2019独角兽企业重金招聘Python工程师标准>>> 
1:整合log4j和flume
它们整合使用的是flume中的avro source
flume使用的是1.5.2版本
1)修改flume的配置文件conf/flume-conf.properties
把里面的agent部分的配置都删除掉,使用下面的配置
agent1.channels = ch1
agent1.sources = avro-source1
agent1.sinks = log-sink1
# 定义channel
agent1.channels.ch1.type = memory
# 定义source
agent1.sources.avro-source1.channels = ch1
agent1.sources.avro-source1.type = avro
agent1.sources.avro-source1.bind = 0.0.0.0
agent1.sources.avro-source1.port = 41414
# 定义sink
agent1.sinks.log-sink1.channel = ch1
agent1.sinks.log-sink1.type = logger
2)修改项目中的log4j的配置
修改log4j.properties文件
log4j.rootLogger=INFO,flume
log4j.appender.flume = org.apache.flume.clients.log4jappender.Log4jAppender
log4j.appender.flume.Hostname = 192.168.1.170
log4j.appender.flume.Port = 41414
log4j.appender.flume.UnsafeMode = true
注意:需要在项目中添加log4jappender的maven依赖、
<dependency>
<groupId>org.apache.flume.flume-ng-clients</groupId>
<artifactId>flume-ng-log4jappender</artifactId>
<version>1.5.2</version>
</dependency>
3):写一个log4j测试类,验证log4j和flume是否整合成功,
测试类代码如下
public class Log4FlumeTest {
Logger logger=LoggerFactory.getLogger(getClass());
@Test
public void testFlume() throws Exception {
for(int i=0;i<100;i++){
logger.info("第"+i+"次输出");
System.out.println("第"+i+"次输出");
Thread.sleep(3000);
}
}
}
需要先启动flume,命令如下:
bin/flume-ng agent --conf conf --conf-file conf/flume-conf.properties --name agent1 -Dflume.root.logger=INFO,console
执行log4j测试类,产生日志数据,
监控flume控制台的日志输出,只要能看到日志不停打印就说明整合成功。
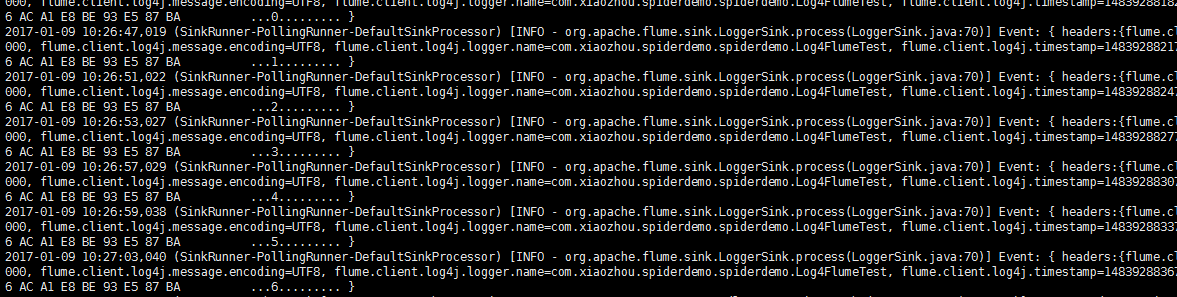
2:flume和kafka整合
再整合之前首先包保证kafka是正常的。
所以先部署kafka,再写一个kafka的生产者的代码,在命令行上启动一个kafaka的消费者,
这样使用代码产生数据,在控制台消费,即可验证kafaka是否正常
在node11创建topic bin/kafka-topics.sh --create --zookeeper node22:2181,node33:2181,node44:2181 --replication-factor 1 --partitions 1 --topic topic2
在node11查看消bin/kafka-console-consumer.sh --zookeeper node22:2181,node33:2181,node44:2181 --topic topic2 --from-beginning
kafka的生产者代码
@Test
public void testName() throws Exception {
Properties originalProps = new Properties();
originalProps.put("metadata.broker.list", "node11:9092,node22:9092");
originalProps.put("serializer.class", StringEncoder.class.getName());
ProducerConfig config = new ProducerConfig(originalProps );
Producer<String, String> producer = new Producer<String,String>(config );
KeyedMessage<String, String> message = new KeyedMessage<String, String>("topic2", "kafkatest");
producer.send(message);
}
执行代码 在控制台上出现如下图表示kafka正常

