前言:
我们就以一个机器学习领域的Hello World任务一MNIST手写数字识别来初探TensorFlow。
MNIST(Mixed Nationa1 Institute of Standards and Technology database)是一个非常简单的机器视觉数据集,如图3-1所示,它由几万张28像素x28像素的手写数字组成,这些图片只包含灰度值信息。我们的任务就是对这些手写数字的图片进行分类,转成0~9一共10类。
一、加载MNIST数据集
首先对MNIST数据进行加载,为了方便使用,TensorFlow提供了一个类来处理MNIST数据。这个类会自动下载并转化MNIST数据的格式,将数据从原始的数据包中解析成训练和测试神经网络时使用的格式。下面给出了使用这个函数的样例在,我们在pycharm中直接运行下面的代码:
#coding=gbk
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets ("/path/to/MNIST—data/", one_hot=True)
print("Training data size: ", mnist.train.num_examples)
print("Validating data size: " ,mnist.validation.num_examples)
print("Testing data size: ",mnist.test.num_examples)
print(mnist.train.images.shape,mnist.train.labels.shape)
print(mnist.validation.images.shape,mnist.validation.labels.shape)
print(mnist.test.images.shape,mnist.test.labels.shape)
运行程序,输出:
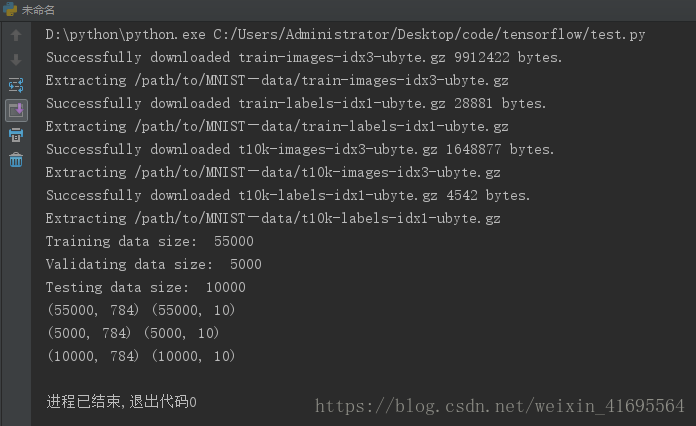
显然在载入MNIST数据集时,如果指定地址/path/to/MNIST_data下没有已经下载好的数据,那么TensorFlow会自动从下表给出的网址下载数据:
网址 | 内容 |
http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz | 训练数据图片 |
http://yann.lecun.com/exdb/mnist/train-labels-idxl-ubyte.gz | 训练数据答案 |
http://yann.lecun.com/exdb/mnist/tl0k-images-idx3-ubyte.gz | 测试数据图片 |
http://yann.lecun.com/exdb/mnist/tlOk-labels-idxl-ubyte.gz | 测试数据答案 |
从上面的代码中可以看出,通过input_data.read_data_sets函数生成的类会自动将 MNIST数据集划分为train、validation和test三个数据集,其中train这个集合内有55000 张图片,validation集合内有5000张图片,这两个集合组成了 MNIST本身提供的训练数据集。test集合内有10000张图片,这些图片都来自于MNIST提供的测试数据集。处理后的 每一张图片是一个长度为784的一维数组,这个数组中的元素对应了图片像素矩阵中的每一个数字(28x28=784)。因为神经网络的输入是一个特征向量,所以在此把一张二维图像 的像素矩阵放到一个一维数组中可以方便TensorFlow将图片的像素矩阵提供给神经网络的输入层。像素矩阵中元素的取值范围为[0, 1],它代表了颜色的深浅。其中0表示白色背景 (background ) , 1表示黑色前景(foreground )。
