我是靠谱客的博主 高挑信封,这篇文章主要介绍李宏毅机器学习(二)——回归案例分析 Regression Case Study(附上代码Python版本,Scala版本后续加上,见文尾另一博客),现在分享给大家,希望可以做个参考。
回归案例分析(按思路理解梳理一下):

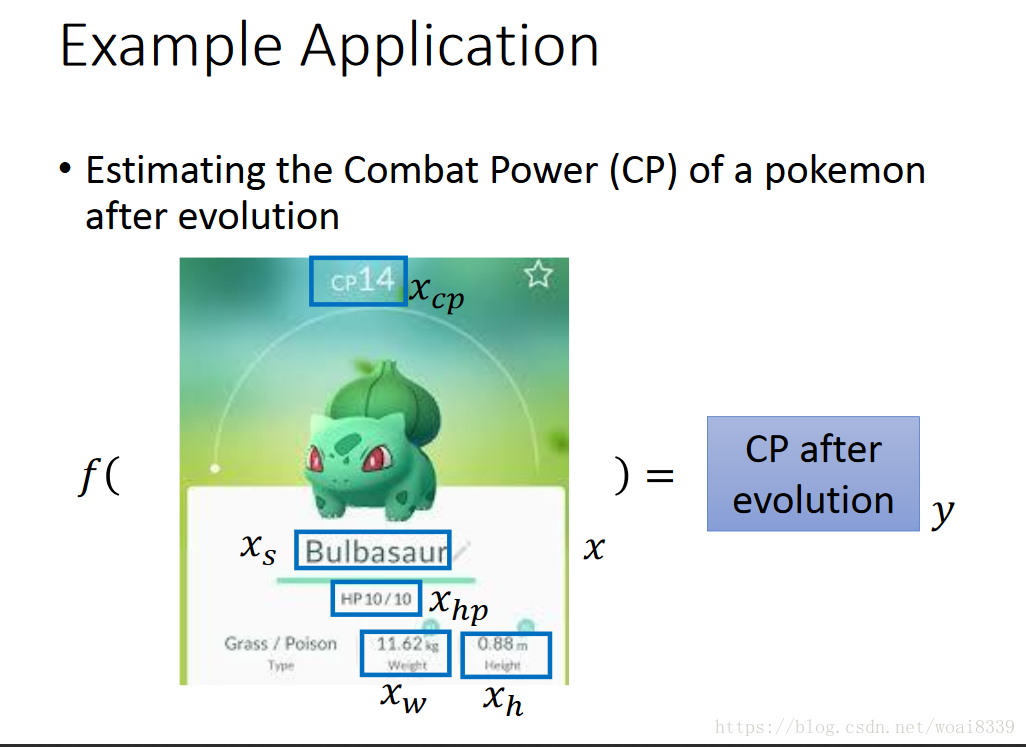
以pokemon来分析回归问题,预测poken的战斗力:
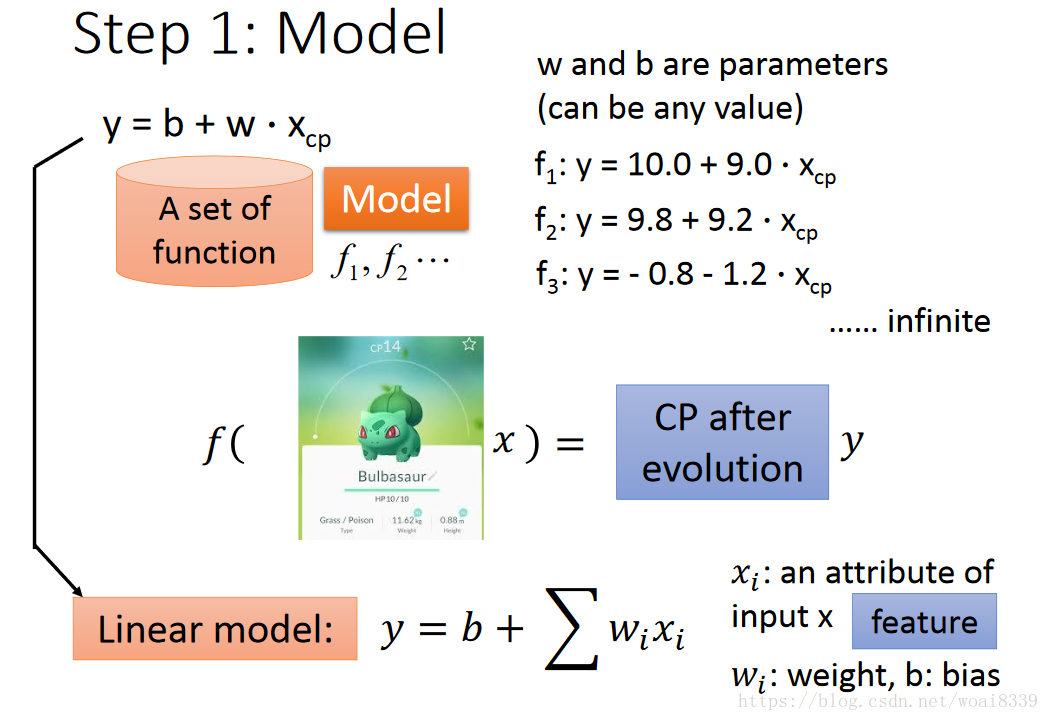
首先想到的是一个线性模型,wi表示权重,xi我们可以理解成特征,b是偏差。对于预测的数值我们可以写成sum(wi*xi)+b,
预测问题的评判我们可以看预测值与实际值的差距,具体我们可以表示如下图,损失函数为平方损失:

具体优化目标(没有加正则项)可以表示为:
