摘要:本文整理自阿里云开源大数据高级开发工程师杨庆苇在7月17日阿里云数据湖技术专场交流会的分享。本篇内容主要分为两个部分:
- 数据湖元数据仓库介绍
- 阿里云DLF数据湖管理与优化
点击查看直播回放
数据湖元数据仓库介绍
数据湖的实践过程中,我们面临了诸多挑战:
第一,数据难以识别和查找。数据湖内存在大量未被有效识别的数据,可能是历史遗留或未被管理的数据,比如通过文件拷贝上传或其他工具引擎写入湖内的数据。其次,传统元数据服务里缺乏有效的检索服务,数据增长到一定规模时,很难从大量元数据中搜索和定位到特定场景下的数据。
第二,数据资产管理能力弱,湖上缺乏有效的数据资产分析和优化工具,难以精细化掌握库、表分区级别的数据明细。对 schema 维度存储分层方案落地困难,数据冷热难以辨别,无法在库、表分区维度实现分层。
第三,湖格式优化缺乏系统的解决方案。比如小文件合并操作需要用户对湖格式有一定的了解,能主动发现部分 schema 存在不合理的小文件,且利用计算引擎运行小文件合并任务,存在一定的使用门槛。此外,需要用户能够识别无效的历史数据以对其进行清理。
为了解决数据湖实践过程中遇到的挑战,综合湖上数据特点以及计算引擎特点,阿里云提出了基于元仓数据底座,以云原生资源池的海量计算能力为基础,结合管控的在线服务能力,为用户提供全托管的湖管理和优化的解决方案。
数据湖元数据仓库架构
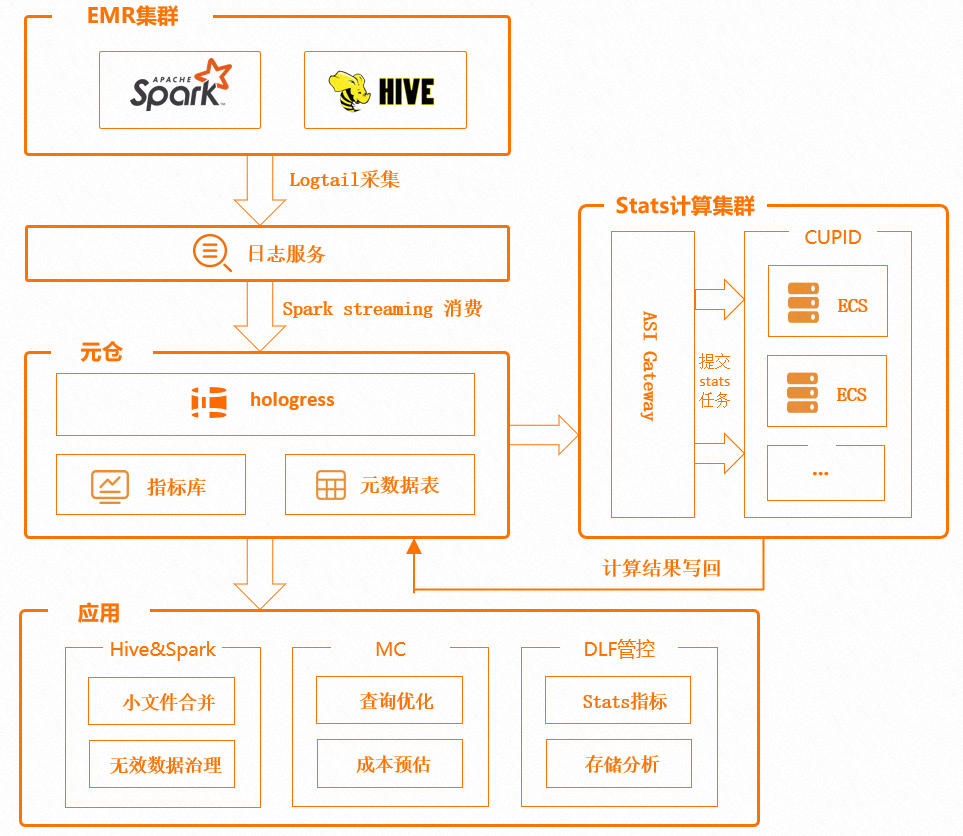
元仓组成湖上元数据以及分析和计算数据,为湖管理和优化提供了参考指标。经过数据采集、ETL、数据分析、计算等过程,将湖上分布在各处的数据进行整合,提取出有意义的指标,构建出分析库、指标库和索引库,为上层应用提供数据支撑。
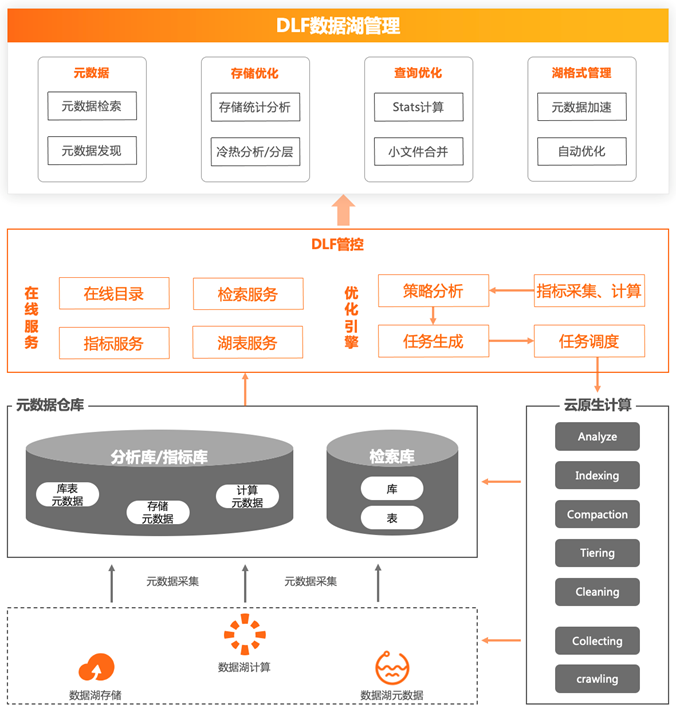
