这里主要强调的是作为客户端,发起http请求时的超时设置,特别是微服务场景下某下游的服务阻塞卡顿,这样会造成其他的级联上下游都雪崩了。
先看代码
package main
import (
"bytes"
"encoding/json"
"fmt"
"io/ioutil"
"net"
"net/http"
"time"
)
var tr *http.Transport
func init() {
tr = &http.Transport{
MaxIdleConns: 100,
Dial: func(netw, addr string) (net.Conn, error) {
conn, err := net.DialTimeout(netw, addr, time.Second*2) //设置建立连接超时
if err != nil {
return nil, err
}
err = conn.SetDeadline(time.Now().Add(time.Second * 3)) //设置发送接受数据超时
if err != nil {
return nil, err
}
return conn, nil
},
}
}
func main() {
for {
_, err := Get("http://www.baidu.com/")
if err != nil {
fmt.Println(err)
break
}
}
}
func Get(url string) ([]byte, error) {
m := make(map[string]interface{})
data, err := json.Marshal(m)
if err != nil {
return nil, err
}
body := bytes.NewReader(data)
req, _ := http.NewRequest("Get", url, body)
req.Header.Add("content-type", "application/json")
client := &http.Client{
Transport: tr,
}
res, err := client.Do(req)
if res != nil {
defer res.Body.Close()
}
if err != nil {
return nil, err
}
resBody, err := ioutil.ReadAll(res.Body)
if err != nil {
return nil, err
}
return resBody, nil
}
做的事情,比较简单,就是循环去请求 http://www.baidu.com/ , 然后等待响应。
看上去貌似没啥问题吧。
代码跑起来,也确实能正常收发消息。
但是这段代码跑一段时间,就会出现 i/o timeout 的报错。
Get "http://www.baidu.com/": read tcp 192.168.2.157:23633->14.215.177.39:80: i/o timeout
这其实是最近排查了的一个问题,发现这个坑可能比较容易踩上,我这边对代码做了简化。
实际生产中发生的现象是,golang服务在发起http调用时,虽然http.Transport设置了3s超时,会偶发出现i/o timeout的报错。
但是查看下游服务的时候,发现下游服务其实 100ms 就已经返回了。
就很奇怪了,明明服务端显示处理耗时才100ms,且客户端超时设的是3s, 怎么就出现超时报错 i/o timeout 呢?
这里推测有两个可能。
-
因为服务端打印的日志其实只是服务端应用层打印的日志。但客户端应用层发出数据后,中间还经过客户端的传输层,网络层,数据链路层和物理层,再经过服务端的物理层,数据链路层,网络层,传输层到服务端的应用层。服务端应用层处耗时100ms,再原路返回。那剩下的3s-100ms可能是耗在了整个流程里的各个层上。比如网络不好的情况下,传输层TCP使劲丢包重传之类的原因。
-
网络没问题,客户端到服务端链路整个收发流程大概耗时就是100ms左右。客户端处理逻辑问题导致超时。
一般遇到问题,大部分情况下都不会是底层网络的问题,大胆怀疑是自己的问题就对了,不死心就抓个包看下。
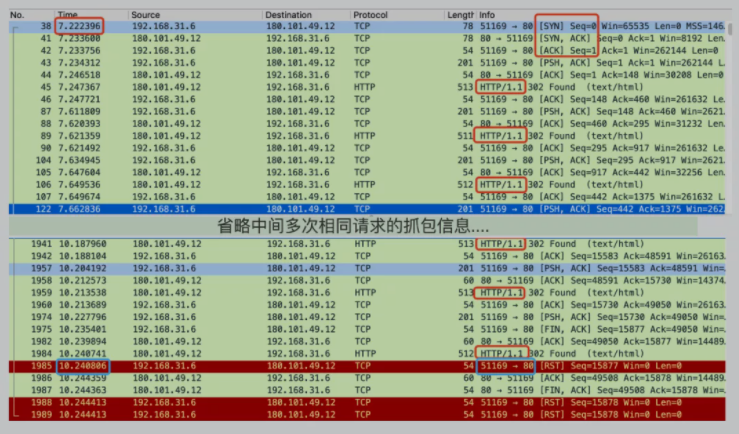
分析下,从刚开始三次握手(画了红框的地方)。
到最后出现超时报错 i/o timeout (画了蓝框的地方)。
从time那一列从7到10,确实间隔3s。而且看右下角的蓝框,是51169端口发到80端口的一次Reset连接。
80端口是服务端的端口。换句话说就是客户端3s超时主动断开链接的。
但是再仔细看下第一行三次握手到最后客户端超时主动断开连接的中间,其实有非常多次HTTP请求。
回去看代码设置超时的方式。
tr = &http.Transport{
MaxIdleConns: 100,
Dial: func(netw, addr string) (net.Conn, error) {
conn, err := net.DialTimeout(netw, addr, time.Second*2) //设置建立连接超时
if err != nil {
return nil, err
}
err = conn.SetDeadline(time.Now().Add(time.Second * 3)) //设置发送接受数据超时
if err != nil {
return nil, err
}
return conn, nil
},
}
也就是说,这里的3s超时,其实是在建立连接之后开始算的,而不是单次调用开始算的超时。
看注释里写的是
SetDeadline sets the read and write deadlines associated with the connection.
