哈佛大学单细胞课程|笔记汇总 (六)
哈佛大学单细胞课程|笔记汇总 (五)
(七)Single-cell RNA-seq clustering analysis—— graph-based cluster
识别重要的PCs (主成分)
确定PC及细胞聚类的PC数量对于细胞分类至关重要。
一种方法是Seurat自带的热图可视化,利用heatmap(获取pheatmap聚类后和标准化后的结果)以PCA分数排序的基因和细胞可视化选定PC的最变异基因。观察不同PC的重要性,查看基因差异是否明显,确定驱动PC的基因对于区分不同细胞类型是否有意义。
其中cells参数指定带有绘图所用最正或最负PCA分数的细胞数,目的是找到热图开始区分不明显的PC数。
# Explore heatmap of PCs
DimHeatmap(seurat_integrated,
dims = 1:9,
cells = 500,
balanced = TRUE)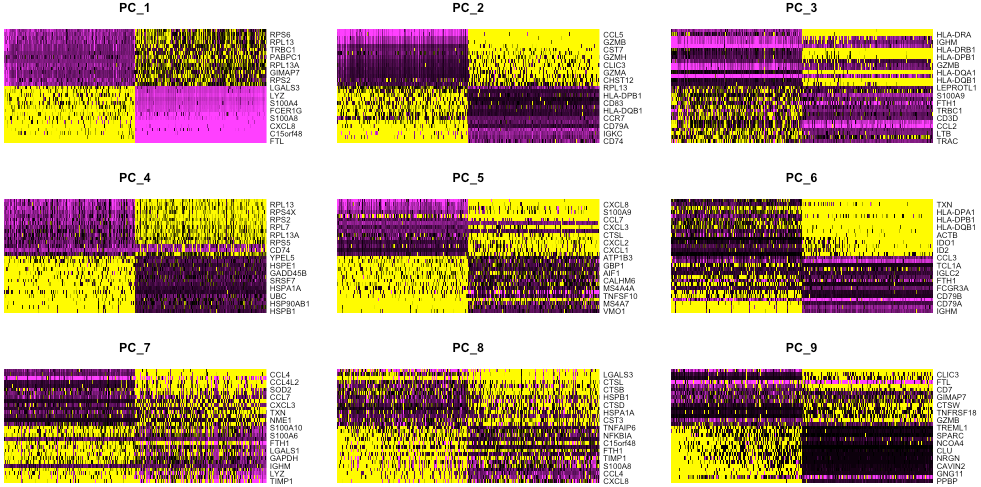
也可以查看对各个PC贡献最多的基因:
# Printing out the most variable genes driving PCs
print(x = seurat_integrated[["pca"]],
dims = 1:10,
nfeatures = 5)
滚石图(elbow plot,类似于胳膊肘)是另外一种确定PC个数的方法。
滚石图显示了每个PC贡献的标准差,我们的目标是寻找标准差开始趋于平稳的拐点。本质上,elbow出现的点之后的PC贡献整体就减少了。但是,此方法可能非常主观。
我们用前40个PCs绘制一份elbow plot:
# Plot the elbow plot
ElbowPlot(object = seurat_integrated,
ndims = 40)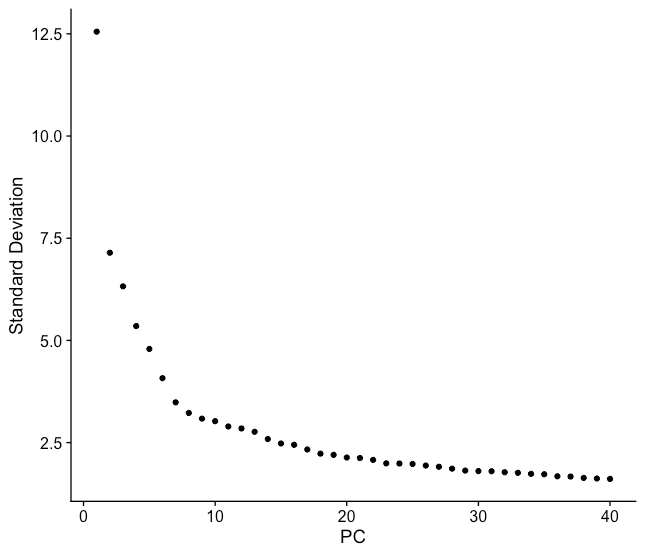
PC8-10时出现拐点,在PC30时基本与x轴平行。
尽管以上两种方法与来自Seurat的一起用于标准化和鉴定可变基因的旧方法使用更多,但它们也不再像以前那样重要了。因为相对来说SCTransform方法比旧方法更准确。
为什么PC选择对于较旧的方法更重要?
