1、程序的内存布局
程序运行时叫进程
就是进程的虚拟地址空间
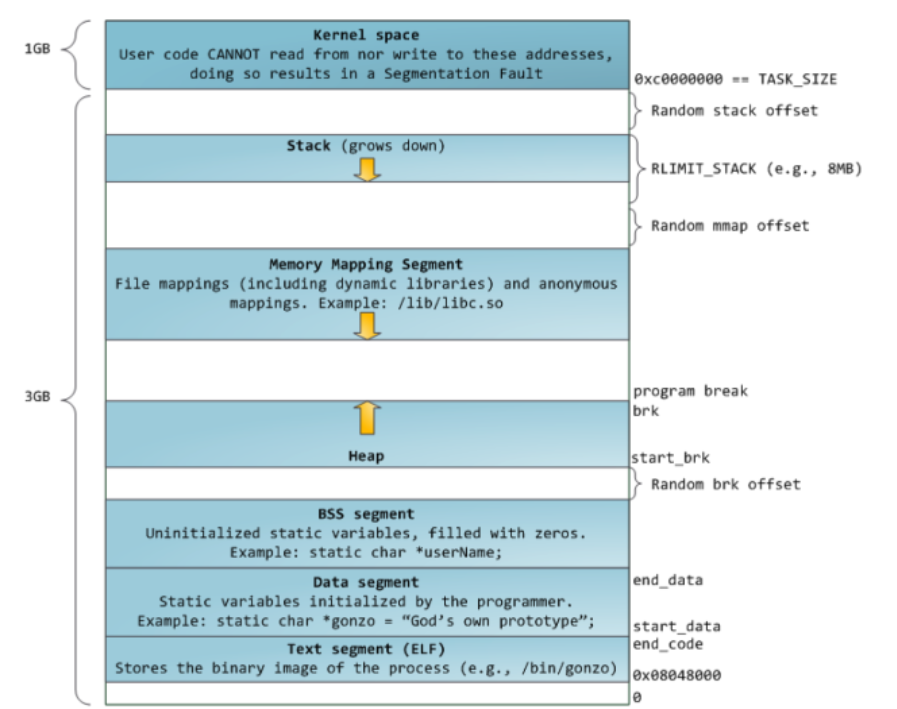
这张图是32位x86体系下的进程的虚拟地址空间,下面是低地址,上面是高地址。
我们从最下面(低地址开始看)往上看:
- 从0-0x08048000是0地址,然后从0x08048000往上,放的是代码段(.text段:指令,只读不能写);
- 数据存储的.Data和.BSS段(没有初始化/初始化为0)
- 然后是堆Heap(malloc,new)
- 然后是Memory Mapping Segment共享库(printf,scanf这类要包含头文件的函数,比如说,我们写printf或者scanf,要包含<stdio.h>,这个头文件只有这两个函数的声明,没有定义实现,这些函数的实现是在libc.so里面,当我们程序运行的时候,如果需要用到printf或者scanf的时候,我们就会去加载libc.so共享库,这些共享库就在Memory Mapping Segment);
- 然后再往上看,就是我们函数运行的栈Stack了(系统调用,函数详细的调用堆栈过程);
- 下面的3GB是用户空间,上面的那1GB是内核空间(Kernel space)。
一个系统上可以运行几百个进程,每个进程它的用户空间都是独立的,但是内核空间都是共享的,因为操作系统只有1份!
关于.text段和.rodata段:
在进行内存布局的时候,操作系统去管理内存,都是以页面来进行分配的,但是.text段不一定就占1个页面,也有可能它不够用,会占用2个页面。
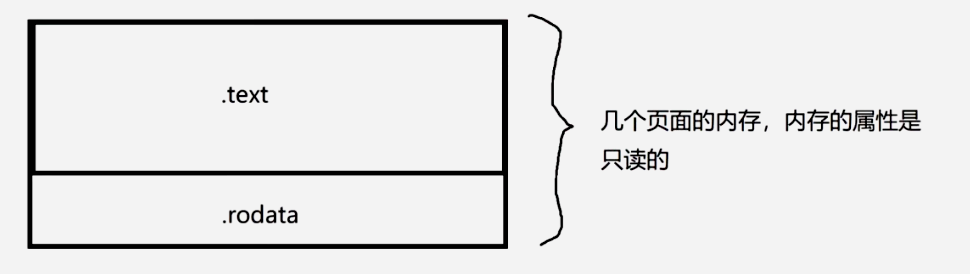
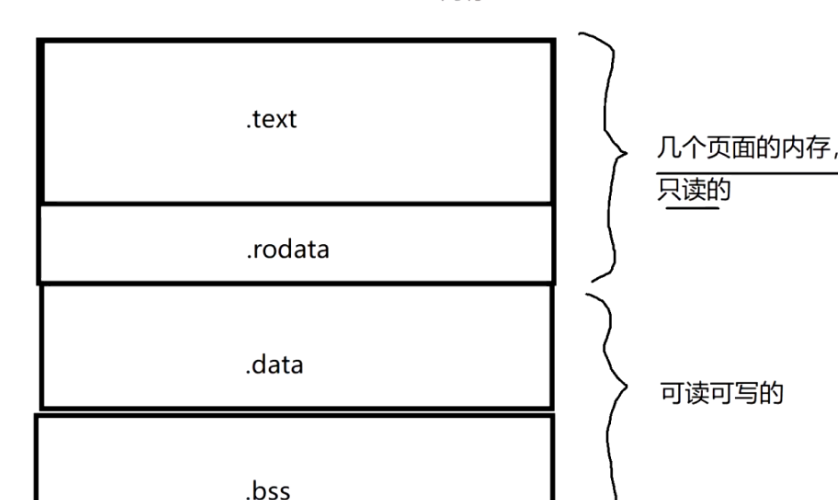
从段的角度来说,.text段和.rodata段是没有杂到一块存储的。
从内存的角度来说,它们都是相同内存属性的段,是放到同一块的。
再比如说,.data段和.bss段在内存上,属于同一个内存属性:可读可写,也是放到同一个段。
从段的角度来说,是肯定不会杂到一块放的,从内存的角度来说,是在一块放的。
2、堆和栈的区别