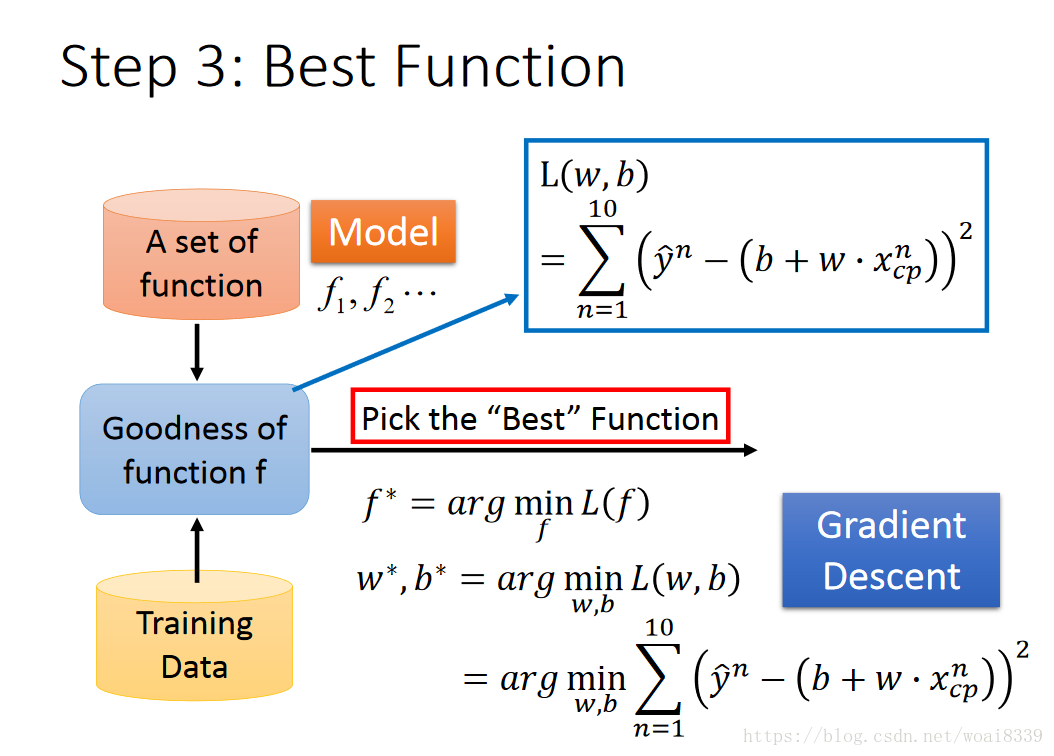
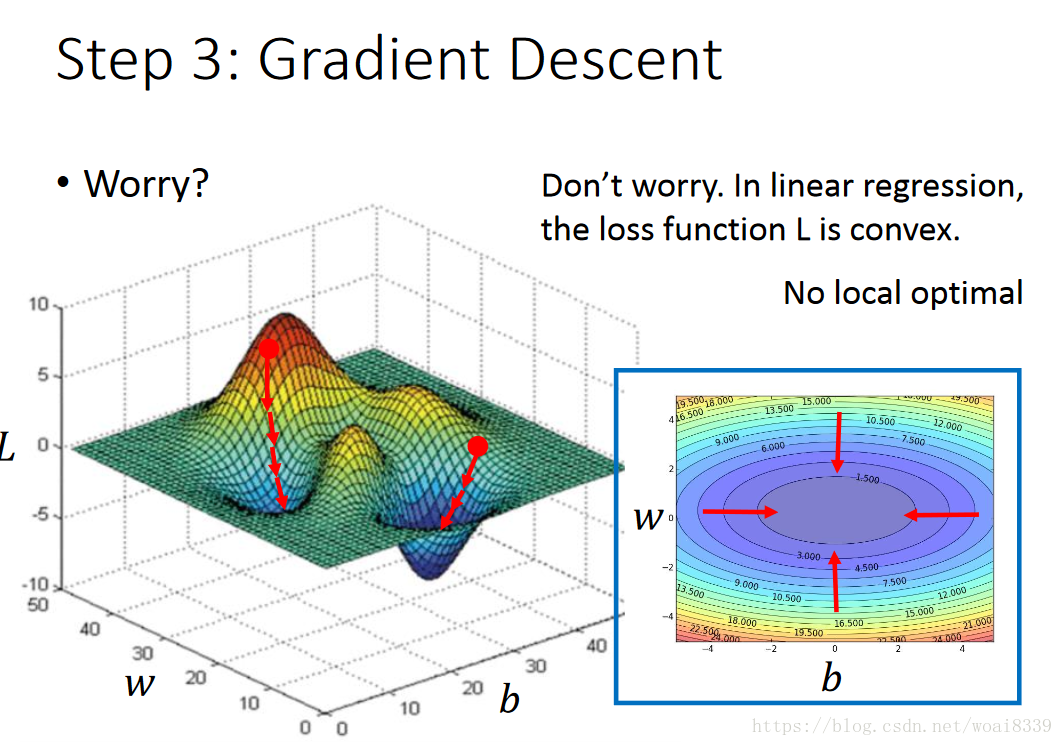
接下来需要对目标函数进行优化,找到最优的w,b。我们想到了梯度下降法(梯度下降法、随机梯度下降法、牛顿法的区别与联系后续说)。如下图表示:
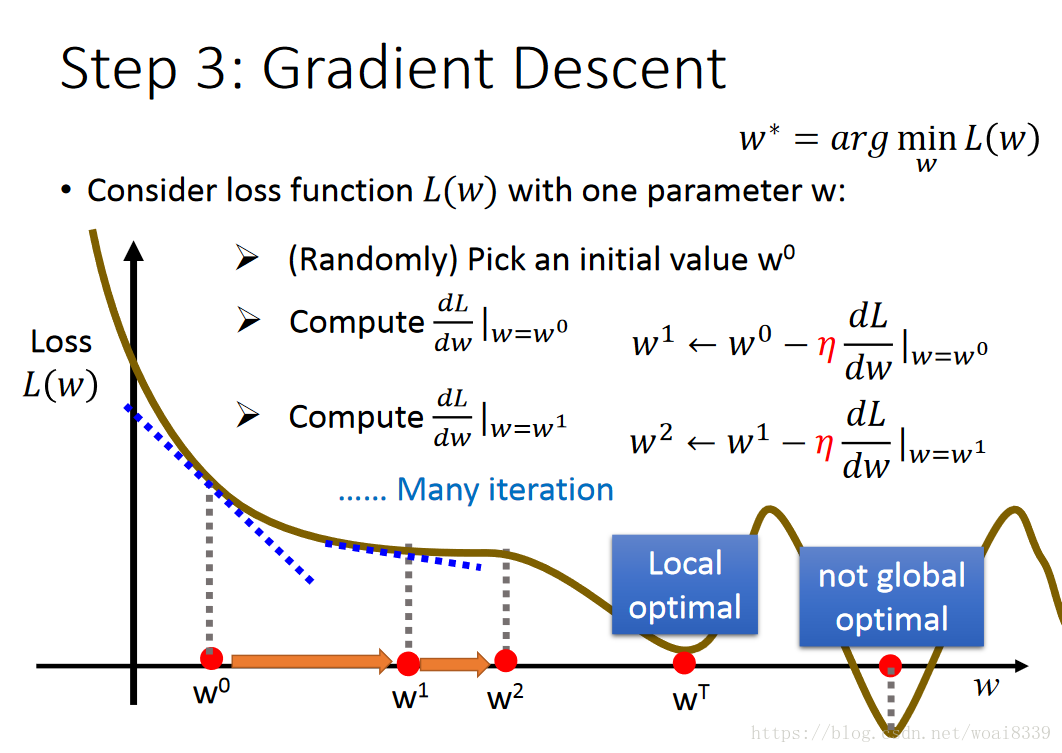

在线性回归问题中不存在局部最优,是因为线性回归是凸优化问题。
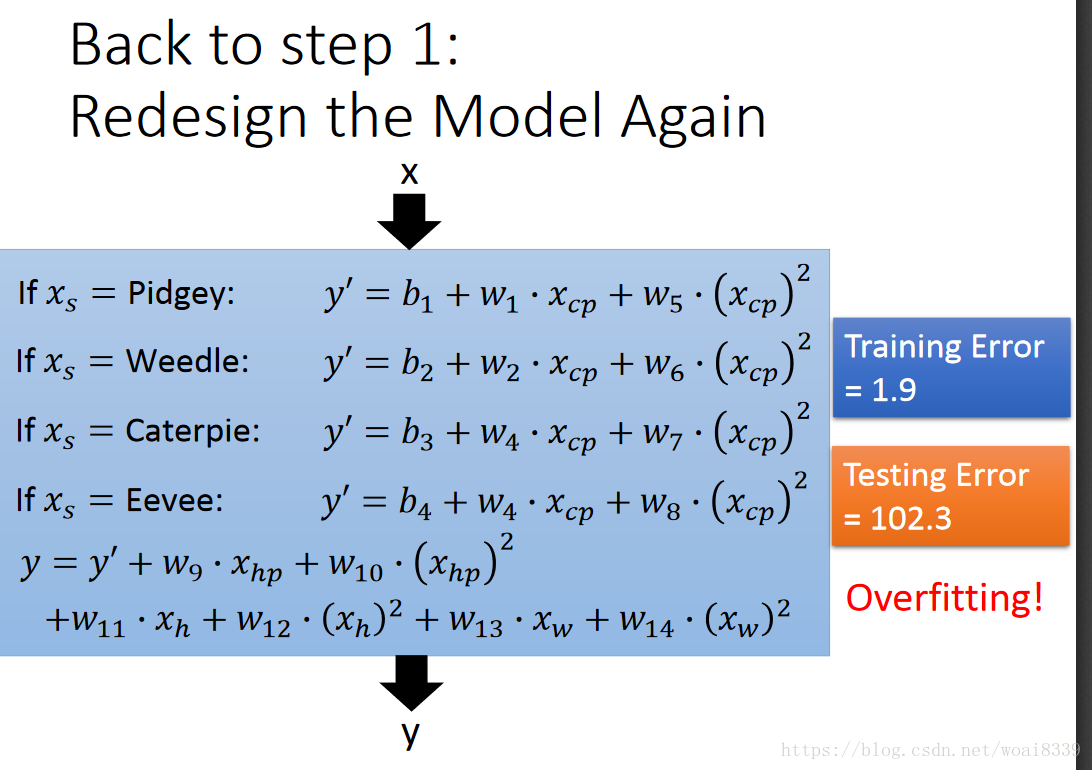
但会有过拟合问题,比如模型太复杂,数据量太少等原因引起的。一个直观的表现是在训练集上误差较小,在测试集上误差较大。如图:
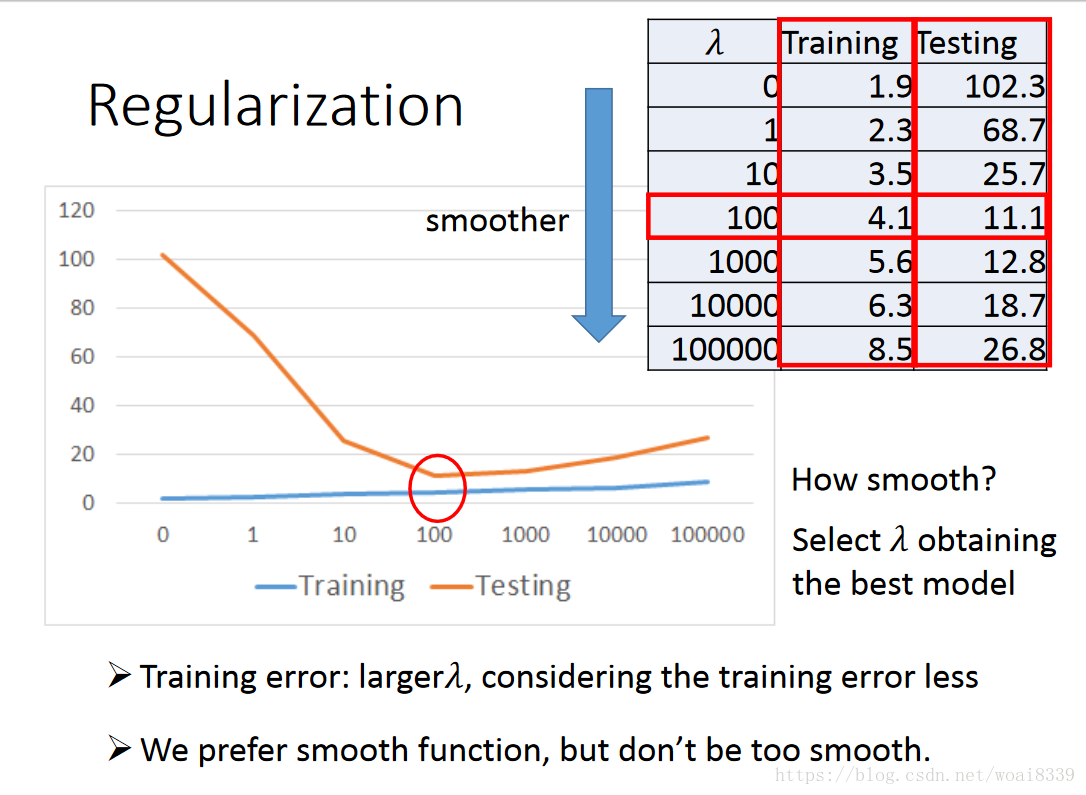
