CCF-S级会议ICLR刚刚放榜~(小编要是中了ICLR能吹一年????????????
这里推荐几篇ICLR 2021接收的最新GNN论文~
1.时序网络中的利用因果匿名游走的归纳表示学习
2.具有自监督能力的图注意力机制
3.图神经网络的瓶颈及其实践意义
4.ADAGCN:将图卷积网络转换为深层模型
5.通过图多层池化准确学习图表示
6.基于神经网络的图粗化
1.INDUCTIVE REPRESENTATION LEARNING IN TEMPORAL NETWORKS VIA CAUSAL ANONYMOUS WALKS

https://arxiv.org/pdf/2101.05974.pdf
时序网络是现实世界中动态系统的抽象。这些网络通常根据某些定律发展,例如社交网络中很普遍的三元闭包定律。归纳表示学习时间网络应该能够捕获此类定律,并进一步将遵循相同定律应用于未在训练过程中见过的数据,即inductive的能力。以前的工作主要依赖于网络节点身份或丰富边属性,通常无法提取这些定律。因此,本文提出了因果关系匿名游走(Causal Anonymous Walks, CAW)来inductively的进行时序网络的表示学习。
具体来说,CAW是通过时间随机游走提取类似motif的结构来捕获图的动态性,这避免了motif计算复杂的问题。同时,CAW采用新颖的匿名化策略,用一组节点的命中计数来替换节点身份以保持模型inductive的能力,同时也建立了motif之间的相关性,这对于某些图挖掘任务(如链路预测)是非常关键的。进一步的,本文进一步提出了一个神经网络模型CAW-N来编码CAW。最后,在6个真实时序网络数据集上,CAW-N均取得了大幅度的提升,例如AUC提升了15%!
模型图
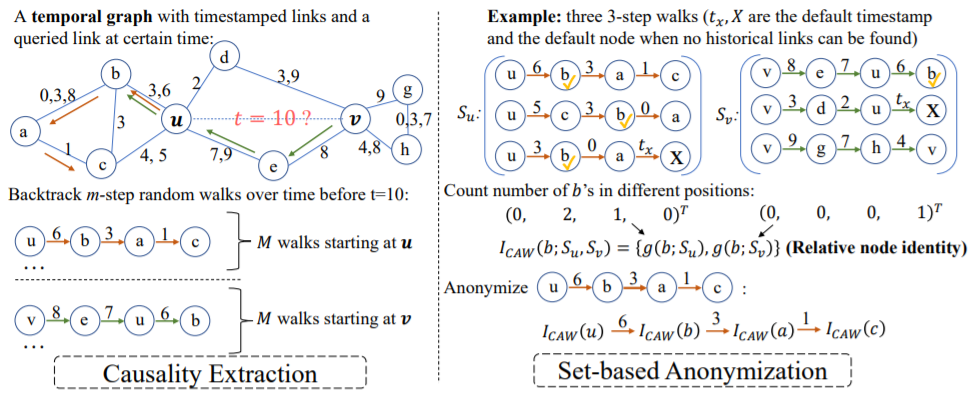
因果关系提取和基于集合的匿名
实验结果