在内存层面,堆内存和栈内存的区别:
- 堆内存是: 在代码上通过malloc或者new,通过free或者delete还释放堆内存。堆内存是我们用户手动开辟的,手动释放的。
- 栈内存是: 调用一个函数,就用到栈的内存,出函数的右括号},栈内存进行回收。栈内存是系统自动开辟,自动释放的。
在数据结构上:
- 栈是属于线性表,满足先进后出,后进先出的线性表
- 堆不是线性的,常用的是二叉堆,就是二叉树,二叉堆经常用的,大根堆(该二叉树中所有节点的值最大的那个节点在堆顶,就是根节点)或者小根堆(该二叉树中所有节点的值最小的那个节点在堆顶,就是根节点)
- 应用场景: 优先级队列(priority queue),C++底层默认实现的是大根堆)
3、函数调用参数是怎么传递的?
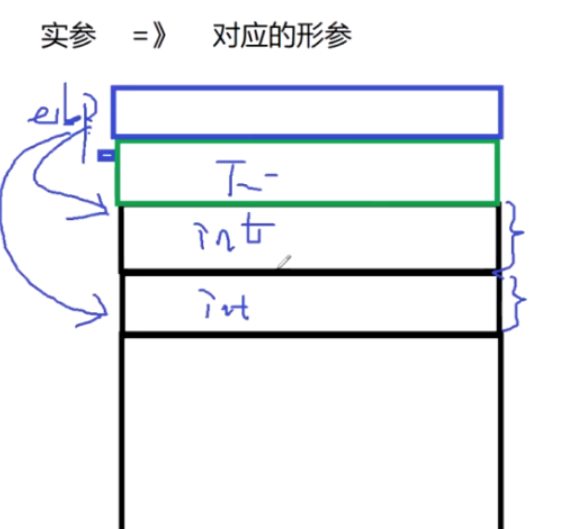
函数调用,参数压栈:
从右向左,先压右边的实参入栈,压完实参后,就该压下一行指令的地址,然后把调用方(main函数的栈底地址ebp)压过来,然后访问形参,然后通过ebp指针的偏移访问相应的实参,ebp+4,访问到第一个实参,ebp+8访问到第二个实参。
4、为什么函数调用的参数要从右向左压栈
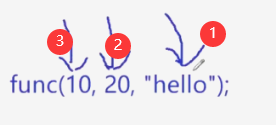

我们写可变参,最前面左边得有一个参数,后面才能加…表示可变参。

可变参怎么用?

