数据分析基本概念
- 明确思路→数据收集《分布式爬虫实战》→数据处理→数据分析→数据展现
- 常用的收集途径: 公开信息,外部数据库,自有数据库,调查问卷,客户数据
- 数据清洗: 可读性,完整性,唯一性,权威性及合法性
- 常见的数据类型
1,类别型数据 (1)取值种类 (2)每类取值的分布
2,数值型变量 (1)极值和分位点 (2)均值和标准差 (3)变量间相关性
3,通用数据描述 (1)缺失值 (2)重复性
Python3新特性
字符串格式化输出
新增format()方式
- 基本语法是通过 {} 和 : 来代替以前的 %

dict类型变化
删除之前的iterkeys(),itervalues(),iteritems() 改为keys(),values(),items().
NumPy(Numerical Python)
NumPy 是一个运行速度非常快的数学库,主要用于数组计算,包含:
1,高性能科学计算和数据分析的基础包,提供多维数组对象
2,ndarray,多维数组(矩阵),具有矢量计算能力,快速节省空间
3,矩阵运算,无需循环,可完成类似matlab中的矢量计算
4,线性代数,随机数生成
5,广播功能函数
6,整合 C/C++/Fortran 代码的工具
- import numpy as np
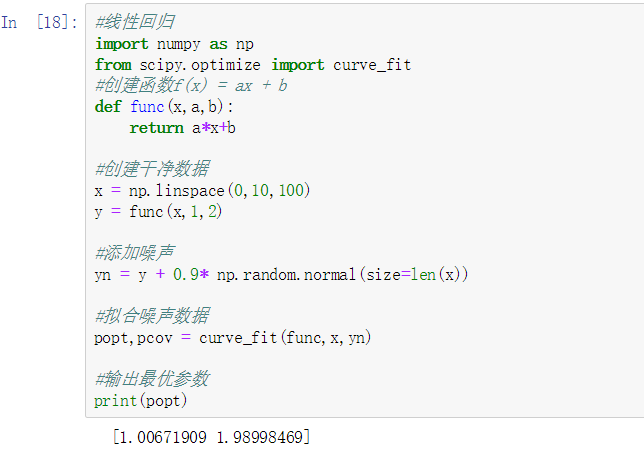
SciPy
1,在NnmPy库的基础上增加了众多的数学,科学及工程常用的库函数
2,线性代数,常微分方程求解,信号处理,图像处理,稀疏矩阵
3,import scipy as sp
Ndarry,N维数组对象
所有元素必须是相同类型
ndim属性,维度个数
# 最小维度
import numpy as np
a = np.array([1, 2, 3,4,5], ndmin = 2)
print (a)
shape属性,各维度大小
dtype属性,数据类型
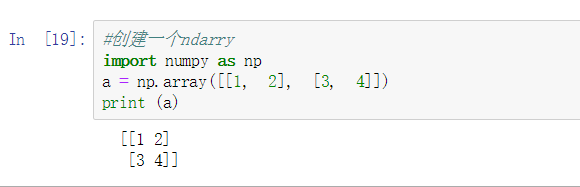
#创建一个ndarry
import numpy as np
a = np.array([[1, 2], [3, 4]])
print (a.dtype)
out: int 32
创建ndarry
np.array(collection),collection为序列型对象(list).嵌套序列(list of list)
np,zeros,np.ones,np.empty指定大小的全0或者全1数组
注意:第一个参数是元祖,用来指定大小,如(3,4)
empty不是总是返回全0,有时返回的是未初始的随机值
索引与切片
一维数组的索引与python的列表索引功能相似
import numpy as np
a = np.arange(10)
s = slice(2,7,2) # 从索引 2 开始到索引 7 停止,间隔为2
print (a[s])
out: [2 4 6]
多维数组的索引
arr[r1:r2,c1:c2]
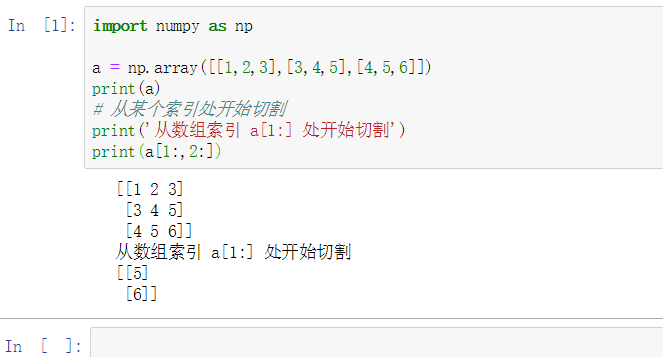
import numpy as np
a = np.array([[1,2,3],[3,4,5],[4,5,6]])
print(a)
# 从某个索引处开始切割
print('从数组索引 a[1:] 处开始切割')
print(a[1:])
arr[1,1]等价arr[1][1]
[:]代表某个维度的数据
使用负数索引将会从末尾开始选取行
条件索引
不耳坠多维数组 arr[condition] condition 可以是多个条件组合
注意,多个条件组合要使用 & | ,而不是and or
二维数组切片
创建一个二维数组
arr = np.array([[1,2,3,4],[5,6,7,8],[9,10,11,12]])
print(arr)
多维数组可以按照维度分为多个轴,以二维数组为例,第一维可以用第0轴“axis=0”表示,第二维可以用第1轴“axis=1”表示
| 0 | 1 | 2 | 3 | |
|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 |
| 1 | 5 | 6 | 7 | 8 |
| 2 | 9 | 10 | 11 | 12 |