大家知道HTTP是应用层协议,传输层用的是TCP协议。
HTTP协议从1.0以前,默认用的是短连接,每次发起请求都会建立TCP连接。收发数据。然后断开连接。
TCP连接每次都是三次握手。每次断开都要四次挥手。
其实没必要每次都建立新连接,建立的连接不断开就好了,每次发送数据都复用就好了。
于是乎,HTTP协议从1.1之后就默认使用长连接。具体相关信息可以看之前的 这篇文章。
那么golang标准库里也兼容这种实现。
通过建立一个连接池,针对每个域名建立一个TCP长连接,比如http://baidu.com和http://golang.com 就是两个不同的域名。
第一次访问http://baidu.com 域名的时候会建立一个连接,用完之后放到空闲连接池里,下次再要访问http://baidu.com 的时候会重新从连接池里把这个连接捞出来复用。
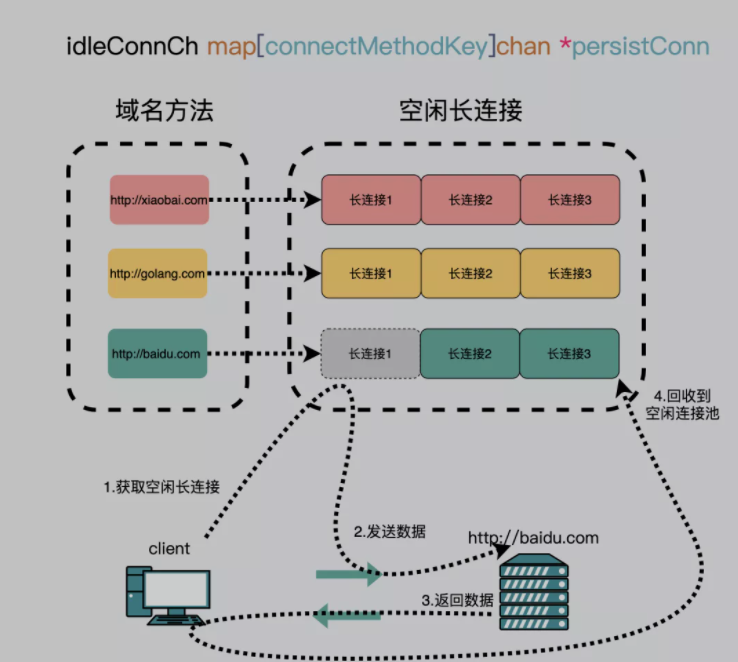
假设第一次请求要100ms,每次请求完http://baidu.com 后都放入连接池中,下次继续复用,重复29次,耗时2900ms。
第30次请求的时候,连接从建立开始到服务返回前就已经用了3000ms,刚好到设置的3s超时阈值,那么此时客户端就会报超时 i/o timeout 。
虽然这时候服务端其实才花了100ms,但耐不住前面29次加起来的耗时已经很长。
也就是说只要通过 http.Transport 设置了 err = conn.SetDeadline(time.Now().Add(time.Second * 3)),并且你用了长连接,哪怕服务端处理再快,客户端设置的超时再长,总有一刻,你的程序会报超时错误。
所以,超时时间不应该设置在连接上,而应该设置在请求这个动作上。修改代码。
package main
import (
"bytes"
"encoding/json"
"fmt"
"io/ioutil"
"net/http"
"time"
)
var tr *http.Transport
func init() {
tr = &http.Transport{
MaxIdleConns: 100,
}
}
func main() {
for {
_, err := Get("http://www.baidu.com/")
if err != nil {
fmt.Println(err)
break
}
}
}
func Get(url string) ([]byte, error) {
m := make(map[string]interface{})
data, err := json.Marshal(m)
if err != nil {
return nil, err
}
body := bytes.NewReader(data)
req, _ := http.NewRequest("Get", url, body)
req.Header.Add("content-type", "application/json")
client := &http.Client{
Transport: tr,
Timeout: 3 * time.Second, // 超时加在这里,是每次调用的超时
}
res, err := client.Do(req)
if res != nil {
defer res.Body.Close()
}
if err != nil {