这两次func调用,第一个参数10都是传给a,后面传几个参数无所谓,是可变的,类型不一样也可以。
我们的printf就是一个可变参:

第一个参数(格式化字符串)里面有多少个%d,%c等等,后面就写对应的参数个数。
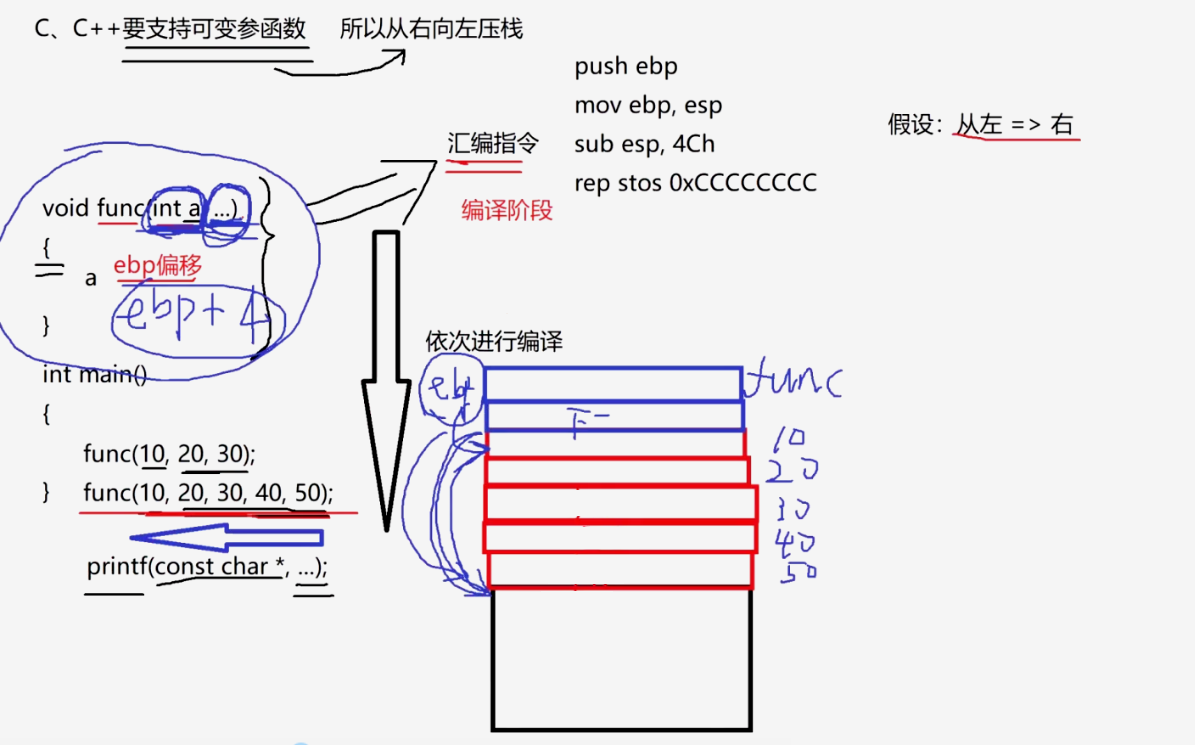
我们知道,代码是从上到下依次进行编译的,在编译到func函数的时候,高级源代码都要编译成汇编指令,这个汇编指令一进入这个函数的左括号{,执行push ebp,把调用方main函数的栈底地址ebp压到当前函数栈的栈底,也就是func函数的栈底,然后执行mov ebp esp,把esp的值赋给ebp,让ebp刚才指向main函数的栈底,现在指向func函数的栈底,
然后sub esp,4ch 就是给func函数开辟栈帧,调用一个函数就开辟栈帧;
在VS下,还有一个指令操作:rep stos 0xCCCCCCC,gcc下是没有这个操作的。
然后,我们这个func函数里面,有这个参数,它要访问这个参数a,
假如说这个参数是从左向右压栈的,10就是在最底,然后20,30,40,50。
但是指令是在编译时生成好的,它运行的时候是不会自己选择的,怎么样生成的指令,怎么样运行就可以了,关键是func函数在编译的时候,取参数,取a是怎么取的?
栈上取这个局部变量都是通过ebp的偏移来取的,func函数在编译的时候,根本就没有办法访问到这个a了,因为现在是从左向右压的,第一个参数肯定是在栈底,后面的参数在栈顶,紧接着压下一行指令地址和func函数的ebp,func函数在编译阶段,不知道它会有多少个参数,不知道用户传几个参数,根本不知道,它在访问a,不知道把ebp偏移多少,所以是没有办法生成指令去访问它的参数的,因为编译阶段不知道用户会传多少个参数。
所以它必须把左边的这个已知的参数必须放在离ebp最近的地方,反着压!
已知的这个参数就在栈顶了,所以它就永远知道ebp+4就是这个已知的参数的内存!!!!
在以后运行的时候,不管用户在这里传的是多少个参数,就是可以通过ebp+4来访问第一个参数,然后接着往下访问,就是可变参的参数了,在编译阶段,就可以给可变参数生成指令了!!!它生成指令就可以把下面的所有参数都可以访问完了。
所以说,从右向左压参数,意味着第一个参数是最后压的,最后压的肯定在栈顶,最后在func函数生成指令的时候,ebp+4就可以访问到这个第一个参数a了。
如果编译的时候是从左向右压的,意味着左边的先压的在栈底,右边先压的在栈顶,在编译阶段,不知道参数有多少个,怎么通过ebp偏移访问第一个参数a呢?没有办法访问啊!
也就是说,从右向左压,才能合理的确定参数的个数。
我们看printf,通过可以访问第一个参数:格式化字符串,能访问这第1个格式化字符串,就根据里面的%d%c之类的就可以往下继续取其他的参数了。
如果看到有一个%d,就向下访问,如果又看到有一个%c,也继续向下访问,直到访问到这个格式化字符串的�了,停止向下访问。
6、有一个函数


