最近邻分类器
近邻算法的目的是使用一系列的已知类别的训练集合tr_set来推测未知类别的测试数据te_data的类别,方法是计算te_data和训练集合tr_set中的所有数据的距离,找到训练数据中与测试数据最近的一个数据,由于训练数据的类别已经知道了,我们可以大胆推测测试数据类别就是这个距离最近的训练数据的类别。但是推测并不一定准确,近邻算法基于统计学,有一定的错误概率。
最近邻分类器的改进版-k近邻分类器
直接根据距离最近这一个判断条件就推断出测试数据的类别有点武断,有可能这个距离最近的数据是一个非常奇葩的数据。我们放大范围,选择最近的k个已知类别的数据,由这些数据投票决定这个未知的数据的类别。也就是说距离测试数据最近的k个训练数据中类别频率最高的类别就是这个测试数据的类别。
如图所示: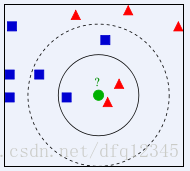 判断问号位置的点的类别,就看周围点的类别,如果k=3的话,这三个距离最近的点投票决定问号位置点的类别为三角形,如果k=5的话,最后判定结构就是正方形了。
判断问号位置的点的类别,就看周围点的类别,如果k=3的话,这三个距离最近的点投票决定问号位置点的类别为三角形,如果k=5的话,最后判定结构就是正方形了。
使用nn算法和knn算法识别手写数字
将手写数字形成的二维图形转变位一维向量,使用欧式距离来评价两个向量直接的距离,nn算法直接返回最近邻向量的标签,knn算法对k个近邻向量的标签进行了一个统计,返回了出现频率最大的标签。最后统计出现错误的概率
main.py
import os
import numpy as np
from kNN import img_2_vec1, classify_nn, classify_knn
if __name__ == "__main__":
# 用于测试的入口
# 构造样本测试数据集合和对应标签
tr_files = os.listdir("./digits/trainingDigits")
tr_set = np.zeros((len(tr_files), 1024))
tr_label = []
for i in range(len(tr_files)):
tr_set[i, :] = img_2_vec1("./digits/trainingDigits/{}".format(tr_files[i]))
tr_label.append(tr_files[i].split("_")[0])
# 导入test样本数据并计算并预测标签
err_cnt = 0
te_files = os.listdir("./digits/testDigits")
for file in te_files:
te_data = img_2_vec1("./digits/testDigits/{}".format(file))
ret_label = classify_nn(te_data, tr_label, tr_set)
# ret_label = classify_knn(te_data, tr_label, tr_set, 3)
te_real_label = file.split("_")[0]
if ret_label != te_real_label:
err_cnt += 1
print("{} is classify to {}, but the real answer is {}".format(file, ret_label, te_real_label))
# 计算错误率
print("err_cnt = {}, total_cnt = {}, error_rate = {:.4f}".format(err_cnt,
len(te_files),
float(err_cnt)/len(te_files)))
kNN.py
import numpy as np
import operator as op
def img_2_vec1(filename):
"""
img_2_vec1 将图像文本转换为向量
:param filename:
:return:
"""
res = np.zeros((1, 1024), dtype=int)
with open(filename, "r") as file_obj:
lines = file_obj.readlines()
for i in range(32):
for j in range(32):
res[0, 32 * i + j] = int(lines[i][j])
return res
def classify_nn(te, labels, tr_set):
"""
nn分类器 (nearest neighbor)
:param te:
:param labels:
:param tr_set:
:return:
"""
num_tr = tr_set.shape[0]
distance = ((np.tile(te, (num_tr, 1)) - tr_set) ** 2).sum(axis=1)
min_index = np.argmin(distance)
return labels[min_index]
def classify_knn(te, tr_labels, tr_set, k):
"""
knn分类器 (k nearest neighbor)
:param te:
:param tr_labels:
:param tr_set:
:param k:
:return:
"""
num_tr = tr_set.shape[0]
dis = ((np.tile(te, (num_tr, 1)) - tr_set) ** 2).sum(axis=1)
sorted_indicate = np.argsort(dis)
vote_cnt = {}
# 取距离最近的k个进行投票选择
for i in range(k):
vote_label = tr_labels[sorted_indicate[i]]
vote_cnt[vote_label] = vote_cnt.get(vote_label, 0) + 1
# 返回票数最多的标签
sorted_vote_cnt = sorted(vote_cnt.items(), key=op.itemgetter(1))
return sorted_vote_cnt[-1][0]截图分析:
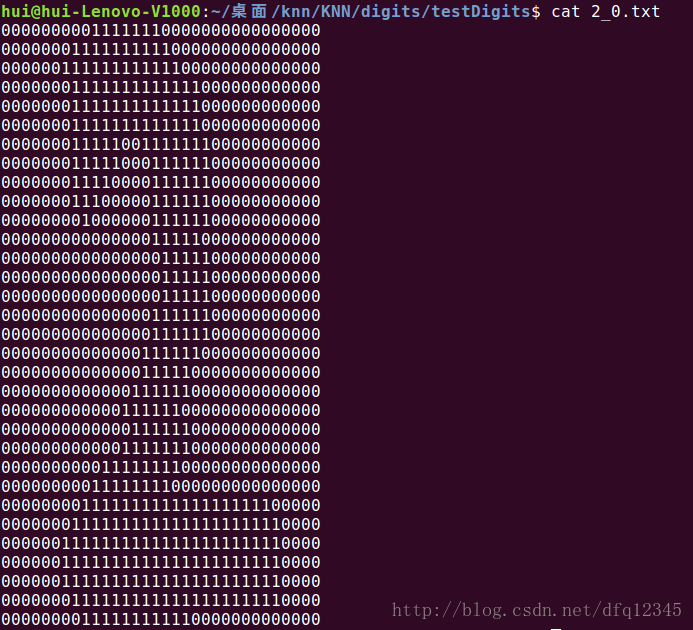
为简化图片文件的处理,使用了01表示出数字的框架,如图
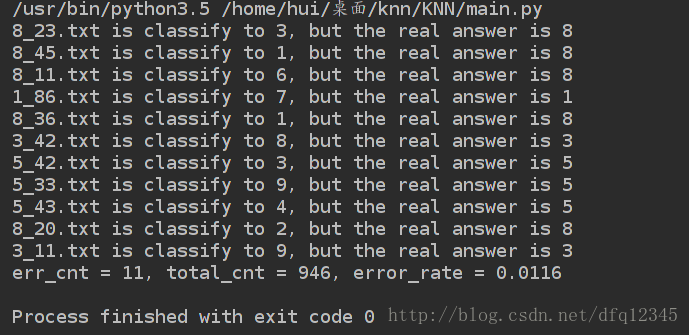
使用knn算法进行图片的归类
最后
以上就是鲤鱼航空最近收集整理的关于k近邻算法实现手写数字的识别和图片的分类的全部内容,更多相关k近邻算法实现手写数字内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复