可以看到CAW模型明显优于其他模型。
2.HOW TO FIND YOUR FRIENDLY NEIGHBORHOOD:GRAPH ATTENTION DESIGN WITH SELF-SUPERVISION

https://openreview.net/pdf?id=Wi5KUNlqWty
图神经网络中的注意力机制旨在分配更大的权重给重要的邻居节点,以进行更好地表示。但是,图神经网络学到的东西不是那么容易理解的,尤其是在有噪声的图上。而本文提出的自监督的图注意力网络(SuperGAT)就是用来解决这一问题的。
模型图
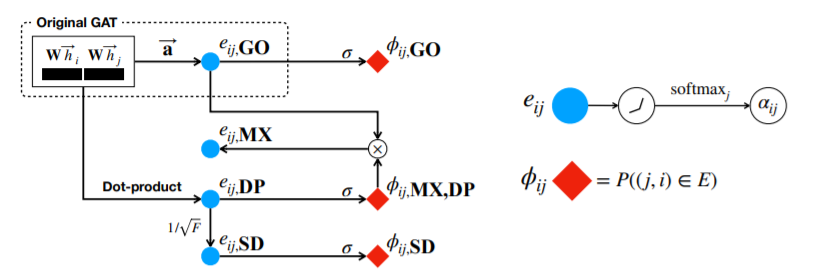
图1
原始GAT与SuperGAT对比:原始的GAT如矩形图中所示。SuperGAT通过一对节点中是否存在边来引导注意力。用 和 表示节点 和节点 之间有边的概率 ,即
实验结果
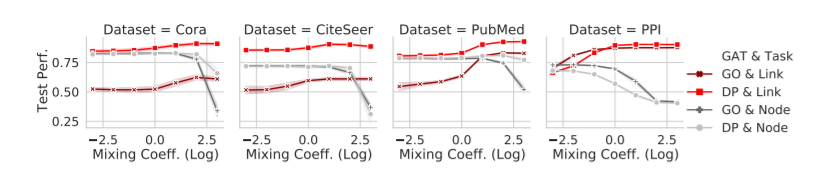
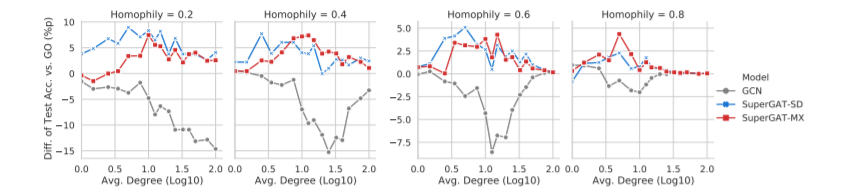
图2
3.ON THE BOTTLENECK OF GRAPH NEURAL NETWORKSAND ITS PRACTICAL IMPLICATIONS

https://openreview.net/pdf?id=i80OPhOCVH2
自从Gori等人提出图神经网络(GNN)以来,训练GNN的主要问题之一是在图中的远距离节点之间传播信息。本文提出GNN在较长路径中聚集信息时会出现瓶颈。这个瓶颈导致over-squarshing。这样GNN就无法传播源自远程节点的消息,执行效果也不好。本文中调整了远程GNN模型问题,无需任何调整或额外的权重即可突破瓶颈得到改善后的结果。
模型图
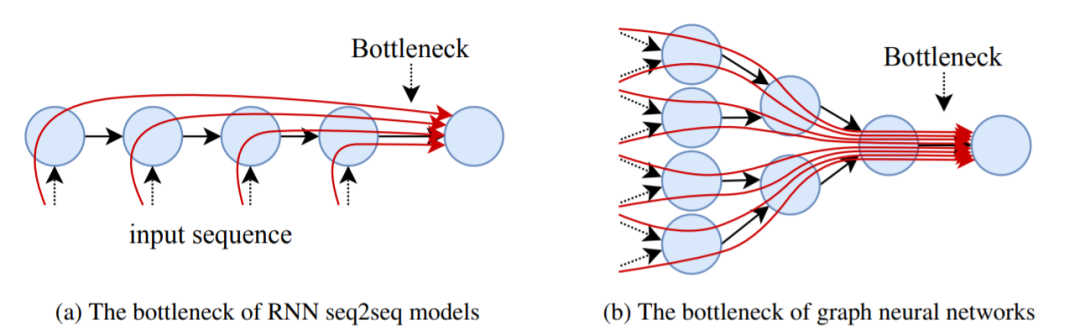
图3
从图中可以看出,相对RNN而言,GNN中的瓶颈对结果的影响更大。
这项工作并非旨在提出新的GNN变体。相反,这项工作的主要贡献是 :强调GNN固有的瓶颈问题,并说明瓶颈问题是有害的。
实验结果
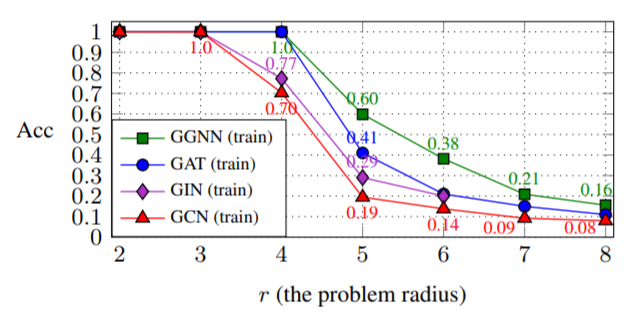
图4
从图中可以看出,在邻居匹配问题中,随着GNN深度的增加,模型的精确度在下降。
4.ADAGCN: ADABOOSTING GRAPH CONVOLUTIONALNETWORKS INTO DEEP MODELS