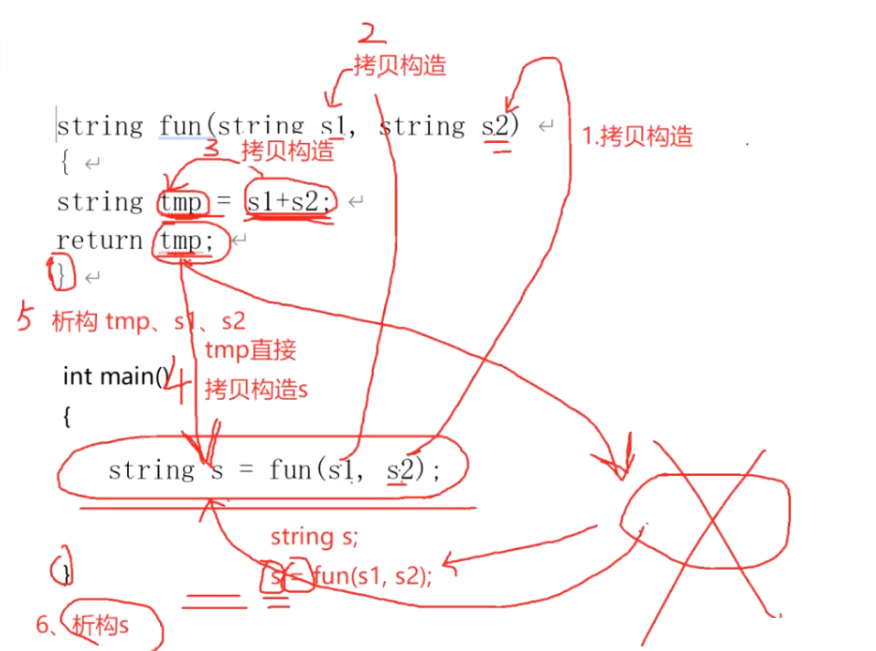
参数是从左向右压的,从实参到形参,我们看到这是既没有用指针传递,也没有用引用传递,所以都是要生成新的string对象,实参s2,s1到形参s2,s1,调用的是拷贝构造函数,这里调用2次拷贝构造函数,先构造s2,然后构造s1;(引用接收就不会有拷贝构造了)
string tmp=s1+s2;这里s1+s2会产生一个新的string对象,然后拿这个新的string对象拷贝构造tmp对象。
然后tmp对象返回,通过C++11本身的优化,调用右值的拷贝构造函数(移动构造函数),拿tmp直接拷贝构造main函数的s对象,然后出fun的右},析构tmp对象,然后析构s1, 然后析构s2,最后析构s。

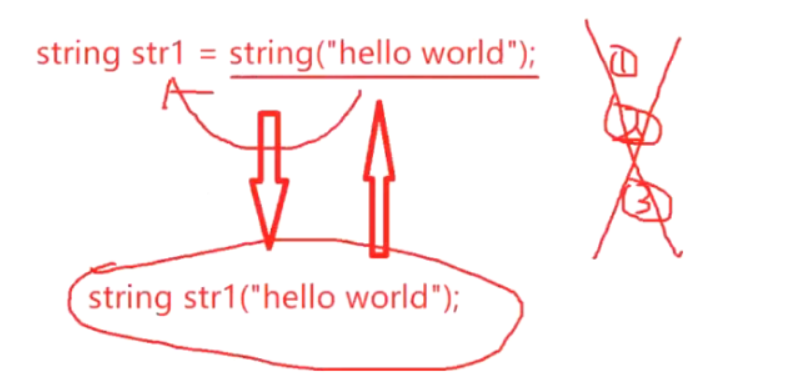
也就是,因为C++编译器的优化,下面这2种写法等价:(不会先调用构造,再调用拷贝构造)
我们再看,如果写成这样:

现在是s1+s2的结果直接拷贝构造主函数的s对象了。省去了刚才tmp的拷贝构造和析构函数的调用。
注意:

7、一个结构体里面定义了一个char和double,它的内存布局?

