizeof(line));
head->prior=NULL;
head->next=NULL;
head->data=1;
line * list=head;
for (int i=2; i<=3; i++) {
line * body=(line*)malloc(sizeof(line));
body->prior=NULL;
body->next=NULL;
body->data=i;
list->next=body;
body->prior=list;
list=list->next;
}
return head;
}
效果:

插入
line * insertLine(line * head,int data,int add){
//新建数据域为data的结点
line * temp=(line*)malloc(sizeof(line));
temp->data=data;
temp->prior=NULL;
temp->next=NULL;
//插入到链表头,要特殊考虑
if (add==1) {
temp->next=head;
head->prior=temp;
head=temp;
}else{
line * body=head;
//找到要插入位置的前一个结点
for (int i=1; i<add-1; i++) {
body=body->next;
}
//判断条件为真,说明插入位置为链表尾
if (body->next==NULL) {
body->next=temp;
temp->prior=body;
}else{
body->next->prior=temp;
temp->next=body->next;
body->next=temp;
temp->prior=body;
}
}
return head;
}

删除
line * delLine(line * head,int data){
line * temp=head;
//遍历链表
while (temp) {
//判断当前结点中数据域和data是否相等,若相等,摘除该结点
if (temp->data==data) {
temp->prior->next=temp->next;
temp->next->prior=temp->prior;
free(temp);
return head;
}
temp=temp->next;
}
printf("链表中无该数据元素");
return head;
}

5、静态链表
静态链表概念
用数组描述的链表,即称为静态链表。 在C语言中,静态链表的表现形式即为结构体数组,结构体变量包括数据域data和游标CUR。
静态链表的创建
#include <stdio.h>
#define maxSize 6
typedef struct {
int data;
int cur;
}component;
//将结构体数组中所有分量链接到备用链表中
void reserveArr(component *array);
//初始化静态链表
int initArr(component *array);
//输出函数
void displayArr(component * array, int body);
//从备用链表上摘下空闲节点的函数
int mallocArr(component * array);
int main() {
component array[maxSize];
int body = initArr(array);
printf("静态链表为:n");
displayArr(array, body);
return 0;
}
//创建备用链表
void reserveArr(component *array) {
int i = 0;
for (i = 0; i < maxSize; i++) {
array[i].cur = i + 1;//将每个数组分量链接到一起
array[i].data = 0;
}
array[maxSize - 1].cur = 0;//链表最后一个结点的游标值为0
}
//提取分配空间
int mallocArr(component * array) {
//若备用链表非空,则返回分配的结点下标,否则返回 0(当分配最后一个结点时,该结点的游标值为 0)
int i = array[0].cur;
if (array[0].cur) {
array[0].cur = array[i].cur;
}
return i;
}
//初始化静态链表
int initArr(component *array) {
int tempBody = 0, body = 0;
int i = 0;
reserveArr(array);
body = mallocArr(array);
//建立首元结点
array[body].data = 1;
array[body].cur = 0;
//声明一个变量,把它当指针使,指向链表的最后的一个结点,当前和首元结点重合
tempBody = body;
for (i = 1; i < 6; i++) {
int j = mallocArr(array); //从备用链表中拿出空闲的分量
array[j].data = i; //初始化新得到的空间结点
array[tempBody].cur = j; //将新得到的结点链接到数据链表的尾部
tempBody = j; //将指向链表最后一个结点的指针后移
}
array[tempBody].cur = 0;//新的链表最后一个结点的指针设置为0
return body;
}
void displayArr(component * array, int body) {
int tempBody = body;//tempBody准备做遍历使用
while (array[tempBody].cur) {
printf("%d,%dn", array[tempBody].data, array[tempBody].cur);
tempBody = array[tempBody].cur;
}
printf("%d,%dn", array[tempBody].data, array[tempBody].cur);
}

特点
这种存储结构,仍需要预先分配一个较大的空间,但在作为线性表的插入和删除操作时不需移动元素,仅需修改指针,故仍具有链式存储结构的主要优点。
假如有如上的静态链表S中存储着线性表(a,b,c,d,f,g,h,i),Maxsize=11,要在第四个元素后插入元素e,方法是:先在当前表尾加入一个元素e,即:S[9].data
= e;然后修改第四个元素的游标域,将e插入到链表中,即:S[9].cursor = S[4].cursor; S[4].cursor = 9;,接着,若要删除第7个元素h,则先顺着游标链通过计数找到第7个元素存储位置6,删除的具体做法是令S[6].cursor =
S[7].cursor。
三、顺序表与链表的比较
1、空间上
????顺序表:顺序表的的存储空间是静态分配的,在程序执行之间必须明确规定它的存储规模。
????静态链表:在静态链表中,初始存储池虽然也是静态分配的,但若同时存在若干个结点类型相同的链表,则它们可以共享空间,使个链表之间相互调节余缺,减少溢出的机会。
????动态链表:动态链表的存储空间是动态分配的,只要内存空间尚有空余,就不会产生溢出。
存储密度:指的是结点数据本身所占据的存储量和整个结点结构所占的存储量之比。
????存储密度越大,存储空间的利用率就越高。
????顺序表的存储密度为1,链表的存储密度小于1。
2、时间上
顺序表:顺序表是由向量实现的,它是一种随机的存储结构,对表中任一结点都可以在O(1)时间内直接地存取。而链表中的结点则需要从头指针起顺着链查找才能取得。
链表:在链表中的任何位置上进行插入或删除,都只需要修改指针。
3、语言上
在没有提供指针类型的高级语言环境中,若要采取链表结构,可以使用游标来实现静态链表。
在有指针类型的高级语言环境中,当线性表的长度不变,仅改变结点之间的相对关系时,静态链表比动态链表更方便。
4、链式存储方式比较
| 链表名称操作名称 | 找链表中首元素结点 | 找表尾结点 | 找p结点前驱结点 |
|---|---|---|---|
| 带头结点单链表L | L->next;时间耗费O(1) | 一重循环;时间耗费O(n) | 顺p结点的next域无法找到p结点的前驱 |
| 带头结点循环单链表L | L->next;时间耗费O(1) | 一重循环;时间耗费O(n) | 顺p结点的next域可以找到p结点的前驱;时间耗费O(n) |
| 带尾指针的循环单链表L | L->next->next;时间耗费O(1) | L;时间耗费O(1) | 顺p结点的next域可以找到p结点的前驱;时间耗费O(n) |
| 带头结点双向循环链表L | L->next;时间耗费O(1) | L->prior;时间耗费O(1) | p->prior;时间耗费O(1) |
最后
以上就是迅速耳机最近收集整理的关于C语言:指针三(线性表的存储结构)的全部内容,更多相关C语言:指针三(线性表内容请搜索靠谱客的其他文章。








发表评论 取消回复