我们运行以下程序,来看看数据的表示形式:
#coding=gbk
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets ("/path/to/MNIST—data/", one_hot=True)
print("Example training data: ", mnist.train.images[0])
print("Example training data label: ",mnist.train.labels[0])
运行程序,输出:
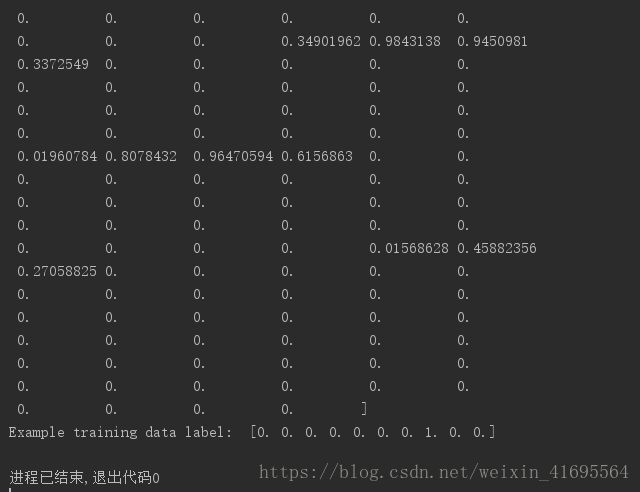
我们的训练数据的特征是一个55000x784的Tensor,同时训练的数据 Label是一个55000x10 的 Tensor,这里是对10个种类进行了 one-hot编码,Label是一个10维的向量,只有1个值为1,其余为 0。比如数字0,对应的Label就是[1,0,0,0,0,0,0,0,0,0],数字5对应的 Label就是[0,0,0,0,0,l,0,0,0,0],数字n就代表对应位置的值为1。
二、实现算法
准备好数据后,接下来就要设计算法了,这里使用一个叫作 Softmax Regression的算法训练手写数字识别的分类模型。我们的数字都是 0~9之间的,所以一共有10个类别,当我们的模型对一张图片进行预测时,Softmax Regression会对每一种类别估算一个概率:比如预测是数字3的概率为80%,是数字5的概率为5%,最后取概率最大的那个数字作为模型的输出结果。
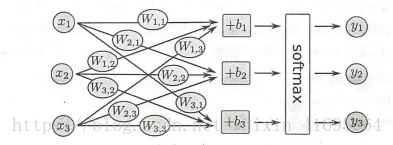
当我们处理多分类任务时,通常需要使用Softmax Regression模型。即使后面章节的卷积神经网络或者循环神经网络,如果是分类模型,最后一层也同样是Softmax Regression。它的工作原理很简单,将可以判定为某类的特征相加,然后将这些特征转化为判定是这一 类的概率。上述特征可以通过一些简単的方法得到,比如对所有像素求一个加权和,而权重是模型根据数据自动学习、训练出来的。比如某个像素的灰度值大代表很可能是数字 n 时,这个像素的权重就很大;反之,如果某个像素的灰度值大代表不太可能是数字n时,这个像素的权重就可能是负的。Softmax Regression的流程如下所示:
首先我们将MNIST数据集下载下来,并放在代码文件的目录下,如下所示:
接下来就使用 TensorFlow实现一个简单的Softmax Regression:
#coding=gbk
###################################
######### 作者:行歌 ############
######### 时间:2018.5.3 ########
###### email:1013007057@qq.com ##
###################################
import tensorflow as tf #载入TensorFlow库
TRAINING_STEPS = 1000 #定义训练论轮数
#接下来加载数据
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
x =tf.placeholder(tf.float32, [None, 784])
# 创建一个 Placeholde,即输入数据的地方。Placeholder的第一个参数是数据类型,第二个参数[None, 784]
# 代表tensor的shape,也就是数据的尺寸,这里None代表不限条数的输入,784代表每条输入是一个784维的向量
Weights = tf.Variable(tf.zeros([784,10]))
biases = tf.Variable(tf.zeros([10]))