return nil, err
}
resBody, err := ioutil.ReadAll(res.Body)
if err != nil {
return nil, err
}
return resBody, nil
}
并没有出现超时的问题,但是出现了Get "http://www.baidu.com/": EOF,这个是因为调用得太猛了,http://www.baidu.com 那边主动断开的连接,可以理解为一个限流措施,目的是为了保护服务器。解决方案很简单,每次HTTP调用中间加个sleep间隔时间就好。
源码跟踪
用的go版本是1.12.7。
从发起一个网络请求开始
res, err := client.Do(req)
func (c *Client) Do(req *Request) (*Response, error) {
return c.do(req)
}
func (c *Client) do(req *Request) {
// ...
if resp, didTimeout, err = c.send(req, deadline); err != nil {
// ...
}
// ...
}
func send(ireq *Request, rt RoundTripper, deadline time.Time) {
// ...
resp, err = rt.RoundTrip(req)
// ...
}
// 从这里进入 RoundTrip 逻辑
/src/net/http/roundtrip.go: 16
func (t *Transport) RoundTrip(req *Request) (*Response, error) {
return t.roundTrip(req)
}
func (t *Transport) roundTrip(req *Request) (*Response, error) {
// 尝试去获取一个空闲连接,用于发起 http 连接
pconn, err := t.getConn(treq, cm)
// ...
}
// 重点关注这个函数,返回是一个长连接
func (t *Transport) getConn(treq *transportRequest, cm connectMethod) (*persistConn, error) {
// 省略了大量逻辑,只关注下面两点
// 有空闲连接就返回
pc := <-t.getIdleConnCh(cm)
// 没有创建连接
pc, err := t.dialConn(ctx, cm)
}
没有空闲连接,就创建长连接。
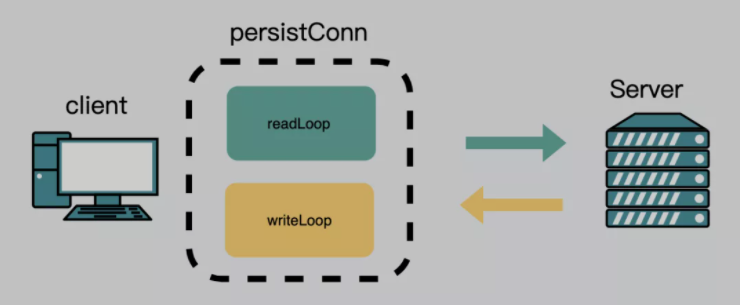
func (t *Transport) dialConn() {
//...
conn, err := t.dial(ctx, "tcp", cm.addr())
// ...
go pconn.readLoop()
go pconn.writeLoop()
// ...
}
当第一次发起一个http请求时,这时候肯定没有空闲连接,会建立一个新连接。同时会创建一个读goroutine和一个写goroutine。
最后
以上就是完美小笼包最近收集整理的关于Go 中 net/http 包的timeout超时设置的全部内容,更多相关Go内容请搜索靠谱客的其他文章。








发表评论 取消回复