一个自动抢图书馆研讨间的脚本实现
最近尝试了图书馆的研讨间以后觉得实在是太香了,既可以满足我的学习效率要求,又能让我没有一种被大家盯着的感觉,但是就是因为太香,所以特别难抢,我们设置晚上九点开抢,之前因为手速不太够,没抢到,所以想着写个脚本,直接一键抢,舒服
Ps:我对于爬虫不太了解,之前看爬虫,没看进去,结果现在自己想写个脚本都不会呜呜呜,所以从网上找了别人的代码,仔细研究(疯狂百度)以后,大概弄明白了,并在这里分享给大家,还是希望大家以学习为主,不要给网站整崩了
首先使用脚本来实现抢座(暂且这么称呼),其实就是以自己组装报文以欺骗浏览器以为是正常访问操作,所幸python为我们提供了相关的库
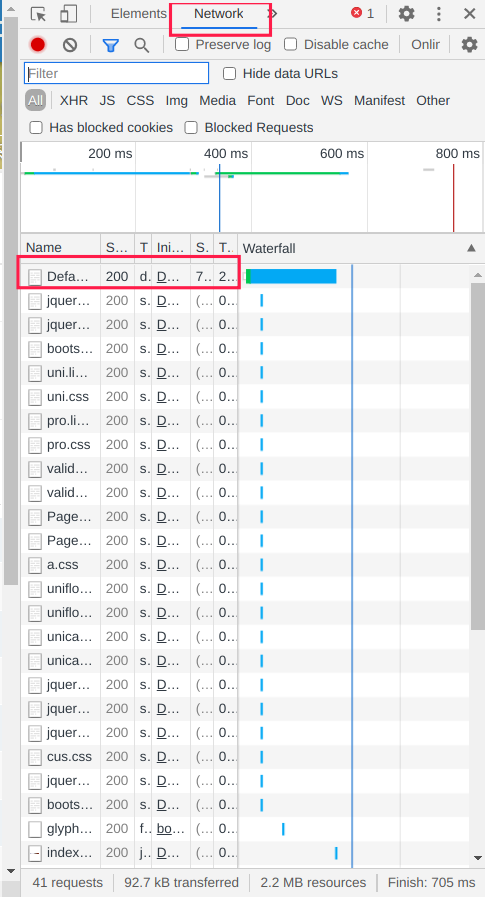
首先我们有一个登录函数(实际上我推荐自己先登录着,这样能简单很多)我们其实可以打开浏览器的开发者工具,在进行登录操作以后,可以在其中的network栏看到自己发送的请求,点开红色方框标记的请求报文,可以看到Request Headers,将其中的参数复制设置为自己的login_header
import requests
# 登录函数
def login(user_id, passwd):
"""
用来模拟用户的登录行为,目前还无法自主识别验证码,需用户自己登录
:param user_id: 用户登录时的 id
:param passwd: 用户登录时的 password
:return: 返回创建好的连接
"""
login_header = {
'Accept': 'XXX',
'Cookie': 'XXX',
'Host': 'XXX',
...
}
# 要登录的网站
login_url = 'XXXXXXXXXXXXXXXXXXXXX'
# 建立session就是建立连接并保持,这样cookie可以持续用
spider = requests.session()
request = spider.get(url=login_url, headers=login_header)
# 返回登录成功的实例
return spider
然后我们将其中的cookie复制以后保存好,这样等会预订的时候直接用。我们再在浏览器中预约个房间试试,并再次查看此时的Request Headers,然后写一个预约函数模拟用户的预约行为:
import json
# 预约函数
最后
以上就是整齐火龙果最近收集整理的关于python写一个抢研讨间的脚本的全部内容,更多相关python写一个抢研讨间内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复