较旧的方法可能会将数据中存在的技术差异整合到一些高级PC中,因此PC的选择更为重要。而SCTransform可以更好地估计方差、移除技术差异,后续鉴定的PC中就不会包含这些技术变化的来源。
从理论上讲,使用SCTransform聚类时,选择的PC越多,解释的差异就越大,但是聚类所需的时间也会更长。因此在此分析中,我们使用top40 PCs进行聚类。
细胞聚类
Seurat使用基于图的方法进行聚类,该方法默认情况下使用K最近邻(K-nearest neighbor,KNN)图将细胞嵌入图结构中,并在具有相似基因表达模式的细胞之间绘制边缘。
我们将使用FindClusters()函数执行基于图的聚类。分辨率 (resolution)是设置下游聚类的重要参数,需要针对每个单独的实验进行优化。对于3,000-5,000个细胞的数据集,分辨率设置在0.4-1.4之间通常会产生良好的聚类。增加的分辨率值会导致更多的聚类,这对于较大的数据集通常是必需的。
FindClusters()函数允许我们输入一系列分辨率,并将计算聚类的“颗粒度”。
# Determine the K-nearest neighbor graph
seurat_integrated <- FindNeighbors(object = seurat_integrated,
dims = 1:40)
# Determine the clusters for various resolutions
seurat_integrated <- FindClusters(object = seurat_integrated,
resolution = c(0.4, 0.6, 0.8, 1.0, 1.4))如果我们查看Seurat对象中的metadata(seurat_integrated@metadata),其中包含有不同分辨率计算出的分群结果。
# Explore resolutions
seurat_integrated@meta.data %>%
View()我们通常情况下会一个中间范围的分辨率,比如0.6-0.8,这里使用Idents()函数来识别簇并将resolution设置为0.8。
# Assign identity of clusters
Idents(object = seurat_integrated) <- "integrated_snn_res.0.8"为了可视化不同的细胞亚群,最受欢迎的两种方法分别为t-distributed stochastic neighbor embedding (t-SNE)(https://kb.10xgenomics.com/hc/en-us/articles/217265066-What-is-t-Distributed-Stochastic-Neighbor-Embedding-t-SNE-) 和 Uniform Manifold Approximation and Projection (UMAP)(https://umap-learn.readthedocs.io/en/latest/index.html) 。