
目录
- Adaboost
- ADAGCN
- COMPARISON WITH EXISTING METHODS
- EXPERIMENTS
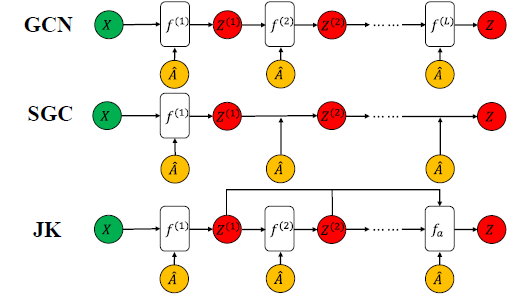
本文在GCN中首次引入了AdaBoost方法,提出了AdaGCN模型。与其他直接堆叠多个图卷积层的图神经网络不同,AdaGCN在所有层之间共享相同的基神经网络架构,并进行递归优化,类似于RNN。此外,还从理论上建立了AdaGCN与现有图卷积方法之间的联系,展示了本的方案的优点。
本文认为构建深度图模型的一个关键方向在于对来自不同邻域的信息进行高效的探索和有效的组合,单纯的多次聚合会导致深层网络的过平滑。因此,本文以一种非平凡的方式将AdaBoost整合到深度图卷积网络的设计中。首先,为了追求AdaBoost框架的引入,我们对图卷积的类型进行了细化,从而得到了一种新的类似rnn的GCN体系结构,称为AdaGCN。该方法可以有效地从相邻节点的不同阶次中提取知识,然后通过迭代更新节点权值,以AdaBoost的方式将这些信息结合起来。此外,我们还从架构差异和特征表示能力的角度将AdaGCN与现有方法进行了比较,以展示我们方法的优点。最后,我们进行了大量的实验,以证明我们的方法在不同的标签率和计算优势下始终保持最先进的性能。
Adaboost
先说一下AdaBoost算法。这一类方法的基本思想是,在同一个分类任务上去训练多个弱(基)分类器(分类器的效果必须要比瞎猜更好才行,不然会有负增益引入),然后所有的分类器的结果结合起来去做一个强分类器。对于AdaBoost而言,采用加权和的方式对弱分类器进行整合:
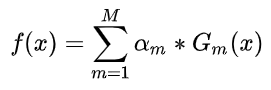
其中
a
m
a_m
am当然是权重啦,每一轮训练一个新的分类器
G
m
G_m
Gm ,并且根据这个分类器的误差得到这个分类器的权重
a
m
a_m
am。
ADAGCN
GCN的方法略,只简要给出下述公式:
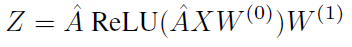