上图右侧是云原生计算池,通过 Spark 引擎利用云上的可伸缩资源运行 Analyze、Indexing、Compaction、Tiering 等分析和优化任务,并实时将计算结果写回元仓,参与指标库与索引库的建设,丰富和扩展元仓的指标资产,如在计算池内运行 stats 任务、获取表行数大小等指标,并回写到元仓指标库,用户可在第一时间查看表的基础信息,并以此为参考做数据质量分析等操作。
管控层提供用了在线服务能力,如在线目录、检索服务、指标服务等,优化引擎负责分析元仓上的指标,并依据规则生成优化任务提交给云原生计算池进行计算。在此之上延伸出了很多湖管理优化的能力:
①元数据能力:解决了数据难以识别和操作的问题。比如针对元数据检索,通过建立检索库,快速搜索元数据以及相关的 schema 明细。元数据发现通过云原生池计算运行任务提取元数据信息,有效识别湖内未知数据。
②存储优化能力:解决了数据资产管理能力弱的痛点。比如存储统计分析,通过元仓的指标库分析库、表分区级别的数据明细、冷热分层,通过指标库提供的表分区,最近访问时间、访问频率、冷热指标对表分区自动分层。
③查询优化能力:如小文件合并,通过指标库提取出小文件表和分区信息,根据规则在云原生资源池上运行小文件合并任务。此为全托管过程,用户侧无感知。
④湖格式管理优化:实现了元数据加速和自动优化。
以上方案解决了数据湖管理与优化的部分问题,帮助用户更好地使用和管理数据湖。
数据湖元数据仓库建设
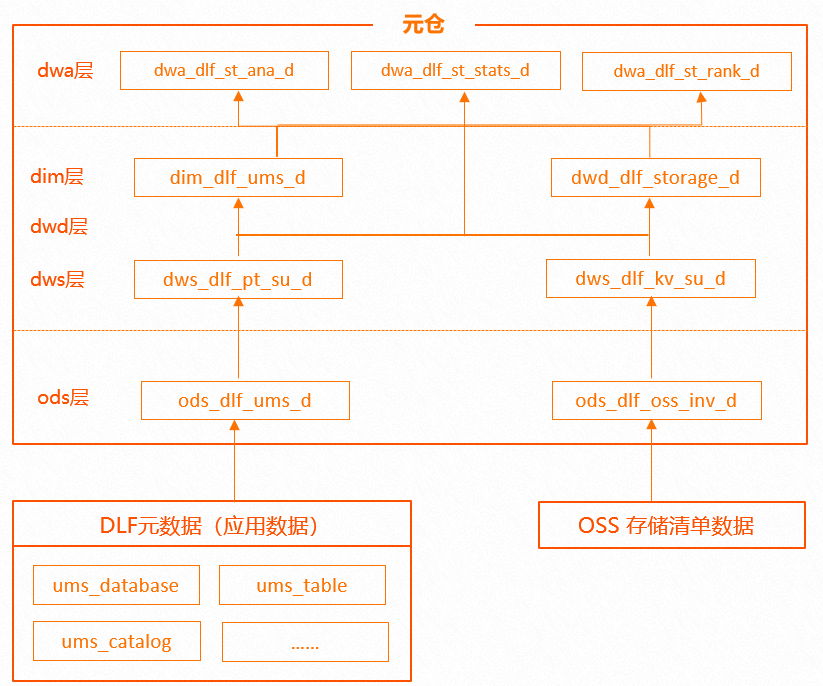
湖上元仓的原始数据由三类数据构成:
①存储数据:文件级别的OSS存储数据信息,包括大小、存储路径、存储类型、最近更新时间等,均来自存储访问日志和明细清单,这些基础数据构成存储属性的元数据,是分析和管理对象存储的基础。
②元数据:描述目录、库、表、分区、函数等的数据,包括索引、属性、存储以及 stats的统计数据。主要来自于引擎元数据服务存储以及 stats的计算扩充,是大表治理、小文件合并等优化操作的基础数据。
