前言
最近笔者在好奇如何从最底层开始搭建一个深度学习系统,之前都是采用现成的成熟深度学习框架,比如PyTorch,TensorFlow等进行模型的搭建,对底层原理了解不是特别深刻。因此笔者最近在阅读darknet的源码,希望能从中学习到一些底层的知识,本文主要是对darknet中常见的数据结构进行记录和分析。如有谬误请联系指出,转载请联系作者并注明出处,谢谢。
∇ nabla ∇ 联系方式:
e-mail: FesianXu@gmail.com
QQ: 973926198
github: https://github.com/FesianXu
知乎专栏: 计算机视觉/计算机图形理论与应用
微信公众号: 
DarkNet
darknet [1]是一个纯由C语言编码而成的轻量级深度学习框架,在最小运行状态下(即是不使用GPU,不使用多线程和opencv)时,可以实现无外部库依赖实现深度学习建模,训练,测试等基础功能。如果从caffe,pytorch,tensorflow等大型深度学习库开始去研究底层,因为代码结构复杂,而且依赖项太多,使得入门者望而却步,由于darknet可以在无依赖的情况下运行,因此是研究深度学习框架底层代码的一个很好的资源。
darknet中定义了很多必要的数据结构去表示网络结构,网络层结构等,这些数据结构为网络配置解析提供了方便,是阅读源码过程中必不可少的,本文主要分析darknet中主要的数据结构。
数据结构
为了解析方便而定义的数据结构
类似于在caffe中利用prototxt文件去表示一个网络的结构,每一层的超参数以及整个网络的超参数(例如学习率,优化器参数等),在darknet中采用了cfg文件去配置网络的这一切参数,可以视为是简单版本的prototxt文件,以下以resnet18.cfg为例子,截取了其中的头尾部分的cfg片段:
[net]
# Training
# batch=128
# subdivisions=1
# Testing
batch=1
subdivisions=1
height=256
width=256
channels=3
min_crop=128
max_crop=448
burn_in=1000
learning_rate=0.1
policy=poly
power=4
max_batches=800000
momentum=0.9
decay=0.0005
...
[convolutional]
batch_normalize=1
filters=64
size=7
stride=2
pad=1
activation=leaky
[maxpool]
size=2
stride=2
...
[convolutional]
filters=1000
size=1
stride=1
pad=1
activation=linear
[softmax]
groups=1
其中每一个[xxx]代表一个片区(section),通常表示的是一个 层(layer)。其中的第一个片区[net]或者[network]是表示该网络的基本参数,比如图片长度,高度通道数,batch_size,学习率,优化器参数等。每个配置文件必须以[net]起始。
为了解析该文本配置文件的方便,我们需要用一种数据结构将整个网络配置串联起来,最理想的莫过于是 链表(linked list) 了,其中链表中的每个元素都是一个片区,该链表的数据结构定义如下,为了更好地组织数据,定义的是双向链表,因此每个节点node都有前项prev和后继next节点指针,当然还有内容负载指针 void* val。
typedef struct node{
void *val; // 节点内容负载
struct node *next;
struct node *prev;
} node;
typedef struct list{
int size;
node *front; // 双向链表头结点
node *back; // 双向链表尾节点
} list;
因此可视化出来Fig 1所示,其中的负载既可以是section,也可以是其他元素,比如key-val(键值)对,此处暂时以section为例子。

其中每个section都是神经网络的一个层(除了第一个section,第一个是特殊的[net]参数组),section的数据结构定义如code 3所示,其中的char* type表示该层的名字,比如[convolutional],[avgpool]等;其中的list* options表示的是该层中的每一个参数的 键值对(key-val pair, kvp),每一个键值对都是该层的一个具体参数,比如[convolutional]的stride=1就表示其步进长度,我们需要用一个键值对数据结构进行表示,如code 4所示。