两种方法的目的都是通过计算使得在高维空间中具有相似局部邻域的细胞在低维空间中也聚类到一起(Hemberg-lab单细胞转录组数据分析(十二)- Scater单细胞表达谱tSNE可视化)。这些方法都是基于PCA的结果,需要求输入用于分析的PC数,建议使用与上面FindClusters分析时相同的PC数。
## Calculation of UMAP
## DO NOT RUN (calculated in the last lesson)
# seurat_integrated <- RunUMAP(seurat_integrated,
# reduction = "pca",
# dims = 1:40)# Plot the UMAP
DimPlot(seurat_integrated,
reduction = "umap",
label = TRUE,
label.size = 6)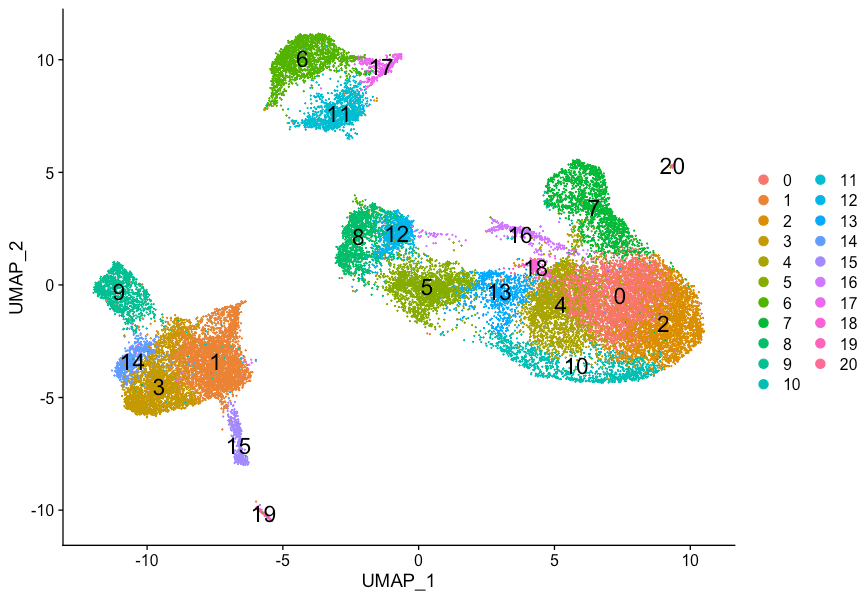
多尝试分辨率的设置也是有用的,这里当我们把resolution更换为0.4时,
# Assign identity of clusters
Idents(object = seurat_integrated) <- "integrated_snn_res.0.4"
# Plot the UMAP
DimPlot(seurat_integrated,
reduction = "umap",
label = TRUE,
label.size = 6)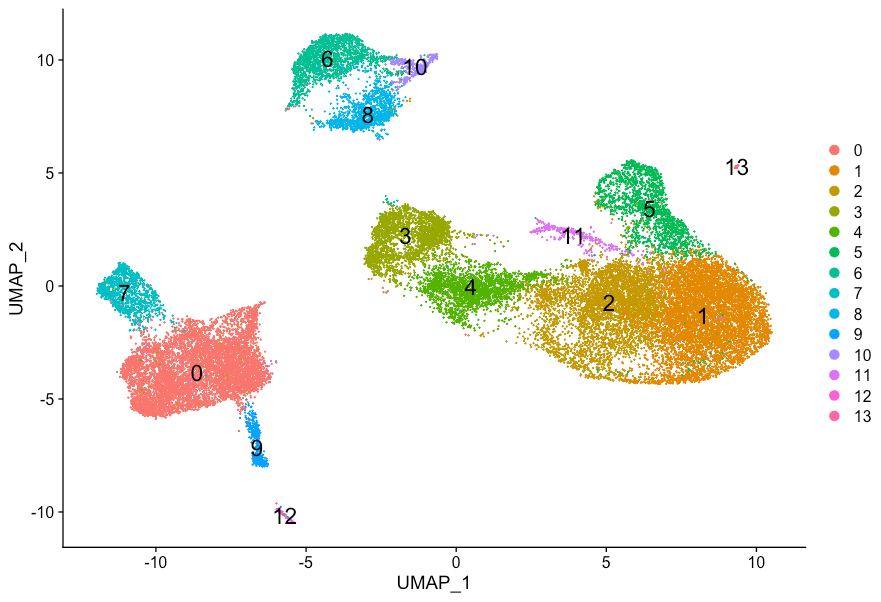
UMAP的结果是稳定的,但分群是有变化的。(之前是不是会有一个疑问在UMAP图中比较临近的细胞是怎么分开的呢?这是因为分群时用到的信息更多,会区分更明显;可视化投影时信息做了降维,只展示最主要的变化)
往期精品(点击图片直达文字对应教程)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|




























后台回复“生信宝典福利第一波”或点击阅读原文获取教程合集



最后
以上就是体贴大碗最近收集整理的关于哈佛大学单细胞课程|笔记汇总 (七)的全部内容,更多相关哈佛大学单细胞课程|笔记汇总内容请搜索靠谱客的其他文章。








发表评论 取消回复