前几天看了一道面试题?问道fork的复制流程是怎么的?描述写时拷贝?
我想如果我简单的说是子进程复制了父进程的所有资源是不是太low了,因此搜集了一些资料,从底层详细进行分析。
目录
1.fork的处理流程
2.fork调用流程图
do_fork的实现
copy_process的实现流程
3.写时拷贝技术
1.fork的处理流程
从c语言中的fork函数开始,它在gblic库中会被转换成init0x80加调用号的形式,触发中断。该中断在系统初始化的过程中已经进行了注册,该中断的处理函数为system_call(system_call.s中),在这里面它首先压栈一些参数,然后会根据调用号去调用sys_call_table里面的相应表项,sys_call_table定义在include/linux/sys.h里面,它是一个函数指针数组。现在对应的就是sys_fork函数,sys_fork函数仍然在system_call.s中定义。
sys_fork函数会去调用find_empty_process函数来从task数组中查找一个还没有使用的task,找到之后把对应的索引返回(保存在eax中),随后保存一些其他的寄存器,同时将返回的索引值当作参数来调用copy_process函数。
copy_process函数的处理过程:
首先分配一个内存页,然后保存一个task_struct结构体在页的最开始位置(同时将新task_struct结构体注册进task数组),将内核栈指针置于该页的顶端。紧接着将父进程的task_struct复制进当前的task_struct,并修改当前task_struct的一些内容,这些内容是不能从父进程直接继承的。具体的一些修改有:
- 将进程pid设置为find_empty_process函数找到的task数组的索引值
- 将ppid设置为父进程的id。
- 设置eip,设置eax,设置内核栈指针等。
- 设置页表
- 等等
为了设置页表,我们需要知道一个进程的代码段和数据段的起始地址以及占用了多大的空间。由于二者是重叠的,我们设置一个就可以了。获取的过程是通过查看进程ldt表项来获取基址和限长。由于linux0.11中进程的起始地址为64M×nr,所以前面的基址其实并没有太大作用,知道了起始地址,现在就可以知道它在页目录中的索引了,我们设置它的页目录项,现在可以设置它的页表了,首先获取父进程的页表,并对页表进行拷贝,拷贝的过程中,我们把子进程的页面属性设置为只读(父进程也被设为只读了,内核空间除外)。这样就完成了页表的设置,由于是只读的,当子进程执行写操作时会触发写保护,在写保护处理中会拷贝页面。现在页表就已经设置好了。接下来该为它设置gdt中的项目了。还需要提一点,之前我们根据进程号nr计算出代码段和数据段起始地址,并把它设置到了task_struct的ldt中。现在我们再次根据nr计算出ldt和tss在gdt中的位置,并向其中注册ldt和tss,通过这个过程我们就把task_struct中的tss和ldt的地址注册到gdt中对应的表项处。到此,所有的工作都已经完成了,设置其状态为可运行状态(刚开始是被设置为不可中断状态),返回新建进程号。
2.fork调用流程图
linux提供了三个系统调用去创建新的进程:clone(),fork(),vfork()。linux内核中都是通过do_fork来实现这三个系统调用的。
