UMAP算法被认为是与t-SNE相似的原理,都是将高维概率分布映射到低维空间的算法,从而做到降维的效果。主要基于流形理论和拓扑算法的理论,对高维数据进行降维,从而形成其他分类模型的输入特征。
那么,我们首先看下什么是流形理论呢。我们从一个叫做Swiss Roll的可视化模型进行解释,具体意义就是如何将在流形上两个点的距离进行最小化的表示。
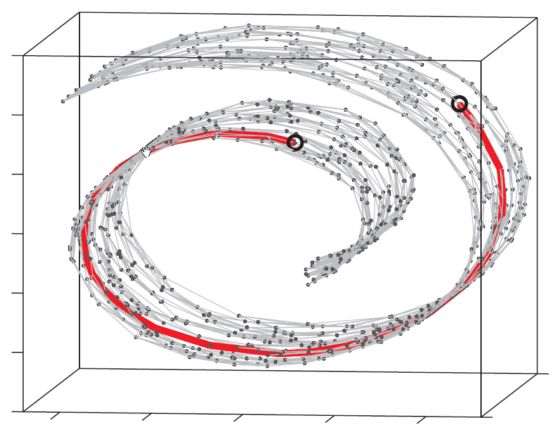
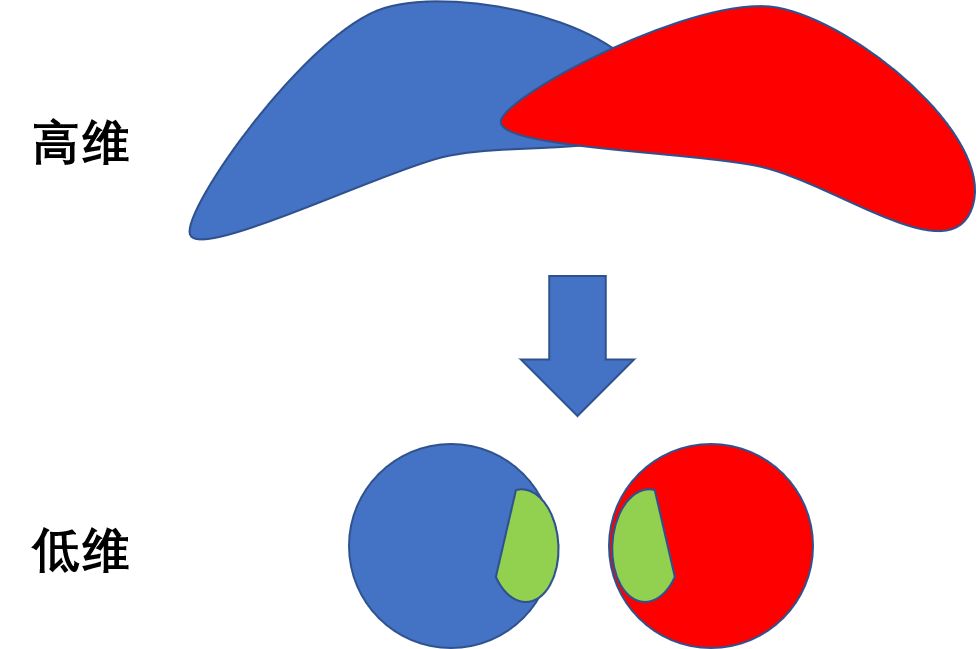
如图(来自网络)所示,其中两个黑色的圈之间的距离,可能直接连接的很近,如果上升到流形的理论,其连接距离就不再是直线连接,而是流形表结构上的距离。然后,我们再看下这个拓扑算法,通俗讲就是只考虑物体间的位置关系而不考虑它们的形状和大小。那么,怎么把这两者结合起来构成我们的UMAP呢,其实很简单,就是基于高维的流形结构特征,将其中各个点之间的位置关系进行确定,从而构造高维的数据分布结构。然后在使其降维到低维的分布结构,从而达到聚类以及特征提取的效果,可以用图来表示:
接下来我么看下在R语言是如何实现UMAP的
最后
以上就是踏实白云最近收集整理的关于umap算法_R语言实现UMAP降维模型的全部内容,更多相关umap算法_R语言实现UMAP降维模型内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复