答案是16
- C语言的结构体和C++的类都是要内存对齐,方式是一样的
- 第一行:char占1个字节,剩下的7个字节补位的;第二行的8个字节就是double。

就是1!

都是char,最长的分量是1个字节,按1个字节对齐,总共3!
空结构体多大?

空结构体大小为1!
我们的总结如下:
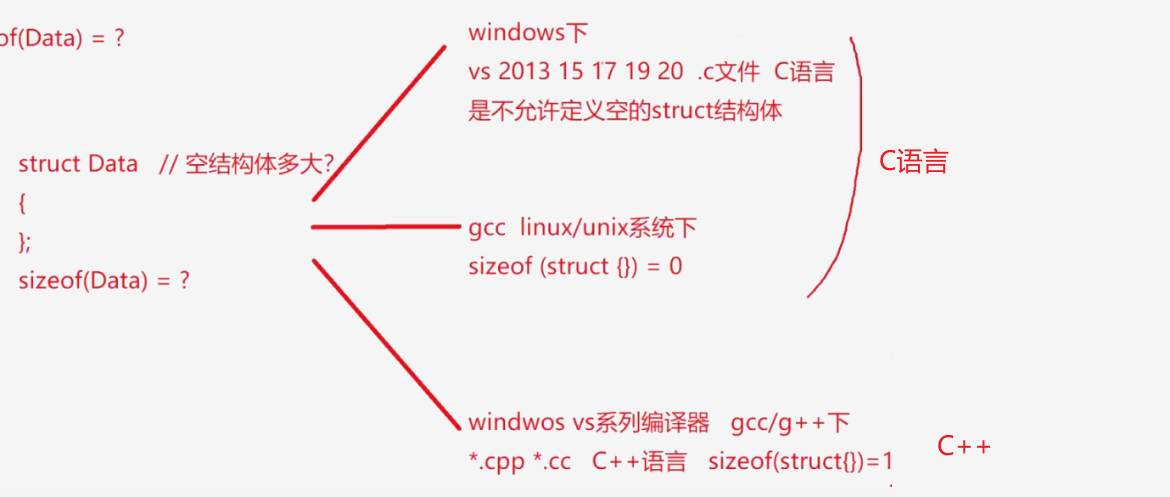
为什么在gcc下,C语言的空结构体大小是0,C++的空结构体大小是1?
- 1、空结构体,不需要访问什么东西,啥也改干了,所以C语言中,定义空结构体的大小是0;
- 2、而在C++中,struct定义的东西不叫变量,叫做对象。
- 对象和变量的本质区别是: 定义一个变量只需要内存就可以了,但是C++生成对象时得先有内存,然后还得要有构造,构造函数编译的时候会生成this指针,所以,要生成对象,必须要有一块内存,给this传地址,才能调用构造,创建对象。
- 所以创建一个空的结构体(空类),大小是1,因为内存的最小单位是字节,就是1个字节大小。构造函数只有知道内存地址,才会去这个内存地址上做构造对象。

sizeof(Test) 和 sizeof(t) 是一个意思!
比如下面的sizeof(Data)和sizeof(data)大小都是1。
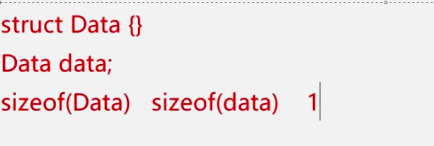
只有空结构体大小是1,或者结构体中只有一个char类型的变量,大小是1,其他的都是按照变量大小内存对齐

基类和派生类都是空类,但是只是继承关系,Data3就是空类,大小就是1。

在32位系统下,如果是空类虚继承空类,多了一个vbptr指针,所以大小是4字节。

如果基类中有虚方法,就会产生虚函数表,则派生类虚继承这个基类,又多了一个vfptr,所以此时,大小是8字节(x32系统)。
不管多少个虚函数,都是只有一个vfptr哦,影响的只是虚函数表vftable的大小而已,不影响对象的大小,都是只有一个vfptr
8、智能指针问题

9、继承和多态问题
最后
以上就是想人陪洋葱最近收集整理的关于263-面经1(商汤C++机器学习)的全部内容,更多相关263-面经1(商汤C++机器学习)内容请搜索靠谱客的其他文章。








发表评论 取消回复