手写数字识别
——用TensorFlow实现简单的单层神经网络
引言
大多数人在学一门新的编程语言时,通常要写的第一个程序是输出“Hello World”,在人工智能中,手写数字识别问题就是“Hello World”,本文将简要介绍如何使用TensorFlow构造一个简单的单层神经网络,来解决手写数字识别问题。

问题介绍
在人工智能飞速发展之前,手写数字识别问题困扰了人们很久,传统的算法很难解决这类问题,因此,人工智能应运而生。本文将使用Mnist提供的数据,使用Kaggle网站的测试数据并进行在线测试准确率。
原理介绍
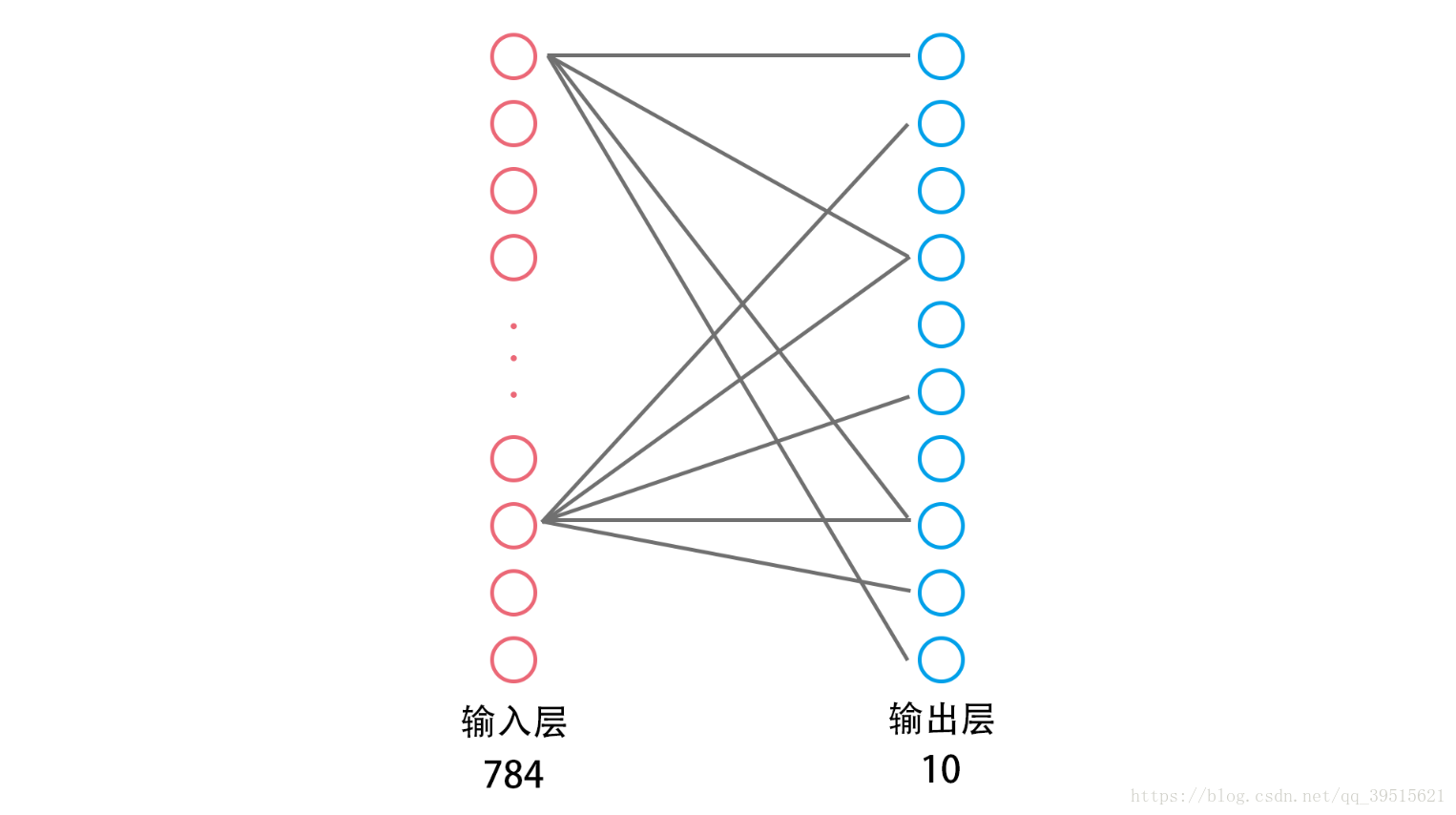
下图展示了一个简单的单层神经网络示意图,只有输入层和输出层。Mnist提供的数据是28*28的图片,我们可以将其视为一个784维的向量,每一维表示相应的位置上的像素的灰度值,因此输入层包含784个神经元。所有的数字只有0,1,2,3,4,5,6,7,8,9这10个,因此输出层包含10个神经元。
神经网络的作用就是根据某种算法,根据输入的一个784维向量,计算并输出一个10维向量,根据这个10维向量即可得知输入的手写数字是多少。这个所谓的“某种算法”用数学语言表示就是
或简单记为
其中 N N 是输出层的10维向量,若其中 为最大值,则判断该数字为 i−1 i − 1 , P P 是输入层的数据,对应图片每个位置上像素的灰度值, 是权值矩阵, B B 是偏置矩阵
是激活函数,用于将模型的结果从线性转化为非线性,常见的激活函数有
神经网络的训练过程,就是根据大量有标签的数据组成的 N N 和 ,计算得出合适的 W W 和 ,那么对于没有标签的测试数据 P P ,即可根据 和 B B 计算相应的 。
在训练过程中,为了衡量当前状态与训练目标的距离,我们引入交叉熵的概念,详细内容请参考
https://en.wikipedia.org/wiki/Cross_entropy ,损失函数可取交叉熵的平均值,使用梯度下降法调整
W
W
和 的值。
用TensorFlow实现算法
在Kaggle(https://www.kaggle.com/c/digit-recognizer)上下载相应的数据集train.csv和test.csv,并在计算机上搭建好TensorFlow的环境.
1. 加载训练数据集
train = pd.read_csv("train.csv")
images = train.iloc[:,1:].values
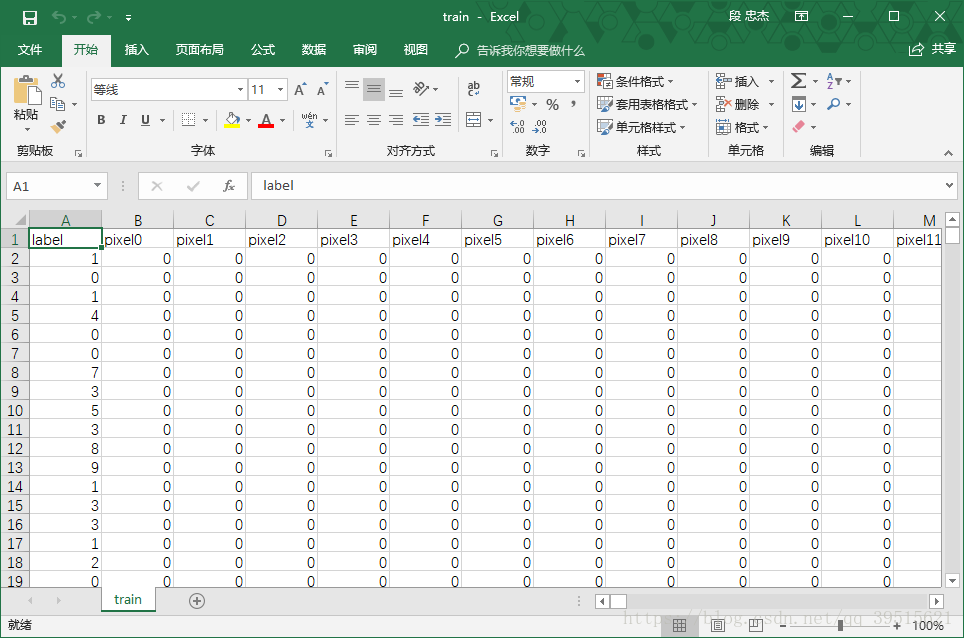
labels_flat = train.iloc[:,0].values.ravel()Kaggle网站提供的训练数据格式如下所示,第一列为标签,第2~785列为灰度值数据,每一行对应一个含标签的数字,共42000组数据。
2. 对输入进行预处理
images = images.astype(np.float)
images = np.multiply(images, 1.0 / 255.0)
image_size = images.shape[1]
image_width = image_height = np.ceil(np.sqrt(image_size)).astype(np.uint8)
x = tf.placeholder('float', shape=[None, image_size])这一步是将取值范围为[0,255]的灰度值转化为浮点小数,并映射到[0,1]上。