# 声明Softmax Regression模型中的weights和biases参数
# Variable在模型训练迭代中是持久化的(比如一直存放在显存中), 它可以长期存在并且在每轮迭代中被更新。我们把
# weights和biases全部初始化为0, 因为模型训练时会自动学习合适的值, 所以对这个简单模型来说初始值不太重要。
# 不过对复杂的卷积网络、 循环网络或者比较深的全连接网络,初始化的方法就比较重要, 甚至可以说至关重要
y = tf.nn.softmax(tf.matmul(x,Weights)+biases)
# 我们使用一行简単的代码就定义了Softmax Regression, 即表示公式: y = softmax(Wx + b)
# softmax是tfnn下面的一个函数,而tf.nn则包含了大量神经网络的组件,tf.matmu1是TensorFow中的矩阵乘法函数
y_ = tf.placeholder(tf.float32,[None,10])
cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_*tf.log(y),reduction_indices=[1]))
# 对多分类问题,通常使用 cross-entropy 作为1oss function
# 先定义一个 placeholder,输入是真实的1abel,用来计算cross_entropy。
# tf.reduce_sum也就是求和的操作,而tf.reduce_mean则用来对每个batch数据结果求均值
train_step = tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy)
# 定义一个优化算法,定义好优化算法后,TensorF1ow就可以根据我们定义的整个计算图自动求导
# 并根据反向传播算法进行训练,在每一轮迭代时更新参数来减小1oss。
# 我们直接调用tf.train.GradientDescentOptimizer,并设置学习速率为 0.5,
# 优化目标设定为 cross_entropy, 得到进行训练的操作train_step
with tf.Session() as sess:
init_op = tf.global_variables_initializer()
sess.run(init_op)
for i in range(TRAINING_STEPS):
batch_size = 100
batch_xs,batch_ys = mnist.train.next_batch( batch_size )
sess.run(train_step,feed_dict={x:batch_xs,y_:batch_ys })
# 为了方便使用随机梯度下降,input_data.read_data_sets函数生成的类还提供了mnist.train.next_batch函数
# 它可以从所有的训练数据中读取一小部分作为一个训练batch,我们开始迭代地执行训练操作train_step。
# 这里每次都随机从训练集中抽取100条样本构成一个batch,并feed给placeholder, 然后调用train_step对这些样本进行训练
if i % 100 == 0:
# 每100轮输出一次在验证数据集上的测试结果
correct_prediction = tf.equal(tf.argmax(y,1),tf.argmax(y_,1))
accuracy = tf.reduce_mean(tf.cast( correct_prediction ,tf.float32))
validate_accuracy = sess.run(accuracy,feed_dict={x:mnist.validation.images,y_:mnist.validation.labels})