③引擎行为数据:包括血缘数据、引擎任务执行数据,比如文件大小、文件数、任务上下游依赖信息数据。这些数据在引擎计算时产生,是建设数据地图、生命周期管理的基础数据。
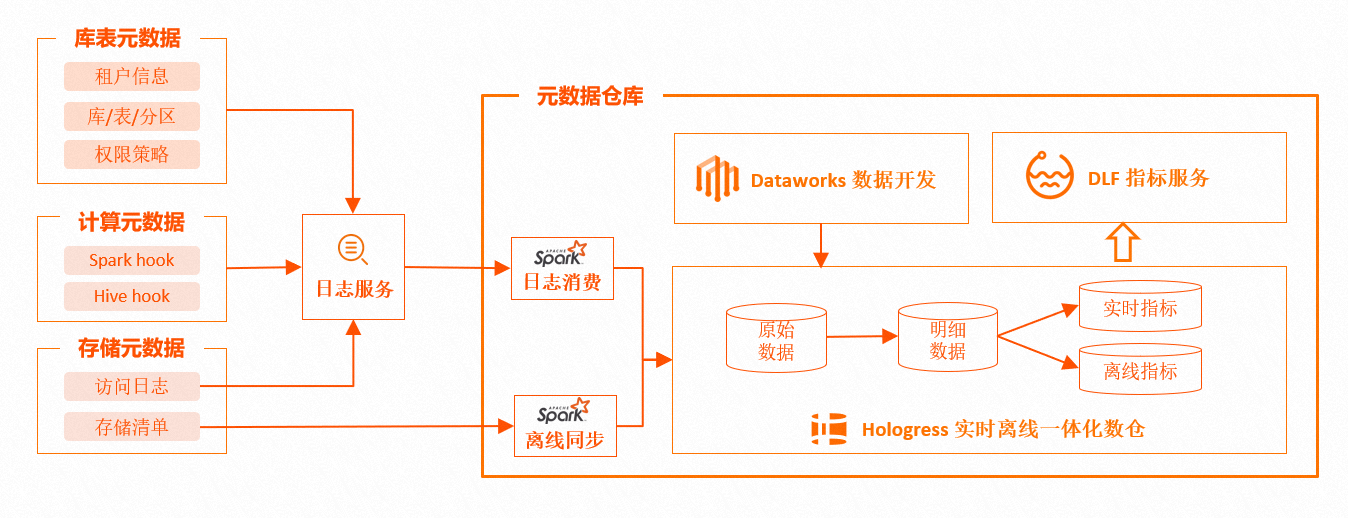
以上数据经过日志服务消费、Spark 批任务、离线同步、Spark Structured Streaming、流任务实时消费等方式集成到元仓,作为元仓的原始数据。元仓选择 Hologres 作为存储库,因为Hologres对于海量数据的实时写入、实时更新、实时分析能提供较好的支持。
对于实时性要求不高,但有较大数据量分析的场景,比如库表存储分析,可以通过 MaxCompute 离线数据加工的方式,将原始数据转换成明细数据,并提供离线指标给管控层;对于有较高实时性要求的场景,比如获取表分区行数、执行更新时间等,通过 Hologres 实时分析能力,实时计算出分析指标,并提供给 DLF 管控。
元仓包含了实时和离线场景,为数据湖管理和优化提供了稳定、高质量的数据基础。
阿里云DLF数据湖管理与优化
元数据检索
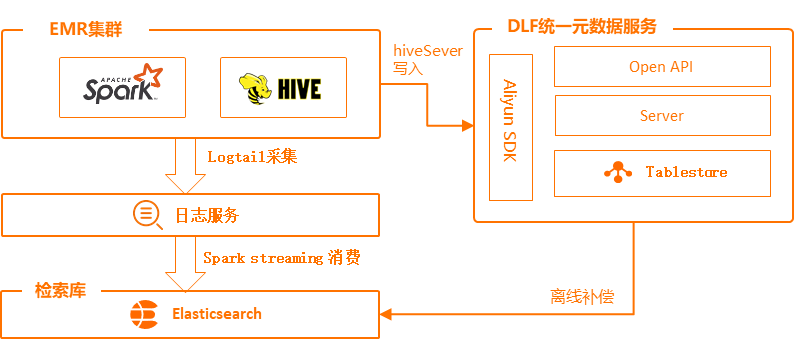
元数据检索解决了数据湖上数据难以查找的痛点。主要提供了两种搜索方式,一是全文检索,通过对元数据所有列属性建立索引,满足对任意单词的搜索都能在毫秒级别内做出响应;二是提供了多列精确查询,满足在特定条件场景下的搜索,比如按库名、表名、列名、Location地址、创建时间、最后修改时间等特殊属性精确匹配搜索。
索引库选择了阿里云Elasticsearch方案。 ES 是实时分布式的搜索与分析引擎,可以近乎准实时地存储、查询和分析超大数据集,非常适合元数据的实时搜索场景。为了达到搜索结果秒级延迟的效果,我们选用 Spark Streaming 流技术,实时同步和解析引擎生产的 DML 日志写入 ES 库