3. 对标签进行预处理
labels_count = 10
# 进行One-hot编码
def dense_to_one_hot(labels_dense, num_classes):
num_labels = labels_dense.shape[0]
index_offset = np.arange(num_labels) * num_classes
labels_one_hot = np.zeros((num_labels, num_classes))
labels_one_hot.flat[index_offset + labels_dense.ravel()] = 1
return labels_one_hot
labels = dense_to_one_hot(labels_flat, labels_count)
labels = labels.astype(np.uint8)
y = tf.placeholder('float', shape=[None, labels_count])进行One-hot编码的目的是将标签这种定性特征转化为定量特征,例如将数字标签3转化为向量
4. 把输入数据划分成训练集和验证集
# 把40000个数据作为训练集,2000个数据作为验证集
VALIDATION_SIZE = 2000
validation_images = images[:VALIDATION_SIZE]
validation_labels = labels[:VALIDATION_SIZE]
train_images = images[VALIDATION_SIZE:]
train_labels = labels[VALIDATION_SIZE:]划分出验证集是为了在训练过程中检验准确率,便于监督
5. 对训练集进行分批
batch_size = 100
n_batch = int(len(train_images)/batch_size)每批使用100个手写数字的数据进行训练,如果每次都只用一个数据进行训练的话,训练过程将会变得缓慢,用多个数据进行训练的话,TensorFlow会对矩阵乘法进行优化,与单个数据相比效率更高,但如果每批的数据量过大的话,将会占用较大内存造成过量的计算负担。
6. 创建一个简单的神经网络用来对图片进行识别
weights = tf.Variable(tf.zeros([784,10]))
biases = tf.Variable(tf.zeros([10]))
result = tf.matmul(x,weights)+biases
prediction = tf.nn.softmax(result)本文使用softmax作为激活函数
由于TensorFlow语法的特殊性,上述过程将在后面代码中在tf.Session()中调用执行,下同。
7. 创建损失函数
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels = y, logits =prediction ))本文以交叉熵的平均值作为损失函数
8. 用梯度下降法优化参数
train_step = tf.train.GradientDescentOptimizer(0.1).minimize(loss)9. 初始化变量