在本文的方法里,效仿SGC,将每层之间的非线性激活函数去除,因为SGC认为GCN层之间的非线性不是至关重要的,大部分好处来自于邻域特征的局部加权。但是非线性确实能给模型带来增益,在SGC的实验中,去除了非线性层导致了准确率稍有下降。那么,去除非线性层的模型就可以简化为:
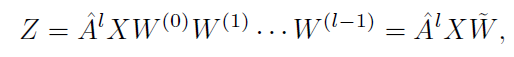
去除ReLU操作也可以缓解过度平滑问题,即减慢节点嵌入到难以区分的节点的收敛速度。因为本质上ReLU就是一个收缩函数,这会加速模型的拟合。但过分的拟合对GCN来说是有害的。但是,本文的作者发现这种不带激活函数的图卷积的堆叠线性变换在表示高阶邻域信息方面的能力不足,因此还是建议适当的利用非线性函数去建模。因此,使用了一个非线性的函数
f
θ
f_θ
fθ去代替参数矩阵
W
^
hat W
W^,比如两个全连接层:
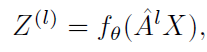
那么,如何使用AdaBoost?其实就是把深度模型的每一层输出的结果
Z
(
l
)
Z^{(l)}
Z(l)放到一个弱分类器中计算,并使用了SAMME算法将多个弱分类器结合起来:
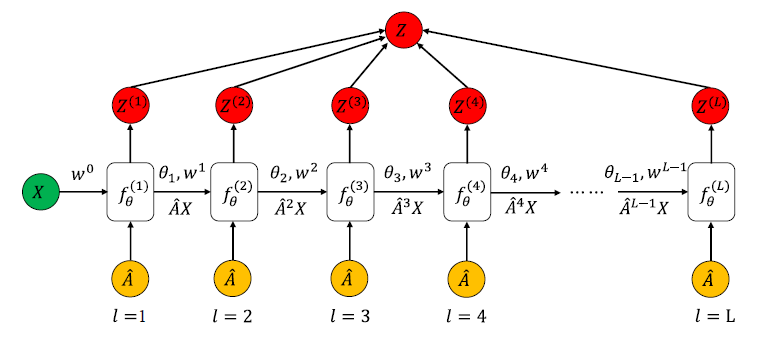
当前层的加权错误概率以及最终分类器的权重以如下方式计算:
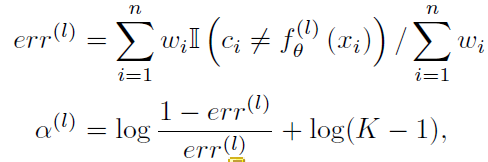
其中
c
i
c_i
ci表示节点
i
i
i的类别,
w
i
w_i
wi为权重参数。像是
I
I
I一样的表示指示函数,不等为1,相等为0。为了得到一个正的权重,需要保证:
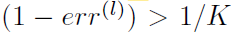
同时,在传播过程中向错误的节点增加权重以保证其
α
α
α的值减少,也就是对性能不咋地的分类器给予较少的权重:
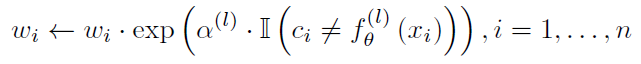
本文对所有的卷积输出都共享一个非线性变换
f
θ
f_θ
fθ,它在每个基分类器中递归优化,就像一个递归神经网络,也就是使用上一个基分类器的参数作为下一个基分类器的初始化。最终,所有分类器结合起来:
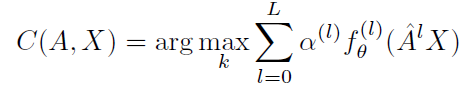