下面就可以自定义kafkasink来整合flume和kafka了
参考官网文档,实现自定义kafakasink的代码如下:
package com.xiaozhou.kafakflumestorm.kafakflumestorm;
import java.util.Properties;
import kafka.javaapi.producer.Producer;
import kafka.producer.KeyedMessage;
import kafka.producer.ProducerConfig;
import kafka.serializer.StringEncoder;
import org.apache.flume.Channel;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.EventDeliveryException;
import org.apache.flume.Transaction;
import org.apache.flume.conf.Configurable;
import org.apache.flume.sink.AbstractSink;
public class KafkaSink extends AbstractSink implements Configurable {
Producer<String, String> producer;
/**
* 在组件初始化的时候执行一次
*/
public void configure(Context context) {
Properties originalProps = new Properties();
originalProps.put("metadata.broker.list", "node11:9092,node22:9092");
originalProps.put("serializer.class", StringEncoder.class.getName());
ProducerConfig config = new ProducerConfig(originalProps );
producer = new Producer<String,String>(config );
}
public Status process() throws EventDeliveryException {
Status status = null;
// Start transaction
Channel ch = getChannel();
Transaction txn = ch.getTransaction();
txn.begin();
try {
Event event = ch.take();
if(event==null){
txn.rollback();
status = Status.BACKOFF;
return status;
}
byte[] byte_message = event.getBody();
KeyedMessage<String, String> message = new KeyedMessage<String, String>("topic2", new String(byte_message));
producer.send(message);
txn.commit();
status = Status.READY;
} catch (Throwable t) {
txn.rollback();
status = Status.BACKOFF;
if (t instanceof Error) {
throw (Error)t;
}
} finally {
txn.close();
}
return status;
}
}
下面就可以打包了,打包的时候需要使用到maven的打包插件,在pom文件中添加如下配置
<build>
<plugins>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
<archive>
<manifest>
<mainClass></mainClass>
</manifest>
</archive>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
<!-- compiler插件, 设定JDK版本 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>2.3.2</version>
<configuration>
<encoding>UTF-8</encoding>
<source>1.7</source>
<target>1.7</target>
<showWarnings>true</showWarnings>
</configuration>
</plugin>
</plugins>
</build>
打包 在cmd命令提示符下 执行命令 mvn clean package -DskipTests
出现如下图表示打包成功
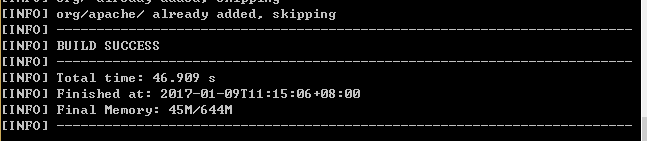
打包之后把生成的带依赖的jar包拷贝到flume的lib目录下即可。
最后修改flume的配置文件conf/flume-conf.properties,吧sink从之前的logger改为现在的最定义kafkasink,具体值为kafkasink类的全路径。
这样使用log4jtest产生日志数据,只要能kafka消费掉,就说明log4j+flume+kafka已经正常成功。

3:kafka和strom整合
使用storm提供的storm-kafka插件,添加对于的maven依赖
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-kafka</artifactId>
<version>1.0.1</version>
</dependency>
先写storm的整合代码
package com.xiaozhou.kafakflumestorm.kafakflumestorm;
import java.util.UUID;
import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.kafka.BrokerHosts;
import org.apache.storm.kafka.KafkaSpout;
import org.apache.storm.kafka.SpoutConfig;
import org.apache.storm.kafka.ZkHosts;
import org.apache.storm.topology.TopologyBuilder;
public class KafKaStorm {
public static void main(String[] args){
TopologyBuilder builder=new TopologyBuilder();
BrokerHosts hosts = new ZkHosts("node22:2181,node33:2181,node44:2181");
String topic = "topic2";
String zkRoot = "/kafkaspout";
String id = UUID.randomUUID().toString();
SpoutConfig spoutConf=new SpoutConfig(hosts, topic, zkRoot, id);
String name=KafKaStorm.class.getSimpleName();
builder.setSpout(name, new KafkaSpout(spoutConf));
builder.setBolt("stormbolt", new StromBolt()).shuffleGrouping(name);
LocalCluster localCluster = new LocalCluster();
localCluster.submitTopology("kafkastormflume", new Config(), builder.createTopology());
}
}
package com.xiaozhou.kafakflumestorm.kafakflumestorm;
import java.util.Map;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.tuple.Tuple;
public class StromBolt extends BaseRichBolt {
OutputCollector collector;
@Override
public void prepare(Map stormConf, TopologyContext context,
OutputCollector collector) {
// TODO Auto-generated method stub
this.collector=collector;
}
@Override
public void execute(Tuple input) {
System.out.println("bolt接到数据了"+ new String(input.getBinaryByField("bytes")));
//消息确认机制
this.collector.ack(input);
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
// TODO Auto-generated method stub
}
}
执行storm的代码,会发现报错,缺少kafka的依赖包,添加进去之后发现报错,日志冲突,
需要把一些maven依赖中的log4j过滤掉
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.11</artifactId>
<version>0.9.0.1</version>
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.flume</groupId>
<artifactId>flume-ng-core</artifactId>
<version>1.5.2</version>
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
</exclusion>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
<exclusion>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
</exclusion>
</exclusions>
</dependency>
再执行strom程序,发现可以正常启动。
使用log4jtest产生测试日志数据,这边的storm程序能接收到数据,并进行处理,但是会发现数据被重复处理
这是因为在bolt中没有对数据进行确认,需要调用ack或者fail方法。
修改完成之后即可。
转载于:https://my.oschina.net/xiaozhou18/blog/821292
最后
以上就是土豪酸奶最近收集整理的关于log4j+flume+kafka+storm 整合1:整合log4j和flume2:flume和kafka整合 3:kafka和strom整合的全部内容,更多相关log4j+flume+kafka+storm内容请搜索靠谱客的其他文章。








发表评论 取消回复