https://openreview.net/pdf?id=QkRbdiiEjM
深图模型的设计仍有待研究,其中至关重要部分是如何以有效的方式探索和利用来自邻居的跃迁。在本文中,通过将AdaBoost集成到网络计算中,提出了一种新颖的类RNN深度图神经网络架构。提出的图卷积网络AdaGCN(Adaboosting图卷积网络)具有有效提取来自当前节点的高阶邻居知识的能力。
不同于其他直接堆叠图卷积层的图神经网络,AdaGCN在所有“层”之间共享相同的基础神经网络架构并进行递归优化处理,类似于RNN。
此外,本文还在理论上建立了AdaGCN与现有图卷积方法之间的联系,从而展示了模型的优势。最后,用实验证明了AdaGCN的计算优势。
模型图
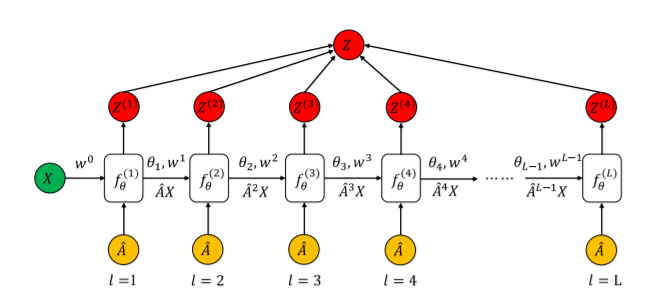
图5
实验结果
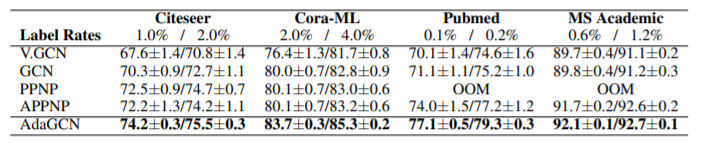
图6
表格中显示了不同模型的精度对比。可以看到AdaGCN比其他模型表现更好。
5.ACCURATE LEARNING OF GRAPH REPRESENTATIONSWITH GRAPH MULTISET POOLING

https://openreview.net/pdf?id=JHcqXGaqiGn
消息传递图神经网络已广泛用于建模图数据,在许多图形分类和链路预测任务上取得了很好的效果。然而,为了获得图形的准确表示还需要定义良好的池化功能,即在不丢失单个节点特征和全局图结构的前提下将节点表示集映射到紧凑的形式。
为了解决现有的图池化的限制,本文将图池化问题表述为带有关于图结构的辅助信息的多集编码问题,并提出了图形多集转换器(GMT)。该方法可以轻松扩展到以前的节点聚类方法,来进行分层图池化。实验结果表明,GMT明显优于其他图形池化方法,并在图重构和生成任务上获得很大的性能提升。
模型图
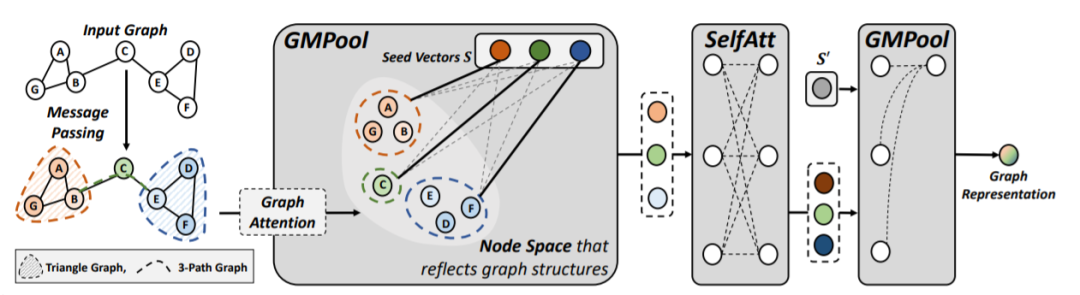
图7
实验结果
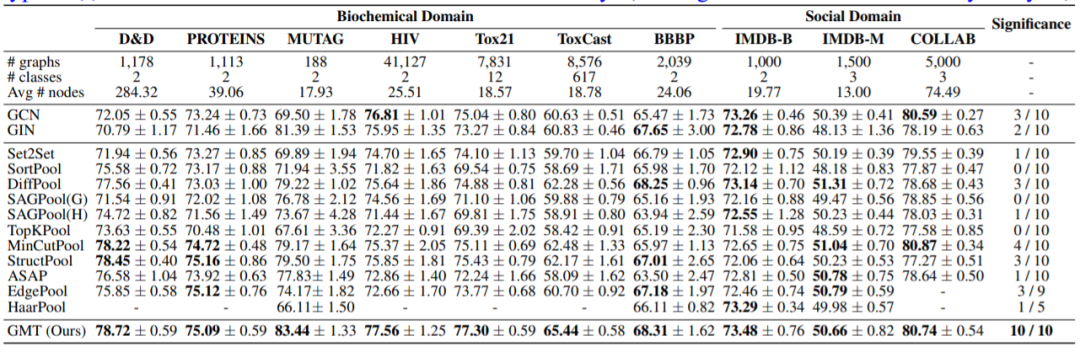
图8
从实验结果可以看出GMT比其他模型效果更好
6.GRAPH COARSENING WITH NEURAL NETWORKS