typedef struct{
char *type;
list *options;
}section;
typedef struct{
char *key; // 索引键
char *val; // 对应值
int used; // 是否被使用
} kvp;
如Fig 2所示,当考虑到每个section内的参数kvp之后,我们有新的"链表套链表"的结构,采用该结构就足以表达整个网络的层次与参数了。
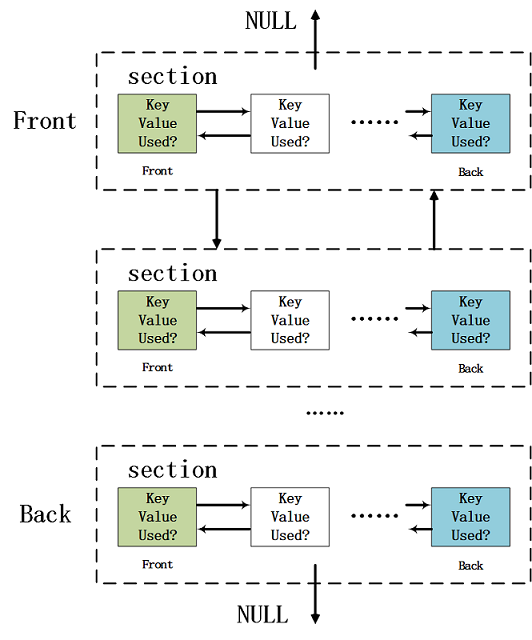
网络结构的数据结构
之前谈到的数据结构是为了解析cfg文件方便而定义的,考虑到网络的计算(包括前向和后向计算),参数保存等,我们还需要一些其他数据结构,这些数据结构可以基于解析得到的双向网络配置链表,初始化整个神经网络的参数和结构。这些数据结构中,最重要的莫过于layer和network,这两个结构体都在/include/darknet.h中定义。
layer的数据结构定义如code 5所示(省略掉了很多元素以便于展示,具体定义见[2]),我们发现这个定义中有着非常多的元素(其实我还省略掉了一些和GPU计算有关的元素,因为在本文中假设只使用CPU进行计算,这样又便于我们分析整体代码的结构。),其中元素那么多的原因在于,作者采用的纯C语言的编写方式,没办法直接采用C++的面向对象的思想设计代码,这意味着不能通过继承的方式,设置一个layer父类,然后不同的convolution_layer,rnn_layer,crnn_layer,cost_layer,connected_layer等子类继承这个共有的父类,因为不同子类(也就是不同层)的参数类别千差万别,因此可以做到比较好的隔离。然而,C语言是面向过程编程的,因此作者设计的layer类就必须包括该框架中需要的所有层的所有参数类别,这使得该数据结构异常的臃肿,而且难以扩展,定制其他层。不过暂且不讨论这些缺点,我们先看看该层中有哪些参数需要注意的吧。
struct layer{
LAYER_TYPE type;
ACTIVATION activation;
COST_TYPE cost_type;
void (*forward) (struct layer, struct network);
void (*backward) (struct layer, struct network);
void (*update) (struct layer, update_args);
int batch_normalize;
int shortcut;
int batch;
int forced;
int flipped;
int inputs;
int outputs;
int nweights;
int nbiases;
int extra;
...
struct layer *wo;
struct layer *uf;
struct layer *wf;
struct layer *ui;
struct layer *wi;
struct layer *ug;
struct layer *wg;
tree *softmax_tree;
size_t workspace_size;
};
第一个元素LAYER_TYPE是一个枚举类型,用于指定该层的类型;第二个元素ACTIVATION也是一个枚举类型,指定激活函数类型;第三个元素COST_TYPE同样是枚举类型,指定损失函数类型。5-7行的三个函数指针(函数指针是指向函数的指针变量,即本质是一个指针变量)比较特别,是指的该层的前向传播计算细节void (*forward)(struct layer, struct network);,该层的反向传播计算细节void (*backward)(struct layer, struct network);,以及模型训练过程中的参数更新策略void (*update)(struct layer, update_args);。这些函数指针都需要根据特定的具体层进行特别指定,因此是一种回调函数,需要指定层进行特定的回调函数注册。大部分神经网络层都会有其特有的参数,比如卷积层的其中一些参数示例,其中以指针形式出现的参数都是需要学习的(也需要初始化),以其他参数大多数都是超参数:
float * weights; // 卷积权值
float * biases; // 偏置
int nweights; // 权值参数量
int nbiases; // 偏置参数量
int groups; // 组可分离卷积的组数
int stride; // 步进
int pad; // 填充大小
...
