排列熵算法(Permutation Entropy PE)
出发点:用于脑电信号的信号判别,提取该排列熵特征,以区分不同的类
其它突变信号检测方法:

总结:
1、傅里叶变换在全局上提供了信号整体奇异性的描述, 无法指出局部对整体奇异性的贡献, 因此无法定位突变发生的具体时刻
2、短时傅里叶变换在给定的时间间隔和频率间隔内效果比较明显, 但对所有的频率都使用单一的窗函数, 分辨率保持不变,因此, 一旦窗口函数选定,则窗口的形状和大小保持不变,对短时高频信息不能细化到任意小的局部时间, 不能敏感地反映信号的突变
3、小波分析能够满足不同频率的要求,具有较好的自适应性,适合于对突变信号或具有孤立奇异性信号的处理, 但在利用小波
变换来检测信号的突变点过程中, 小波变换系数的选择、所选用的小波函数、噪声干扰等方面都会对检测结果有一定的影响
同类方法:
LyaPullov 指数(最大李亚普诺夫指数)、分形维数(系统的混沌性)、 复杂度和近似熵
参考:基于脑电 α 波的非线性参数人体疲劳状态判定
排列熵算法原理:
1)信号的相空间重构(类似于单通道信号构造嵌入矩阵,用于PCA的降维)
条件:
时间序列x(i) i=1,2,.......,n
m:嵌入维数
t:延时时间
k为重构分量,k=n-(m-1)*t
重构的空间:
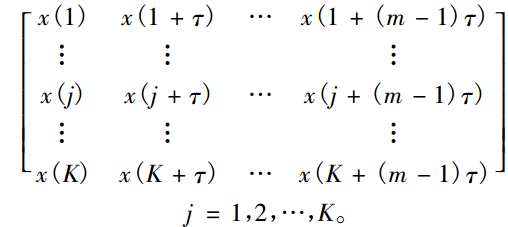
其中有k个重构分量
2)提取符号序列
将重构矩阵中的第j个重构分量,按照数值大小升序排列,所得到的排序的索引值构成一组符号序列S
m列的重构矩阵,也即是m维如果按照(1,2....m)的不同排列总共有全排列m!个符号序列
3)统计k个重构分量对应的每种排列在m!全排列中出现的次数
该次数用于后续的符号序列的概率,每一列对应的次数/该列总共的次数得到每个对应位置的概率如:
因此对应于全排列有m!列,每列对应位置出现的概率为 P1,P2,…,P
4)计算排列熵
k表示k种不同的符号序列,k ≤ m!
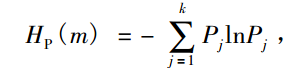
5)归一化处理
![]()
其中:![]()
说明:Hp的值表示时间序列的随机程度,Hp越小,时间序列越规则,否则越随机
代码:
matlab2019a版本:
function [pe hist] = pec(y,m,t)
% Calculate the permutation entropy
% Input: y: time series;
% m: order of permuation entropy
% t: delay time of permuation entropy,
% Output:
% pe: permuation entropy
% hist: the histogram for the order distribution
%Ref: G Ouyang, J Li, X Liu, X Li, Dynamic Characteristics of Absence EEG Recordings with Multiscale Permutation % % Entropy Analysis, Epilepsy Research, doi: 10.1016/j.eplepsyres.2012.11.003
% X Li, G Ouyang, D Richards, Predictability analysis of absence seizures with permutation entropy, Epilepsy % % Research, Vol. 77pp. 70-74, 2007
% revised by heda3
ly = length(y);
permlist = perms(1:m);%全排列m!
c(1:length(permlist))=0;%
for j=1:ly-t*(m-1)%K=n-(m-1)*t 有k个重构分量
[a,iv]=sort(y(j:t:j+t*(m-1)));%按照数值大小升序排列 iv索引值 a为排序后的数值
for jj=1:length(permlist)%m!
if (abs(permlist(jj,:)-iv'))==0% iv可看做得到的符号序列
c(jj) = c(jj) + 1 ;%累计每种排列对应m!中出现的次数
end
end
end
hist = c;
c=c(find(c~=0));%找出非零元素索索引值对应的数值
p = c/sum(c);%计算每一种符号序列出现的概率
pe = -sum(p .* log(p));%shannon熵的形式关于参数的选择:
序列长度、嵌入维数和延迟时间
其中m和t
可参考:


1)m选择过大计算复杂度高,过低则无效,而关于延迟时间的选取要求大于等于1
2)还可以采用自动参数搜索的方法进行多参数的排列组合选取
3)或者:结合遗传算法、粒子群算法等优化算法和相空间重构方法进行参数的自适应选择!
应用:

参考文献:
【1】冯辅周,饶国强,司爱威, 等.排列熵算法的应用与发展[J].装甲兵工程学院学报,2012,26(2):34-38. DOI:10.3969/j.issn.1672-1497.2012.02.007.
【2】排列熵(permutation entropy) 排列熵(permutation entropy)_马弄一下的博客-CSDN博客_排列熵
【3】Detecting dynamical changes in time series using the permutation entropy
DOI: 10.1103/PhysRevE.70.046217
最后
以上就是有魅力皮带最近收集整理的关于排列熵算法--用于时间序列信号的复杂度检测的全部内容,更多相关排列熵算法--用于时间序列信号内容请搜索靠谱客的其他文章。








发表评论 取消回复