但消费日志存在着两个天然的问题:一是消息的顺序性,无法保证顺序产生的 DML 事件能被顺序地消费并写入 ES 库;二是消息的可靠性,日志服务无法保证集群日志能够百分百被捕捉并写入到 hub。
为了解决上述痛点,一方面会通过消息内的最近更新时间做判断,逻辑上保证了消息的顺序性;另一方面,通过每日的离线任务同步元数据库做索引补偿,保证了每日元数据信息的可靠性。通过流技术、离线补偿技术、ES检索能力,实现了湖内从大量元数据中快速搜索和定位的能力。
数据资产分析
分析维度:
湖上资产分析能力能够更高效、简洁地帮助用户分析和管理湖上资产,包含了资源统计、趋势变化、存储排名、存储分层。
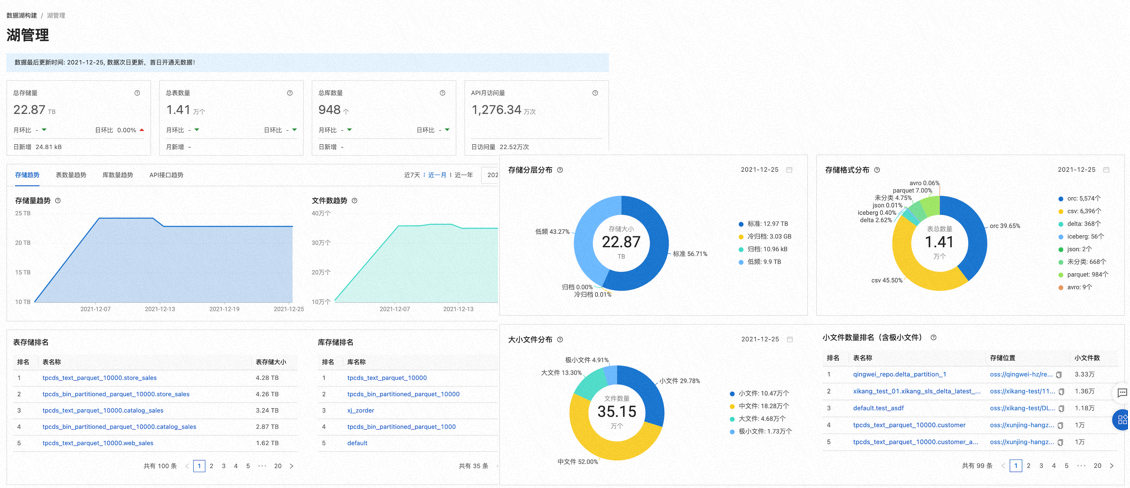
资源统计提供了总存储量、总库表数量、 API 访问信息总量,为用户提供了直观的数据感受,对湖上资产进行全局把握。
趋势变化反映了上述统计指标近 7 天、30天和 1 年的增减变化。通过数据波动能够发现业务的发展状态,比如判断某业务近期的发展态势,并根据态势调整资源投入。
存储排名反映了库表在一定范围内的排序情况,用户可以根据这一排名发现表的数据成本问题,比如 80% 的存储集中在 20% 表里。
存储分层描述了对象存储上存储类型的分布情况、存储格式分布情况以及大小文件分布情况。通过分布情况判断当前数据分层是否合理。
以上分析数据一方面能够帮助用户更好地理解和掌握湖上资产,另一方面为用户管理和优化湖数据提供了事实依据。
数据模型:
资产分析的模型建立遵循数仓的分层范式,从下至上分别为源数据层、数据公共层、数据应用层。 OSS存储的日志、明细数据、元数据和审计数据通过离线任务同步至元仓 ODS 层,然后通过离线加工计算出公共层数据,包括元数据、维表、文件存储、明细表、库表汇总等,然后根据业务需求将公共数据加入到应用数据并输出给管控,最后进行报表展示。
库表维度精细化分析-DataProfile