init = tf.global_variables_initializer()10. 计算准确率
correct_prediction = tf.equal(tf.argmax(y,1),tf.argmax(prediction,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction,tf.float32))11. 加载测试数据并进行预处理
test = pd.read_csv("test.csv");
test_images = test.iloc[:,:].values
test_images = test_images.astype(np.float)
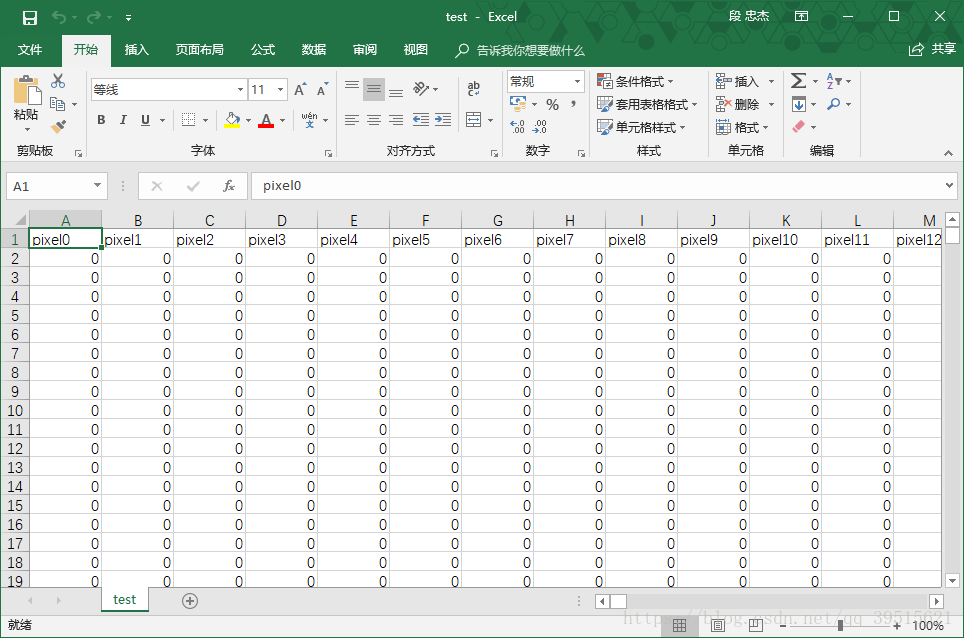
test_images = np.multiply(test_images, 1.0 / 255.0)测试数据与训练数据类似,只是少了标签。
12. 预测测试数据
test_prediction = tf.argmax(prediction,1)13. 进行训练和预测
with tf.Session() as sess:
#初始化
sess.run(init)
#训练
for epoch in range(100):
#分批取出数据
for batch in range(n_batch):
batch_x = train_images[batch*batch_size:(batch+1)*batch_size]
batch_y = train_labels[batch*batch_size:(batch+1)*batch_size]
#进行训练
sess.run(train_step,feed_dict = {x:batch_x,y:batch_y})
#每一轮计算一次准确度
accuracy_n = sess.run(accuracy,feed_dict={ x: validation_images, y: validation_labels})
#输出准确度便于监督
print ("第" + str(epoch+1)+"轮,准确度为:"+str(accuracy_n))
#对测试数据进行预测
test_label = sess.run(test_prediction,feed_dict={ x: test_images})
ImageId = list(range(1,test_images.shape[0]+1))
save = pd.DataFrame({'ImageId':ImageId,'Label':test_label})
save.to_csv('submission.csv',index=False,sep=',')运行结果
第1轮,准确度为:0.7925
第2轮,准确度为:0.808
第3轮,准确度为:0.8155
第4轮,准确度为:0.8535
第5轮,准确度为:0.876
...
第96轮,准确度为:0.922
第97轮,准确度为:0.922
第98轮,准确度为:0.922
第99轮,准确度为:0.922
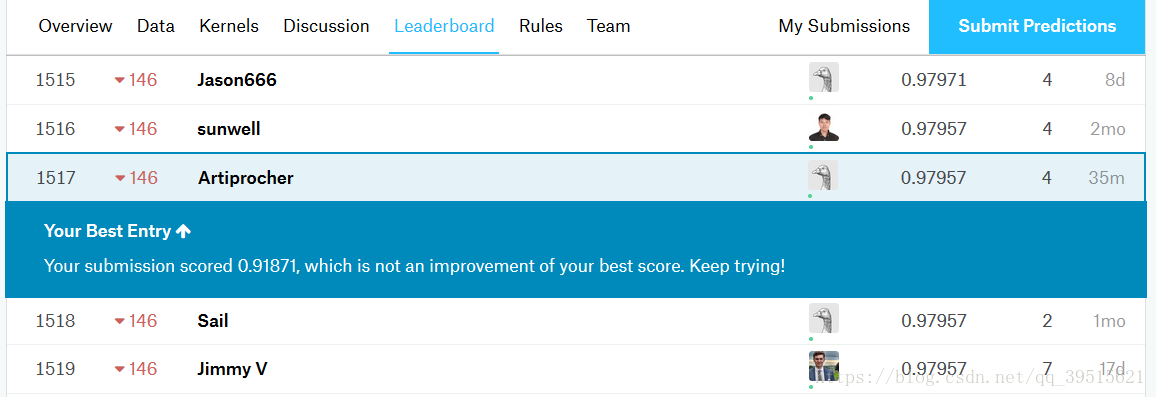
第100轮,准确度为:0.922由于时间原因,我们仅训练了100轮,在Kaggle上得到的准确率为91.871%。
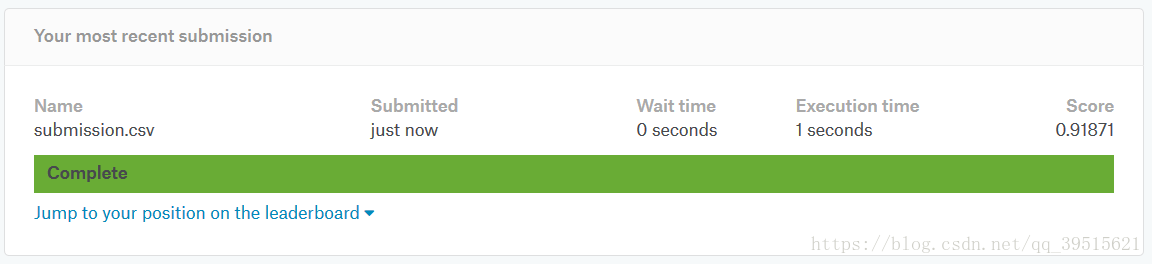