对于过拟合的解决方法参考之前blog为什么L1可以做特征选择,其系数为0。这里以正则项举例:

平滑函数会更好一些(我的理解就是损失函数加入了正则项,防止过拟合现象的产生)

但不是正则项系数越大越好,选择合适的最好。该文例子如下表示:
可能有人问,代码呢,别急。见之前一博客,从线性回归说起逻辑回归与FM马上:
#Ref: https://www.beibq.cn/book/cw0v22-1583
import tensorflow as tf
import numpy as np
x_data = np.float32(np.random.rand(2,100)) #2行100列
y_data = np.dot([0.100,0.200], x_data) + 0.300 #1行2列 × 2行100列
b = tf.Variable(tf.zeros([1]))
W = tf.Variable(tf.random_uniform([1,2],-1.0,1.0)) #y = w*x + b,x.shape = (2,100),b.shape=(1,1),so w.shape=(1,2)
#y = tf.multiply(W, x_data) + b
y = tf.matmul(W, x_data) + b
# min loss
loss = tf.reduce_mean(tf.square(y - y_data))
optimizer = tf.train.GradientDescentOptimizer(0.5)
train = optimizer.minimize(loss)
#variable init,定义了variable这一步必须要初始化
init = tf.initialize_all_variables()
#start graph
sess = tf.Session()
sess.run(init)
#fit
for step in range(0,201):
sess.run(train)
if step%20 == 0:
print(step, sess.run(loss), sess.run(W), sess.run(b))最后
以上就是高挑信封最近收集整理的关于李宏毅机器学习(二)——回归案例分析 Regression Case Study(附上代码Python版本,Scala版本后续加上,见文尾另一博客)的全部内容,更多相关李宏毅机器学习(二)——回归案例分析内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复