还有些参数是每个层都共用的,比如输入指针,输出指针等:
int * input_layers; // 该层的上一层,也即是输入层
int * input_sizes;
float * output; // 该层的输出
...
当然,layer数据结构还有很多其他元素,比如batch_normalize是否运行batch_norm[3],是否该层存在shortcut等,注意到因为darknet是为了yolo系列网络[4,5,6]专门设计的框架,因此layer中还有很多元素是和yolo网络有关的,这点不再进一步阐述,我们只关注通用的神经网络底层需要的元素。
这个只是一个神经网络层的数据结构定义而已,为了表示整个神经网络结构,还需要定义一个network数据结构,如code 6所示,该数据结构储存有定义整个网络必须的元素,比如batch size大小,epoch大小,每一层的定义layer* layers,学习率更新策略,学习率,动量等等。我们需要做的就是利用解析好的网络配置链表,基于network数据结构去初始化该数据结构,通过这个数据结构就可以表示整个网络,而且具备有计算,梯度传导,参数更新等功能,可以视为是一个完整的单元了。
typedef struct network{
int n; // 网络中层的数量
int batch; // 批次大小
size_t *seen; // 已经有多少图片被处理过了
int *t; // ?
float epoch; // 世代大小
int subdivisions; // 子划分
layer *layers; // 每一个层的定义
float *output; // 输出
learning_rate_policy policy; // 学习率更新策略
float learning_rate; // 学习率
float momentum; // SGD动量大小
float decay; // L2正则衰减系数
float gamma;
float scale;
float power;
int time_steps;
int step;
int max_batches;
float *scales;
int *steps;
int num_steps;
int burn_in;
// 和adam优化器相关的参数
int adam;
float B1;
float B2;
float eps;
// 输入输出的维度
int inputs;
int outputs;
// ground truth的维度
int truths;
int notruth;
int h, w, c;
int max_crop;
int min_crop;
float max_ratio;
float min_ratio;
int center;
float angle;
float aspect;
float exposure;
float saturation;
float hue;
int random;
// darknet对于每个GPU都维护着同一个网络network,每个network通过gpu_index进行区分
int gpu_index;
tree *hierarchy;
// 中间变量,用于临时存储某一层的输入,包括一个批次的输入,用于完成前向和反向传播。
float *input;
// 中间变量,和上面的输入是对应的,用于临时储存对应的标签数据。
float *truth;
// delta用于梯度传播,也是一个临时变量,用于临时储存某个层的sensitivity map。在反向传播的时候,当经过当前层的时候,需要储存之前层的sensitivity map。我们会后续讨论。
float *delta;
// workspace 是公共的运行空间,用于纪录所有层中需要的最大计算内容空间,其大小为workspace_size。因为在GPU或者CPU中,同一时间只有一个层在运行,因此保存所有层中最大的需求即可。net.workspace用于储存feature特征。
float *workspace;
// 这个标识参数用于判断网络是否处于训练状态,如果是,这个值为1。在一些操作中,比如dropout层,forward_dropout_layer()只在训练阶段才会被采用。
int train;
// 标识参数,指明了当前网络的活跃(active)层
int index;
// 每一层的loss,只有[yolo]层才会有值。
float *cost;
float clip;
} network;
从code 6中,备注了大部分参数的含义,其中需要解释的是subdivisions,子划分[7]的作用是对batch size进行进一步的划分,以便于某些小显存的GPU也能够运行程序。例如本身设置的batch size = 64,如果GPU显存过小,不能负担大的batch size,那么通过设置subdivisions = 8,可以将一个批次分为8次完成(当然,梯度是会累积的,类似于[8]的操作),因此一个mini batch size = 64/8 = 8了,此时GPU显存就可以装得下了。