print("After %d training step(s), validation accuracy using average model is %g" %(i,validate_accuracy))
# 代码中的tf.argmax是从一个tensor中寻找最大值的序号, tf.argmax(y, 1)就是求各个预测的数字中概率最大的那一个,
# 而tf.argmax(y_1)则是找样本的真实数字类别。而tf.equa1方法则用来判断预测的数字类别是否就是正确的类别,
# 最后返回计算分类是否正确的操作correct_predition。
# 预测全部验证集样本的validate_accuracy,这里需要先用tf.cast将之前validate_accuracy输出的boo1值转换为float32,再求平均
#训练结束以后,在测试数据集上检测模型的最终正确率
print("**********************训练结束*******************")
test_accuracy = sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels})
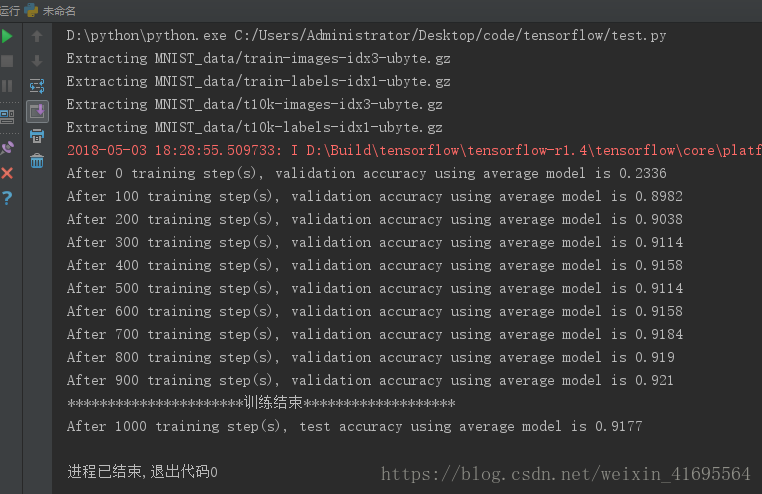
print("After %d training step(s), test accuracy using average model is %g" %(TRAINING_STEPS,test_accuracy))运行上面的程序,得到下面的输出结果:
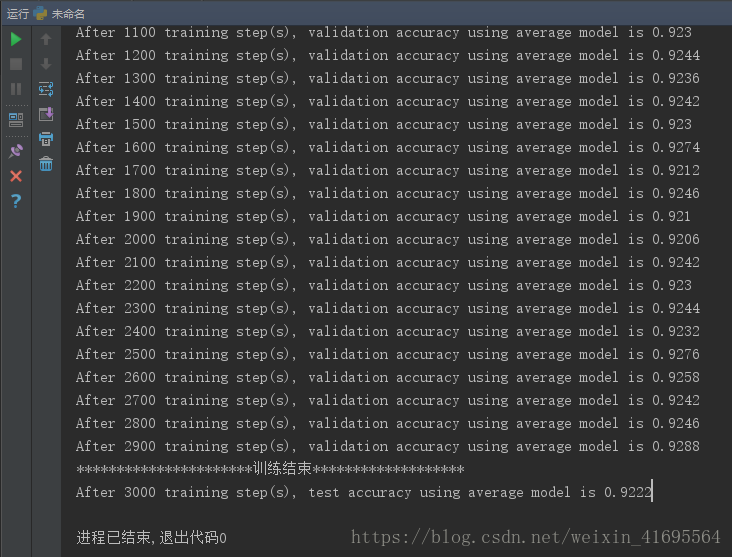
把训练轮数调整道3000,输出结果如下:
把训练轮数调整道5000,输出结果如下:
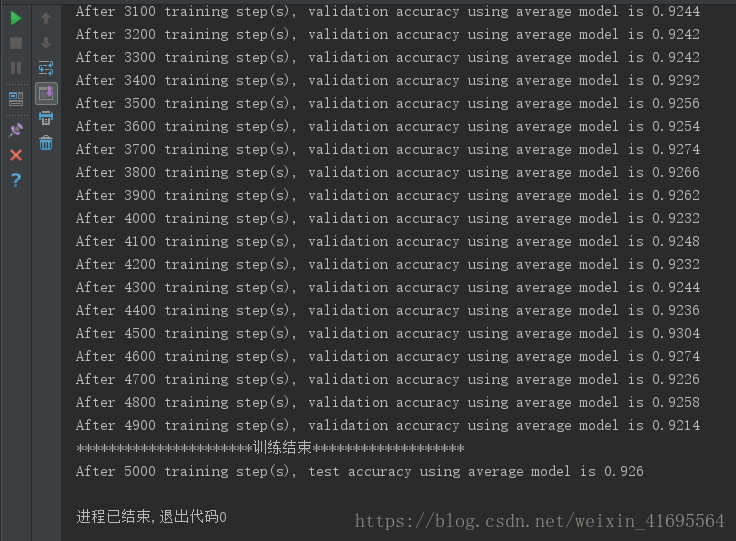
显然,使用Softmax Regression对MNIST数据进行分类识别,在测试集上平均准确率只有92%左右!!
三、总结
通过上面的这个简単例子,我们使用 TensorFlow实现了一个简单的机器学习算法——Softmax Regression,这可以算作是一个没有隐含层的最浅的神经网络。我们来回忆一下整个流程,我们做的事情可以分为4个部分:
( 1 )定义算法公式,也就是神经网络 forward时的计算。
( 2 )定义1oss,选定优化器,并指定优化器优化1oss。
( 3 )迭代地对数据进行训练。
( 4 )在测试集或验证集上对准确率进行评测。
这几个步環是我们使用 TensorFlow进行算法设计、训练的核心步骤,也将会贯穿其他类型神经网络之中。
Softmax Regression达到的效果,准确率为92%,虽然是一个还不错的数字,但是还达不到实用的程度。手写数字的识别的主要应用场景是识别银行支票,如果准确率不够高,可能会引起严重的后果。
接下来我会继续使用其他算法在MNIST数据集上进行训练,事实上,现在的softmax Regression加入隐含层变成一个正统的神经网络后,再结合 Dropout、Adagrad、ReLu等技术准确率就可以达到98%。引入卷积层、池化层后,也可以达到99%的正确率。 而目前基于卷积神经网络的 state-of-the-art 的方法已经可以达到99.8%的正确率。
参考文献:
[1] 郑泽宇著 《TensorFlow实战Google深度学习框架》
[2] 黄文坚著 《TensorFlow实战》最后
以上就是大意短靴最近收集整理的关于TensorFlow实战(一)——基于Softmax Regression识别MNIST手写数字的全部内容,更多相关TensorFlow实战(一)——基于Softmax内容请搜索靠谱客的其他文章。








发表评论 取消回复