随着大数据时代的来临,如何帮助用户从大量信息中迅速获得对自己有用的信息成为众多商家的重要任务,个性化推荐系统应运而生。个性化推荐系统以海量数据挖掘为基础,引导用户发现自己的信息需求,现已广泛应用于很多领域。传统的个性化推荐系统,采用定期对数据进行分析的做法来更新模型。由于是定期更新,推荐模型无法保持实时性,对用户当前的行为推荐结果可能不会非常精准。实时个性化推荐实时分析用户产生的数据,可以更准确地为用户进行推荐,同时根据实时的推荐结果进行反馈,更好地改进推荐模型。
腾讯大数据平台部和北京大学网络所崔斌教授研究组从2014年起开展大数据实时推荐研究,双方合作的论文连续两年在国际顶级会议SIGMOD2015和2016发表:TencentRec: Real-time Stream Recommendation in Practice SIGMOD2015,Real-time Video Recommendation ExplorationSIGMOD2016 。研究工作侧重解决实际应用中存在的问题,针对大数据实时推荐在精准、实时、海量等方面的挑战,提出了分布式可扩展的实时增量更新推荐算法,使推荐效果得到了明显的提升。所研究的方法已应用在包括视频、新闻等多个业务中,推荐效果得到显著提升。实时推荐系统现每天处理千亿条用户行为,支撑百亿级用户请求。
1. 大数据实时计算平台
腾讯大数据实时计算平台TRC[1]由实时数据接入TDBank、实时数据处理TDProcess、和分布式K-V存储TDEngine等部分组成,其中TDBank主要负责从业务侧接入实时数据,如用户行为数据、物品信息数据等;TDProcess基于Storm对实时流入的数据进行计算,并利用TDEngine存储计算结果,以供推荐引擎等使用。
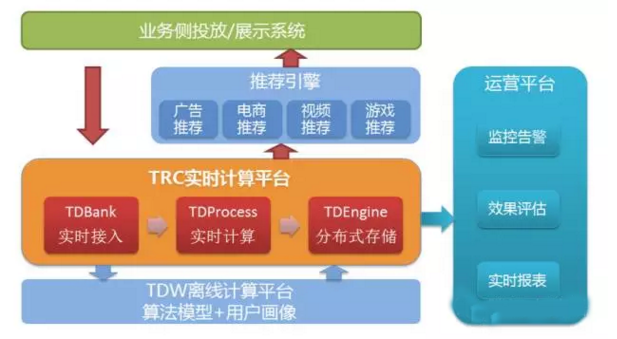
TRC的主要框架如上图所示,有关TRC的文章已经有很多,这里不作详述,有兴趣的读者可以参考文章[1]获得详细描述。
2. 推荐算法实时化
基于Storm的实时计算能够针对海量流式数据进行有效的统计处理,然而流式计算在机器学习算法方面有着天然的劣势,而要完成大数据实时推荐,只是实时统计显然是不够的,我们希望能实现推荐算法的实时化更新计算。
流式实时计算在机器学习方面的局限性主要表现在两方面:首先,由于数据是以流的形式进入Storm平台计算,在任何时刻,我们都只有目前流入的数据,而没有传统的全局数据概念,而在全局数据上进行迭代计算正是许多机器学习算法需要的;其次,Storm平台是计算数据易失的,在海量数据背景下,如何保证模型的有效存储及更新维护成为一个挑战。
对于上述第二点不足,我们使用了TDE作为解决方案,TDE作为一个高容错、高可用性的分布式K-V存储,很好的满足了我们对计算数据的存储需求。而对于第一点不足,我们通过精细的设计,将原始的离线计算转化为增量计算,并实现了几类经典算法:
CF算法:协同过滤算法,根据当前时间用户对物品的行为,实时更新物品间的共现数据和用户的兴趣分布数据,以计算物品间和用户间的相似度,进行基于物品或用户的协同推荐。
CB算法:通过分析用户的实时行为数据,更新计算用户和不同物品间的内容相似度,以对用户进行推荐。
Hot算法:通过接收所有用户的实时行为数据,实时更新物品的热度,分析得到当前的热点物品,如实时热点新闻等,以对用户进行实时的推荐。
MF算法:协同过滤矩阵分解算法,根据用户对物品的行为评分矩阵,将矩阵分解为用户和物品的特征向量,以预测用户对物品的喜好,来进行推荐。
实现框架
下图为基于Storm实现的框架图,系统可以分为五层,数据接入层,数据预处理层,算法处理层,商品信息补充层,和存储层。数据接入层负责接收数据,预处理层负责根据历史数据对数据进行补全或者过滤等。算法处理层,是系统的主体部分,负责对数据进行分析处理,实现相关推荐算法的计算,将算法结果传入下一层。商品信息补充层负责对算法结果进行商品信息补全,这里补全是为了后续与离线模型结合或向用户推荐时,进一步对推荐结果做筛选的。最后一层是存储层,负责将结果存入存储部分,以供使用。