还有一个元素需要解释的就是float *workspace,该指针变量开辟了一大段float类型的内存空间,用于作为当前的运行环境。我们之后在讨论如何解析darknet的cfg配置文件的时候,会讨论如何确定这个workspace的空间大小。因为不管什么时候(不考虑多模型多设备并行),GPU或者CPU中只有模型的某一层在运行,因此只要求得所有层中的最大内存要求,然后根据这个内存要求开辟一个内存池用于作为模型的工作空间就足够了。因此不管是模型的哪个层,其特征feature都储存在了workspace。我们后续再继续讨论这个元素,目前知道它是一个公共内存空间即可。
其他类型的数据结构
以上提到的数据结构是为了解析网络配置,定义与初始化网络结构而设计的,有些数据结构则是为了作为喂入数据的容器而存在的,类似于pytorch中的tensor,不过tensor结构是自带梯度的,而darknet的只是为了喂数据而已,没有梯度信息,darknet的梯度流信息储存在了network中。
最基本的单元就是matrix,指定了行列数和一个二阶的单浮点指针表示数据负载,如code 7所示。
typedef struct matrix{
int rows, cols;
float **vals;
} matrix;
其中每一行是一个样本,每一列是一个特征维度,如果是图片样本,那需要把图片拉直成向量之后,塞到每一行。这个matrix既可以表示训练样本数据,也可以表示标签数据,因此有data数据结构。
typedef struct{
int w, h;
matrix X;
matrix y;
int shallow;
int *num_boxes;
box **boxes;
} data;
正如之前所述的,darknet为yolo量身定制,是进行目标识别任务的,因此data中会出现和目标检测有关的包围盒box** boxes等数据。
总结
总得来说,darknet的常见数据类型主要有以下几种:
- 解析配置文件时候的辅助数据结构:
node,list,kvp,section。 - 构建网络时候的数据结构:
layer,network。 - 数据管道的数据结构:
matrix,data,metadata,box_label,box,data_type,image,IMTYPE,detection。 - 网络相关,训练过程中的数据结构:
learning_rate_policy,ACTIVATION,BINARY_ACTIVATION,COST_TYPE,LAYER_TYPE,update_args。 - 暂时不知道拿来干啥用的数据结构:
tree。
声明
该系列博客仍处在开发中,笔者还没完全通读完darknet,目前处在笔记阶段,可能会有所谬误,因此会随时存在更正更新,如有错误也欢迎各位读者朋友在评论区指出。
Reference
[1]. https://pjreddie.com/darknet/
[2]. https://github.com/pjreddie/darknet/blob/4a03d405982aa1e1e911eac42b0ffce29cc8c8ef/include/darknet.h#L115
[3]. https://fesian.blog.csdn.net/article/details/86476010
[4]. Redmon, J., Divvala, S., Girshick, R., & Farhadi, A. (2016). You only look once: Unified, real-time object detection. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 779-788).
[5]. Redmon, J., & Farhadi, A. (2017). YOLO9000: better, faster, stronger. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 7263-7271).
[6]. Redmon, J., & Farhadi, A. (2018). Yolov3: An incremental improvement. arXiv preprint arXiv:1804.02767.
[7]. https://github.com/pjreddie/darknet/issues/224#issuecomment-335771840
[8]. https://blog.csdn.net/LoseInVain/article/details/82916163
最后
以上就是有魅力皮带最近收集整理的关于[darknet源码系列-1] darknet源码中的常见数据结构前言DarkNet数据结构总结声明Reference的全部内容,更多相关[darknet源码系列-1]内容请搜索靠谱客的其他文章。




![[darknet源码系列-1] darknet源码中的常见数据结构前言DarkNet数据结构总结声明Reference](https://www.shuijiaxian.com/files_image/reation/bcimg13.png)



发表评论 取消回复