实际上,适当地在输入层和输出层之间增加隐含层和增加训练次数,可以提高准确率,如果要大幅度提高准确率,可以使用卷积神经网络。
使用卷积神经网络优化过的模型可以达到97.957%的准确率,本文对此不做过多介绍。
附录(完整版代码)
import numpy as np
import tensorflow as tf
import pandas as pd
#1 加载数据集,把对输入和结果进行分开
train = pd.read_csv("train.csv")
images = train.iloc[:,1:].values
labels_flat = train.iloc[:,0].values.ravel()
#2 对输入进行预处理
images = images.astype(np.float)
images = np.multiply(images, 1.0 / 255.0)
image_size = images.shape[1]
image_width = image_height = np.ceil(np.sqrt(image_size)).astype(np.uint8)
x = tf.placeholder('float', shape=[None, image_size])
#3 对结果进行处理
labels_count = 10
# 进行One-hot编码
def dense_to_one_hot(labels_dense, num_classes):
num_labels = labels_dense.shape[0]
index_offset = np.arange(num_labels) * num_classes
labels_one_hot = np.zeros((num_labels, num_classes))
labels_one_hot.flat[index_offset + labels_dense.ravel()] = 1
return labels_one_hot
labels = dense_to_one_hot(labels_flat, labels_count)
labels = labels.astype(np.uint8)
y = tf.placeholder('float', shape=[None, labels_count])
#4 把输入数据划分训练集和验证集
# 把40000个数据作为训练集,2000个数据作为验证集
VALIDATION_SIZE = 2000
validation_images = images[:VALIDATION_SIZE]
validation_labels = labels[:VALIDATION_SIZE]
train_images = images[VALIDATION_SIZE:]
train_labels = labels[VALIDATION_SIZE:]
#5 对训练集进行分批
batch_size = 100
n_batch = int(len(train_images)/batch_size)
#6 创建一个简单的神经网络用来对图片进行识别
weights = tf.Variable(tf.zeros([784,10]))
biases = tf.Variable(tf.zeros([10]))
result = tf.matmul(x,weights)+biases
prediction = tf.nn.softmax(result)