最后,得到AdaGCN的简化形式:
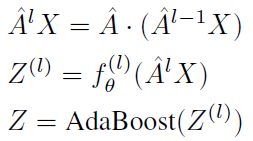
COMPARISON WITH EXISTING METHODS
Connection with PPNP and APPNP。AdaGCN可以被视为APPNP的一种自适应形式:
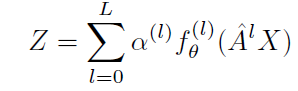
不过有些许不一样,APPNP需要在最开始做MLP得到初始特征,并且参数
α
α
α是为了获得初始残差而设计的(APPNP公式大概是如下所示,有需要可以自行看原论文):
Z
l
+
1
=
(
1
−
α
)
Z
l
+
α
Z
0
Z^{l+1}=(1-α)Z^l+αZ^0
Zl+1=(1−α)Zl+αZ0
而在AdaGCN中,参数是由第
l
l
l个基分类器的误差决定,而不是固定的指数减少权重。
一些其他奇奇怪怪的分析就看了,直接看一下实验结果。
EXPERIMENTS
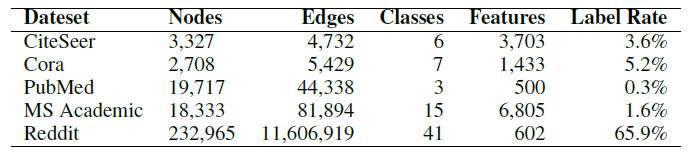
AdaGCN在深层模型有较好的性能,不会因为过平滑导致性能下降:
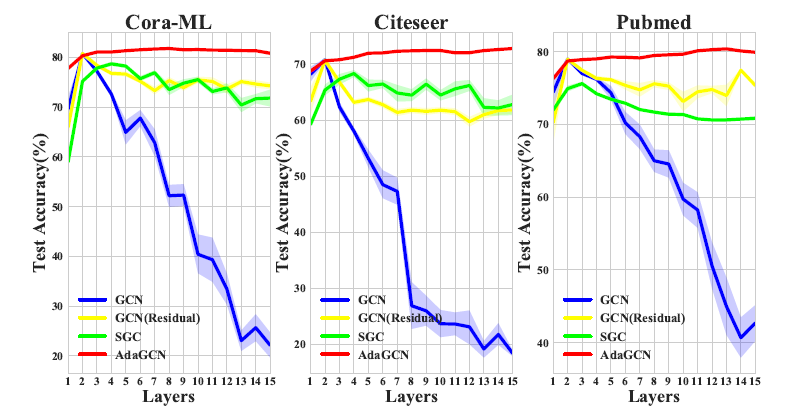
与其他基线算法对比:
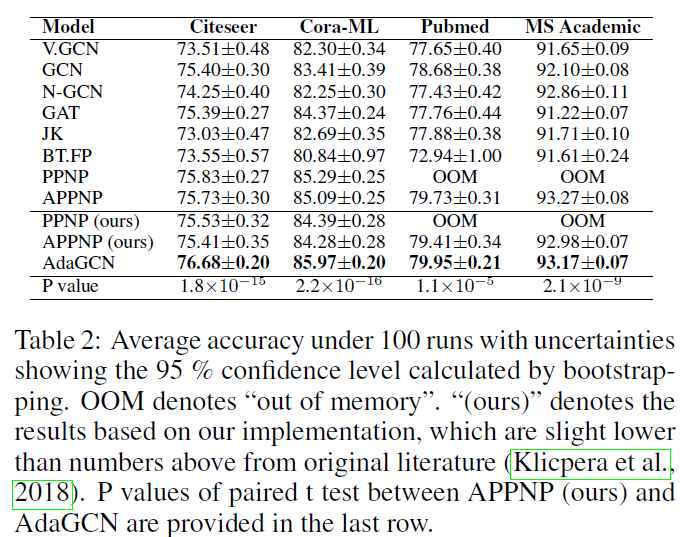
半监督下模型的性能:
计算效率:因为只是计算
A
l
A^l
Al,并可以在传播之前就定义好,复杂度只有矩阵乘法以及两层非线性函数,因此计算效率很高:
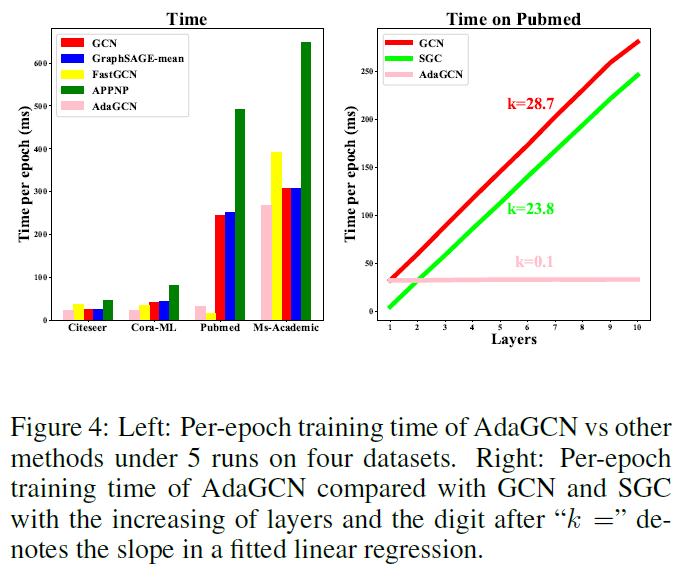
在图4的右半部分探讨了ReLU和稀疏邻接张量对层数的计算代价。斜率越高表示时间成本越大。AdaGCN不需要激活函数也不需要参数矩阵,因此斜率超级低。
最后
以上就是听话母鸡最近收集整理的关于GNN 2021(一) AdaGCN: Adaboosting Graph Convolutional Networks into Deep Models,ICLRAdaboostADAGCNEXPERIMENTS的全部内容,更多相关GNN内容请搜索靠谱客的其他文章。








发表评论 取消回复