linear regression
When the target variable that we’re trying to predict is continuous, we call the learning problem a regression problem, when y can take only a small number of discrete values, we call it a classification problem.

The cost function of linear regression is:
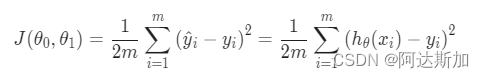
Our goal is to minimize the cost function.
随机矩阵
随机矩阵实际上应当分成行随机矩阵(Row stochastic matrix)和列随机矩阵(Column stochastic matrix)。行随机矩阵是指方阵的行和等于1;而列随机矩阵就是其列和等于1的非负矩阵。那么同时满足行和列和都是1的非负矩阵就是双随机矩阵(Double stochastic matrix),单位矩阵就是一种双随机矩阵。
Gradient Descent
Imagine that we graph our hypothesis function based on its fields θ0 and θ1 (actually we are graphing the cost function as a function of the parameter estimates). We are not graphing x and y itself, but the parameter range of our hypothesis function and the cost resulting from selecting a particular set of parameters.
The main steps of Gradient Descent are as follow:


The way we do this is by taking the derivative (the tangential line to a function) of our cost function. The slope of the tangent is the derivative at that point and it will give us a direction to move towards. We make steps down the cost function in the direction with the steepest descent. The size of each step is determined by the parameter α, which is called the learning rate.
The direction in which the step is taken is determined by the partial derivative of J(θ0,θ1).

最后
以上就是辛勤荷花最近收集整理的关于吴恩达Machine Learning笔记-linear regression,gradient descent的全部内容,更多相关吴恩达Machine内容请搜索靠谱客的其他文章。








发表评论 取消回复