新的进程通过复制父进程而创建,为了创建新进程,首先在系统的物理内存中为新进程创建task_strut结构体,将父进程的结构体内容复制进去,再修改部分数据,接着为新进程分配新的堆栈,分配新的进程标识符。然后将新的task_strut数组加入到task数组中,并调整进程链关系,插入运行队列中。于是,这个新进程便可以在下次调度时被选择执行。此时,由于父进程的进程上下文 TSS 结构复制到了子进程的 TSS 结构中,通过改变其中的部分数据,便可以使子进程的执行效果与父进程一致,都是从系统调用中退出,而且子进程将得到与父进程不同的返回值(返回父进程的是子进程的 pid,而返回子进程的是 0)
流程图如下:
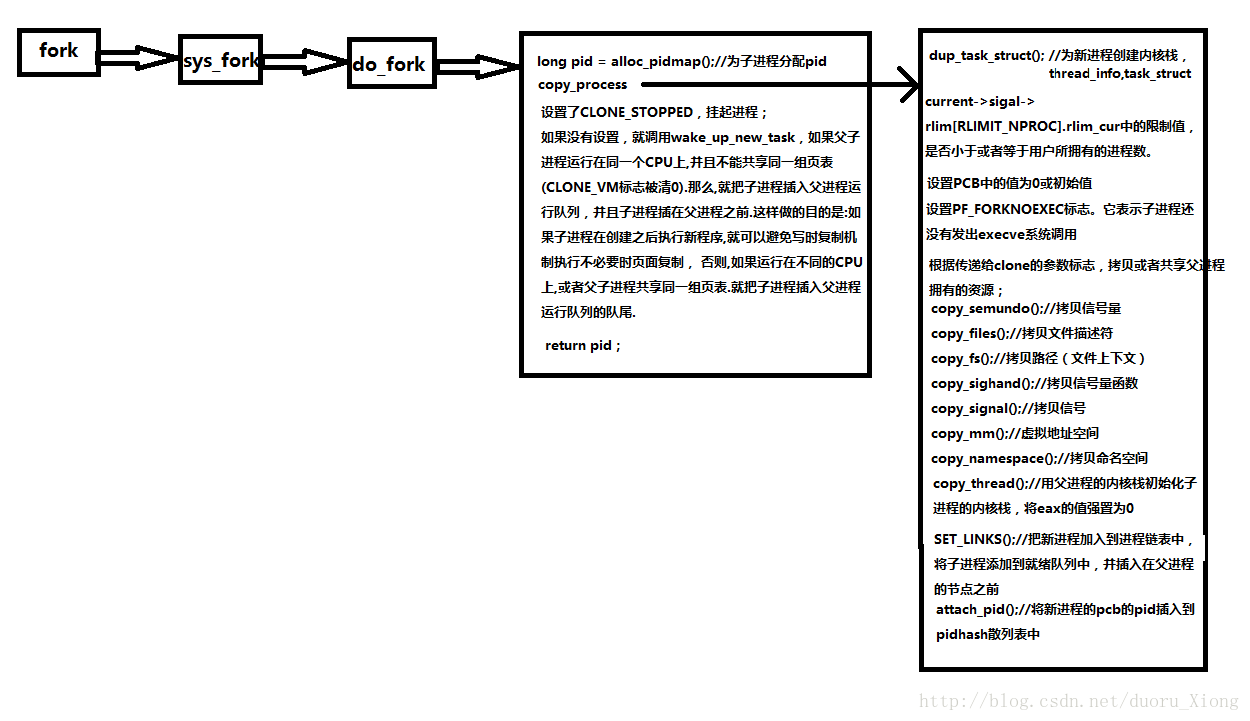
do_fork的实现
第一步是调用copy_process函数来复制一个进程,并对相应的标志位等进行设置,接下来,如果copy_process调用成功的话,那么系统会有意让新开辟的进程运行,这是因为子进程一般都会马上调用exec()函数来执行其他的任务,这样就可以避免写时复制造成的开销,或者从另一个角度说,如果其首先执行父进程,而父进程在执行的过程中,可能会向地址空间中写入数据,那么这个时候,系统就会为子进程拷贝父进程原来的数据,而当子进程调用的时候,其紧接着执行拉exec()操作,那么此时,系统又会为子进程拷贝新的数据,这样的话,相比优先执行子程序,就进行了一次“多余”的拷贝。
copy_process的实现流程
p = dup_task_struct(current); 为新进程创建一个内核栈、thread_iofo和task_struct,这里完全copy父进程的内容,所以到目前为止,父进程和子进程是没有任何区别的。
检查所有的进程数目是否已经超出了系统规定的最大进程数,如果没有的话,那么就开始设置进程描诉符中的初始值,从这开始,父进程和子进程就开始区别开了。
设置子进程的状态为不可被TASK_UNINTERRUPTIBLE,从而保证这个进程现在不能被投入运行,因为还有很多的标志位、数据等没有被设置。
复制标志位(falgs成员)以及权限位(PE_SUPERPRIV)和其他的一些标志。
调用get_pid()给子进程获取一个有效的并且是唯一的进程标识符PID。
根据传入的cloning flags(具体表示上面有)对相应的内容进行copy。比如说打开的文件符号、信号等。
父子进程平分父进程剩余的时间片。
return p;返回一个指向子进程的指针。
3.写时拷贝技术
声明:以下内容参见博客:https://blog.csdn.net/xy010902100449/article/details/44851453
假如有如下程序:
#include<stdio.h>
#include<string.h>
#include<stdlib.h>
#include<unistd.h>
void main()
{
char str[6]="hello";
pid_t pid=fork();
if(pid==0)
{
str[0]='b';
printf("子进程中str=%sn",str);
printf("子进程中str指向的首地址:%xn",(unsigned int)str);
}
else
{
sleep(1);
printf("父进程中str=%sn",str);
printf("父进程中str指向的首地址:%xn",(unsigned int)str);
}
}
打印结果如下:
子进程中str=bello