https://openreview.net/pdf?id=uxpzitPEooJ
随着大规模图的日益流行,处理,提取和分析大型图形数据的计算难题有着越来越重要意义。图粗化是一种在保持基本属性的同时减小图尺寸的技术。尽管有丰富的图粗化文献,但只有有限的数据驱动方法。
本文利用图深度学习的最新进展来进行图粗化。首先提出测量粗化算法质量的框架并说明我们需要根据目标仔细选择图粗化的Laplace运算符和相关的投影/提升运算符。由于粗化图的当前边权可能不是最优的选择,用图神经网络对权重分配图进行参数化并对其进行训练,以无监督的方式提高粗化质量。通过在合成网络和真实网络上进行的广泛实验,证明了该方法显着改善了各种条件下的常用图粗化方法指标,缩小率,图尺寸和图类型。它概括为较大的尺寸(训练图的25倍),可适应不同的损耗(可微分和不可微分),并且可以缩放到比以前大得多的图。
模型图
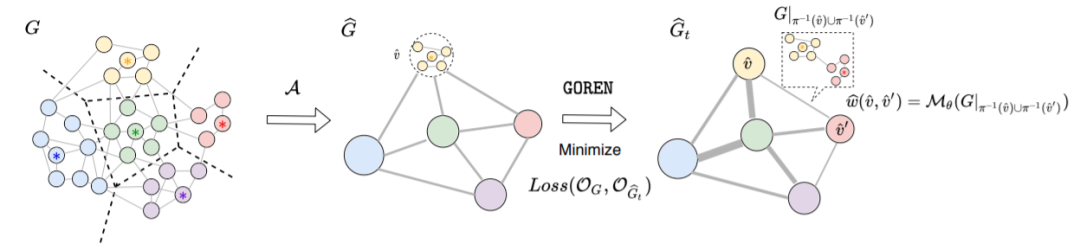
图9
实验结果
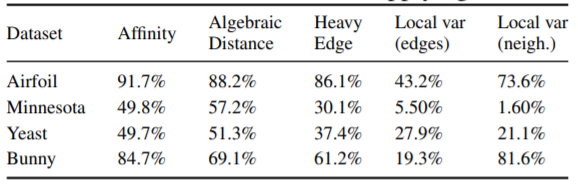
可以看到GOREN可以在不同类型的图上优化粗化方法。

最后
以上就是魁梧水壶最近收集整理的关于ICLR2021放榜~6篇SOTA GNN论文推荐的全部内容,更多相关ICLR2021放榜~6篇SOTA内容请搜索靠谱客的其他文章。








发表评论 取消回复