DataProfile 模块在库表元素之上,增加扩展了 stats 指标。stats 是引擎对于表的统计信息,包括表的记录数、表大小、文件数量等基础数据。在此基础上做了 stats 扩展,包括小文件数据、小文件占比、冷热度、分层信息指标等。由于数据湖对接多种引擎,Spark、 Hive 等。每种引擎 stats 计算结果都无法保证全面准确,且触发条件不一致,指标的覆盖度较低。默认情况下,如果分区表的记录数、大小文件指标覆盖度不足20%,则无法直接使用元数据 stats 指标。因此,我们通过主动提交 stats 分析任务,帮助用户计算表的 stats 数据。
首先,引擎做 DML 任务后会产生一个事件,元仓记录这一事件, stats 集群实时消费 DML 事件,并拉起对应的 stats 分析任务,同时扩展了 analyze 命令,支持小文件数量、数据分层占比等分析指标。整个 stats 集群运行在云原生资源池内,为避免元数据服务与业务库的冲突,任务运行完成后会实时写入指标库。
上述方案补充了云原生计算引擎 stats 数据覆盖准确度不高的问题,为表分析和优化提供了基础数据。Stats 能为管控页面提供库、表分区级别的明细数据,也能为其他优化引擎提供数据支持,比如分析表的小文件数量指标进行小文件合并,同时也能服务多种引擎做 CBO 优化。
生命周期管理
生命周期管理模块能够对 schema 维度存储分层,有效地帮助用户降低存储成本。 OSS 对象存储提供了文件级别的分层能力,OSS 不同存储类型价格不同,由热到冷分别为标准、低频、归档、冷归档,成本依次递减。基于此能力,可以将不常使用的数据冷冻,待使用时再解冻,以此降低存储成本。
基于 OSS 的分层能力,结合引擎元数据,提供库表分区粒度的生命周期管理能力,根据规则对表和分区进行冷冻或解冻,以此降低用户对数据湖内冷热分层的使用门槛。