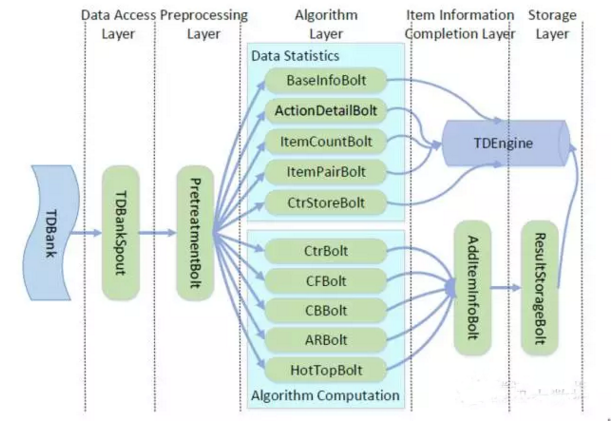
数据接入层
数据接入层负责接入数据,并且做简单的检查,对应TdbankSpout。通用推荐平台接收的数据共有五类,包括类别数据,行为权重数据,商品属性,用户属性,以及用户行为数据。
类别数据:是各个商品的类别的描述和等级,用于基础数据统计
行为权重数据:各个行为的权重,用于基础数据统计
商品属性:各个商品的基本属性,基础数据统计
用户属性:用户的基本属性,基础数据统计
用户行为数据:记录了用户的行为,是系统主要要分析的数据。
数据预处理层
包括两个部分,一个是基础信息构建,对应的bolt是BaseInfoBolt,一个是对用户行为数据进行预处理,对应的是PretreatmentBolt。基础信息构建接受类别、行为权重、商品属性和用户属性四种数据,并存入相应的table。预处理bolt接受用户行为数据,根据用户群信息和历史数据对用户行为记录进行补全或者过滤等。
算法处理层
算法处理层是系统的主体部分,又可以分为数据统计部分和算法计算部分。数据统计部分包括用户详细信息统计,最近访问商品统计,人群行为数据统计,人群商品共现数据统计,场景Ctr统计等。
算法计算部分实现了CF,MF,Hot,CB等算法。这里对算法进行描述。
商品信息补全层
商品信息补充层负责对算法结果进行商品信息补全,这里补全是为了后续与离线模型结合或向用户推荐时,根据商品信息来对算法推荐结果进行筛选后对相应用户进行推荐,比如,根据商品价格和离线模型分析的用户财富层次等对推荐结果进行筛选,有些商品是vip免费的,可以对vip用户推荐,而对普通用户则要慎重考虑。
存储层
存储层是系统的最后一层,负责将推荐结果存入tde,tde是腾讯构建的一个内存k-v存储,对用户进行在线推荐时,从tde中取出推荐结果,与离线模型结合,对推荐结果进一步处理后推荐给用户。
2.2 实现优化策略
针对实现过程中遇到的问题和挑战,我们提出了几点优化策略以优化资源使用、提升效果。
分群计算:在实际计算过程中,我们根据不同的用户群体对数据进行了划分,并在划分数据集上进行计算。用户群体可根据用户年龄、性别等进行划分,也可根据其他信息如职业、活跃度等进行划分。由于不同群体内的用户行为模式可能不同,在经过划分的数据集上进行计算,可以得到更准确的用户行为模式。
滑动窗口:为了保证数据模型的实时性,某些情况下需要对历史数据进行“遗忘”,即只使用最近一段时间的数据来进行计算。为此,我们实现了滑动窗口,对于某个时间单位,我们维护近n个时间窗口的数据信息,这些窗口会实时滑动,丢掉最远的数据,保留最近的实时数据信息用于计算。
局部集成:为了有效维护计算数据,我们使用了TDE作为数据外部存储,而在计算过程中与TDE的交互成为了计算开销不可忽视的一部分。为了减少与TDE的交互,降低资源使用,我们使用了局部集成策略,根据不同的计算特点,将数据先在worker内部做集成,然后再将局部集成结果合并到TDE。实践证明,这一策略有效降低了与TDE的交互,减少了资源使用。
多层Hash:在计算过程中,会出现有多个worker需要写同一个Key-Value值得到情况,称之为写冲突,为了保证TDE的高可用性,我们使用了多层Hash策略来解决写冲突问题,减小了TDE在数据一致性上的负担。通过多层Hash策略,对同一个key的写操作将只发生在同一个worker上。
实时可扩展item-based CF
基于物品的协同过滤推荐[2](item-based CF)是亚马逊于2003年公布的推荐算法,由于其推荐效果较好且易于实现等特点,在工业界得到了广泛应用。这里我们以item-basedCF算法为例,解释实时推荐算法的具体实现[3],有关其他算法的具体描述可参考论文[3]和[4]。
3.1 原始Item-basedCF