#沿着axis=0轴方向的切片
arr[:2]
结果:array([[1, 2, 3, 4],
[5, 6, 7, 8]])
维数转换
转置
#转置,数组转置可以使用transpose方法或者T属性,转置返回的是源数组的视图,不会进行任何复制操作
#reshape(shape)函数改变数组形状,
shape是一个元组,表示数组的形状
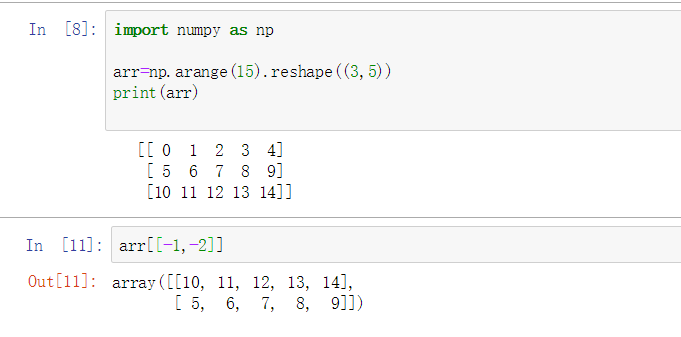
arr = np.arange(15).reshape((3,5))
print(arr)
out: :[[ 0 1 2 3 4]
[ 5 6 7 8 9]
[10 11 12 13 14]]
arr.transpose() #也可以写成 arr.T
out:array([[ 0, 5, 10],
[ 1, 6, 11],
[ 2, 7, 12],
[ 3, 8, 13],
[ 4, 9, 14]])
矢量版本的三元表达式: x if condition else y
np.where(condition,x,y)
常用的统计方法
np.mean, np.sum,
np.max, np.min
np,std, np.var
np.argmax, np.argmin
#求和
使用sum函数对数组中全部或者某轴向的元素求和
#数组中全部元素求和
arr1 = np.array([[1,2,3],[4,5,6]]) # 2行3列二维数组
arr1.sum()
out:21
#沿着第0轴方向求和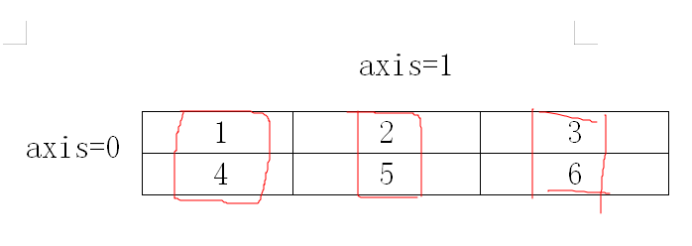
arr1.sum(axis=0) #简写arr1.sum(0)
结果:array([5, 7, 9])
#沿着第1轴方向求和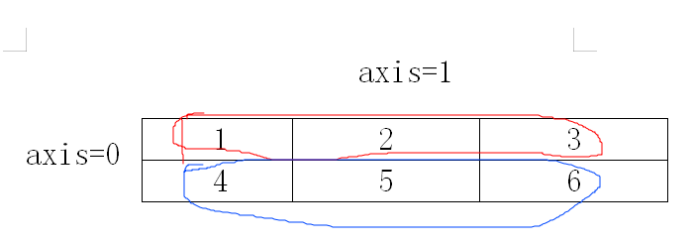
arr1.sum(axis=0) #简写arr1.sum(0)
结果:array([5, 7, 9])
#算术平均数
#求数组中全部元素的算术平均数
arr1.mean()
结果:3.5
#沿第0轴方向求算术平均数
arr1.mean(0)
结果:array([ 2.5, 3.5, 4.5])
#沿第1轴方向求算术平均数
arr1.mean(1)
结果:array([ 2., 5.])
#最大最小值
#全部元素最大值
arr1.max()
结果:6
#全部元素最小值
arr1.min()
结果:1
#沿第1轴方向最大值
arr1.max(1)
结果:array([3, 6])
#沿第1轴方向最小值
arr1.min(1)
结果:array([1, 4])
ndarray 对象由计算机内存的连续一维部分组成,并结合索引模式,将每个元素映射到内存块中的一个位置。内存块以行顺序(C样式)或列顺序(FORTRAN或MatLab风格,即前述的F样式)来保存元素。
注意多维的话要指定统计的维度,否则默认是全部维度上做统计
NumPy 广播(Broadcast)
广播(Broadcast)是 numpy 对不同形状(shape)的数组进行数值计算的方式, 对数组的算术运算通常在相应的元素上进行。
如果两个数组 a 和 b 形状相同,即满足 a.shape == b.shape,那么 a*b 的结果就是 a 与 b 数组对应位相乘。这要求维数相同,且各维度的长度相同。
广播的规则:
让所有输入数组都向其中形状最长的数组看齐,形状中不足的部分都通过在前面加 1 补齐。
输出数组的形状是输入数组形状的各个维度上的最大值。
如果输入数组的某个维度和输出数组的对应维度的长度相同或者其长度为 1 时,这个数组能够用来计算,否则出错。
当输入数组的某个维度的长度为 1 时,沿着此维度运算时都用此维度上的第一组值。
简单理解:对两个数组,分别比较他们的每一个维度(若其中一个数组没有当前维度则忽略),满足:
数组拥有相同形状。
当前维度的值相等。
当前维度的值有一个是 1。
若条件不满足,抛出 “ValueError: frames are not aligned” 异常。
注释
这里只是简单提一下,接下来会有专门的博客讲解广播
最后
以上就是整齐小蝴蝶最近收集整理的关于数据分析的全部内容,更多相关数据分析内容请搜索靠谱客的其他文章。








发表评论 取消回复