规则中心通过元仓提供的指标制定,包括最近修改时间、创建时间、分区值、访问频率等指标,其中访问频率由分析引擎任务明细产生,通过 hook 的方式采集 Spark 或 Hive 执行任务时的任务明细,经过计算加工提取访问频率和最近访问的时间冷热信息。最近修改时间、创建时间分区值等基础指标由元仓计算而来。
决策中心定期触发规则判断,在满足规则的情况下会产生归档任务,由任务中心实行。整个任务中心通过分布式调度,定时或手动执行解冻或归档任务,利用 JindoSDK 的高并发、高稳定特性,执行目录级别的文件归档操作。
生命周期管理过程对于用户而言十分便捷,用户无需操作 OSS 文件,极大提高了用户对湖上数据的分层管理能力。
以上为阿里云数据湖团队在数据湖管理优化过程中的实践,在实际应用过程中,帮助客户优化存储成本的同时,提高了数据的使用效率。
更多信息:
产品官网
[1] 数据湖构建Data Lake Formation:数据湖构建 Data Lake Formation_数据仓库_数据实时分析-阿里云
[2] 开源大数据平台EMR: E-MapReduce_EMR_大数据框架_大数据-阿里云
[3] 大数据知识图谱: 大数据知识图谱
数据湖系列
[1] 数据湖揭秘—Delta Lake: 数据湖揭秘—Delta Lake-阿里云开发者社区
[2] 数据湖构建—如何构建湖上统一的数据权限: 数据湖构建—如何构建湖上统一的数据权限-阿里云开发者社区
[3] 关于 Data Lake 的概念、架构与应用场景介绍:关于 Data Lake 的概念、架构与应用场景介绍-阿里云开发者社区
[4] 数据湖架构及概念简介:
数据湖架构及概念简介-阿里云开发者社区
[5] 数据湖统一元数据和权限
数据湖统一元数据与权限-阿里云开发者社区
最后
以上就是追寻飞鸟最近收集整理的关于数据湖管理及优化的全部内容,更多相关数据湖管理及优化内容请搜索靠谱客的其他文章。








发表评论 取消回复