Item-based CF的基本思想是认为用户会喜欢和他以前所喜欢的物品相似的物品,其计算分为相似物品计算和用户喜好预测两部分,相似物品计算是整个算法的关键部分,用户喜好预测根据物品相似度加权预测用户对新物品的评分。


3.2 实时item-basedCF
在传统的推荐算法中,用户对物品的喜好评分由用户打分决定,而现实世界中,用户对物品的打分数据较少,大部分数据是用户行为数据,如浏览、点击等,这些用户行为具有不确定性,比如,用户点击一个物品详情页后关闭,可能表示用户喜欢该物品因为用户点击了详情页,也可能表示用户不喜欢该物品因为用户又关闭了详情页。这种情况下,我们只能从用户行为数据中去猜测用户的喜好。
为了降低对用户行为数据的错误理解造成的损失,我们对原始item-basedCF算法进行了改进。具体来说,我们为每个用户行为类型设置了评分权重,衡量不同行为表示的用户喜好的可靠性,如,对点击行为我们设定其评分权重为一分,而购买行为三分,因为用户的购买比点击更有可能说明用户喜欢该物品。对于一个物品,用户可能有多种行为,比如点击、购买、评论等,这时我们取权重最高的用户行为评分作为该用户对物品的喜好。
我们定义了用户对两个物品的共同评分用于计算物品相似度,如下:
通过将物品的共同评分设定为两个物品评分中较低的那个,我们限定了对行为错误估计的损失为两者的较小值。相应的,两个物品的相似度计算如下:
为了实现流式实时计算,实时更新物品的相似度,我们将上式计算分为了三部分,如下:
其中, ,


3.3 实时剪枝策略
在实际计算过程中,我们发现,由于数据量太大,用户的某一个行为会带来大量的物品需要重新计算。具体来说,我们一般认为用户在某一时间段中交互的物品相互之间相关,即可能相似,这个时间段可能是一天或者一个月,那么一个用户行为带来的物品评分更新,可能会造成数十甚至数百个物品对的相似度需要重新计算,而这些物品对很多可能是不那么相似的,即
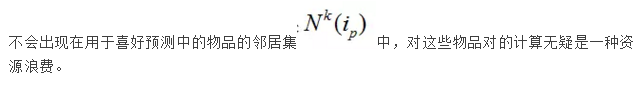

4 总结
随着近年来个性化服务的发展,推荐系统在实际应用中的价值也得到越来越多的认可,大数据实时推荐在推荐效果上的优秀表现,以及其巨大的发展空间,使其获得很多的关注。大数据实时推荐仍然有许多值得探索的地方,如实时矩阵分解、实时LR、实时深度学习等在线学习算法。
[1]“腾讯实时计算平台(TRC)系列之一:初识TRC”
[2]G. Linden, B. Smith, and J. York. Amazon.com recommendations: Item-to-itemcollaborative filtering. In IEEEInternet Computing, 7(1):76–80, Jan. 2003
[3] Yanxiang Huang, Bin Cui, Wenyu Zhang, Jie Jiang,and Ying Xu. TencentRec: Real-time Stream Recommendation in Practice. [C]//Procof the 2015 ACM SIGMOD Conference. ACM, 2015: 227-238
[4]Yanxiang Huang, Bin Cui, Jie Jiang, Kunqian Hong, Wenyu Zhang, Yiran Xie.Real-time video recommendation. In SIGMOD 2016
文章来源36大数据,www.36dsj.com ,微信号dashuju36 ,36大数据是一个专注大数据创业、大数据技术与分析、大数据商业与应用的网站。分享大数据的干货教程和大数据应用案例,提供大数据分析工具和资料下载,解决大数据产业链上的创业、技术、分析、商业、应用等问题,为大数据产业链上的公司和数据行业从业人员提供支持与服务。
End.
最后
以上就是激动宝马最近收集整理的关于大数据实时推荐-不只是统计的全部内容,更多相关大数据实时推荐-不只是统计内容请搜索靠谱客的其他文章。








发表评论 取消回复