#7 创建损失函数,以交叉熵的平均值为衡量
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels = y, logits =prediction ))
#8 用梯度下降法优化参数
train_step = tf.train.GradientDescentOptimizer(0.1).minimize(loss)
#9 初始化变量
init = tf.global_variables_initializer()
#10 计算准确度
correct_prediction = tf.equal(tf.argmax(y,1),tf.argmax(prediction,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction,tf.float32))
#11 加载测试数据
test = pd.read_csv("test.csv");
test_images = test.iloc[:,:].values
test_images = test_images.astype(np.float)
test_images = np.multiply(test_images, 1.0 / 255.0)
#12 预测测试数据
test_prediction = tf.argmax(prediction,1)
with tf.Session() as sess:
#初始化
sess.run(init)
#训练
for epoch in range(100):
#分批取出数据
for batch in range(n_batch):
batch_x = train_images[batch*batch_size:(batch+1)*batch_size]
batch_y = train_labels[batch*batch_size:(batch+1)*batch_size]
#进行训练
sess.run(train_step,feed_dict = {x:batch_x,y:batch_y})
#每一轮计算一次准确度
accuracy_n = sess.run(accuracy,feed_dict={ x: validation_images, y: validation_labels})
#输出准确度便于监督
print ("第" + str(epoch+1)+"轮,准确度为:"+str(accuracy_n))
#对测试数据进行预测
test_label = sess.run(test_prediction,feed_dict={ x: test_images})
ImageId = list(range(1,test_images.shape[0]+1))
save = pd.DataFrame({'ImageId':ImageId,'Label':test_label})
save.to_csv('submission.csv',index=False,sep=',')最后
以上就是欣慰鸡翅最近收集整理的关于手写数字识别------用TensorFlow实现简单的单层神经网络 手写数字识别 ——用TensorFlow实现简单的单层神经网络 的全部内容,更多相关手写数字识别------用TensorFlow实现简单的单层神经网络 内容请搜索靠谱客的其他文章。








发表评论 取消回复