子进程中str指向的首地址:bfdbfc06
父进程中str=hello
父进程中str指向的首地址:bfdbfc06打印可以发现父进程和子进程中的地址是一样的。子进程不是有自己的堆栈吗?为什么地址一样,这就涉及到了虚拟地址,关于虚拟地址的内容可以参见我的另一篇博客:https://blog.csdn.net/qq_42214953/article/details/105558471
fork()会产生一个和父进程完全相同的子进程,但子进程在此后多会exec系统调用,出于效率考虑,linux中引入了“写时复制“技术,也就是只有进程空间的各段的内容要发生变化时,才会将父进程的内容复制一份给子进程。在fork之后exec之前两个进程用的是相同的物理空间(内存区),子进程的代码段、数据段、堆栈都是指向父进程的物理空间,也就是说,两者的虚拟空间不同,但其对应的物理空间是同一个。当父子进程中有更改相应段的行为发生时,再为子进程相应的段分配物理空间,如果不是因为exec,内核会给子进程的数据段、堆栈段分配相应的物理空间(至此两者有各自的进程空间,互不影响),而代码段继续共享父进程的物理空间(两者的代码完全相同)。而如果是因为exec,由于两者执行的代码不同,子进程的代码段也会分配单独的物理空间。
fork时子进程获得父进程数据空间、堆和栈的复制,所以变量的地址(当然是虚拟地址)也是一样的。
每个进程都有自己的虚拟地址空间,不同进程的相同的虚拟地址显然可以对应不同的物理地址。因此地址相同(虚拟地址)而值不同没什么奇怪。
具体过程是这样的:
fork子进程完全复制父进程的栈空间,也复制了页表,但没有复制物理页面,所以这时虚拟地址相同,物理地址也相同,但是会把父子共享的页面标记为“只读”(类似mmap的private的方式),如果父子进程一直对这个页面是同一个页面,知道其中任何一个进程要对共享的页面“写操作”,这时内核会复制一个物理页面给这个进程使用,同时修改页表。而把原来的只读页面标记为“可写”,留给另外一个进程使用。
这就是所谓的“写时复制”。正因为fork采用了这种写时复制的机制,所以fork出来子进程之后,父子进程哪个先调度呢?内核一般会先调度子进程,因为很多情况下子进程是要马上执行exec,会清空栈、堆。。这些和父进程共享的空间,加载新的代码段。。。,这就避免了“写时复制”拷贝共享页面的机会。如果父进程先调度很可能写共享页面,会产生“写时复制”的无用功。所以,一般是子进程先调度滴。
假定父进程malloc的指针指向0x12345678, fork 后,子进程中的指针也是指向0x12345678,但是这两个地址都是虚拟内存地址
经过内存地址转换后所对应的 物理地址是不一样的。所以两个进程中的这两个地址相互之间没有任何关系。
(注1:在理解时,你可以认为fork后,这两个相同的虚拟地址指向的是不同的物理地址,这样方便理解父子进程之间的独立性)
(注2:但实际上,linux为了提高 fork 的效率,采用了 copy-on-write 技术,fork后,这两个虚拟地址实际上指向相同的物理地址(内存页),只有任何一个进程试图修改这个虚拟地址里的内容前,两个虚拟地址才会指向不同的物理地址(新的物理地址的内容从原物理地址中复制得到))
最后
以上就是风中唇膏最近收集整理的关于frok创建子进程的流程(底层实现)||fork源码剖析||(详解)||写实拷贝的全部内容,更多相关frok创建子进程内容请搜索靠谱客的其他文章。








发表评论 取消回复