shuffle和排序
Shuffle阶段分为两部分:Map端和Reduce端。
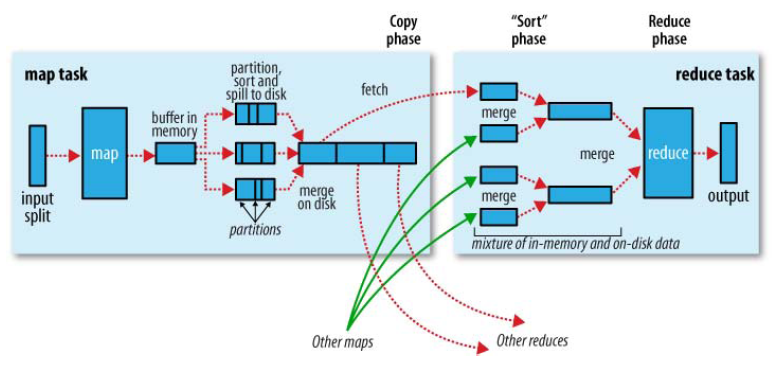
一 map端shuffle过程;
1-
内存预排序:默认每个map有100M内存进行预排序(为了效率),超过阈值,会把内容写到磁盘;
此过程使用
快速排序算法;
2-根据key和reducer的数量进行
分区和排序;首先根据数据所属的
Partition排序,然后每个Partition中再按Key排序;
此过程排序默认使用
归并排序算法;
3-
combiner,使得map的输出结果更紧凑,减少磁盘写入和传输的数据量。慎用,可能会对结果产生错误的结果;如果存在combiner阶段;
4-一个Map任务会产生多个spill文件,在Map任务完成前,所有的spill文件将会归并排序为一个索引文件和数据文件。当spill文件归并完成后,Map将删除所有的临时文件,并告知TaskTracker任务已完成。
二 reduce的shuffle阶段
1-
copy阶段:Reduce端通过HTTP获取Map端的数据,只要有一个map任务完成,Reduce任务就开始复制它的输出。JobTracker知道Map输出与TaskTracker的映射关系,Reduce端有一个线程间歇地向JobTracker询问Map输出的地址,直到把所有的数据都获取到。
2-排序阶段,又称
合并阶段。将多个已经排序的文件合并成一个文件。Merge有三种形式:内存到内存,内存到磁盘,磁盘到磁盘。
此过程
顺序比较插入排序算法,可能都不叫算法。只是对多个已排序文件合并成一个文件。
转载于:https://www.cnblogs.com/parent-absent-son/p/9919241.html
最后
以上就是热情大门最近收集整理的关于hadoop的shuffle和排序的全部内容,更多相关hadoop内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复