目录
1.User-Agent(请求头header中的一个属性)
2.IP(IP地址是指互联网协议地址)
3.Cookie(储存在用户本地终端上的数据),对简单的一些cookie反爬进行说明
4.post请求参数加密
5.浏览器环境检测
6.验证码 (使用selenium如果截图不正确的话,确保浏览器最大化、电脑显示布局百分百,点击坐标也是需要这些的,不然会出错)
7.header中的一些其他属性
8.视频反爬
9.其他
10.一些建议
1.User-Agent(请求头header中的一个属性)
用户代理(User Agent,简称 UA),是一个特殊字符串头,使得服务器能够识别客户使用的操作系统及版本、CPU 类型、浏览器及版本、浏览器渲染引擎、浏览器语言、浏览器插件等。
部分网站会对UA进行检测,爬虫工程师在一般情况下写爬虫代码时第一件事就是定义一个UA,
由于没有什么技术要求,许多网站取消或不使用UA来识别爬虫,
解决办法:
但有时候使用了UA,觉得网站没有什么其他反爬手段了,就是没有返回正常或完整的数据时,原因就有可能是UA表现出来的版本问题,建议更换最新的UA,
UA虽然没有任何技术,但个别网站还是会对UA检测,对于访问频率过快时或需要建立长期的爬虫框架时可以手动创建UA池,请求时随机更换或返回数据失败时更换UA,
对于UA池也可以使用python的ake_useragent库,用法:
#导包
from fake_useragent import UserAgent
#随机获取一条UA
print(UserAgent().random)
#fake_useragent 的其他用法可自行百度2.IP(IP地址是指互联网协议地址)
IP地址是IP协议提供的一种统一的地址格式,它为互联网上的每一个网络和每一台主机分配一个逻辑地址,以此来屏蔽物理地址的差异。
在爬虫爬取数据中如果使用并发对网站数据进行请求的,部分网站会对同一IP地址进行限制,包括中途加入各种验证(验证码,手机验证码,滑块等)、
提示稍后再试(10分钟后)、
返回空数据、返回假数据、返回脏数据、
将IP地址加入黑名单(只有本地公网地址发生变化时或IP进入黑名单已一定时长(一天))
解决办法:
在使用IP代理时建议购买代理或注册登录后体验使用,现在一般免费不需要登录的网站提供的IP代理使用成功率低于百分之五不到,而且能用质量也很差,以前很多网站有直接免费的测试的很好用,现在网站不一样了,但只要特别想用免费的,还是能找到的,建议找好网站确定能用(如果是初学者有时就因为免费的IP代理用不了,以为是代码写错了)
对于网站有IP反爬时,本地跑爬虫可以使用一些更换本地主机IP的软件,设置全局使用,无需添加爬虫配置代码(如果想测试体验IP的话,体验的IP是真的差,哈哈哈)
不是用软件的话可以,在本地或服务器创建代理IP池(用来充分合理使用IP代理的管理服务)来管理IP将正常可用的IP放到redis(redis(Remote Dictionary Server ),即远程字典服务,是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API),可以百度IP池原理来写出自己的代理IP池,
或使用目前流行的开源IP代理池服务(根据说明自行配置)地址如下:
https://github.com/jhao104/proxy_pool
3.Cookie(储存在用户本地终端上的数据),对简单的一些cookie反爬进行说明
Cookie,有时也用其复数形式 Cookies。类型为“小型文本文件”,是某些网站为了辨别用户身份,进行Session跟踪而储存在用户本地终端上的数据(通常经过加密),由用户客户端计算机暂时或永久保存的信息
解决办法:
爬虫不需要登录时,需要cookie验证
1.部分网站在浏览器请求时,response中会有一条set-cookie,将此cookie值放到请求中去就可以正常访问
2.一些请求中的cookie的部分值可以在起始链接的响应中找到,使用正则提取或其它办法,拼接到要使用cookie中
3.使用浏览器正常访问网站,然后复制其请求中的cookie,(百度搜索的cookie时效就很长,没有具体测试过)
4.无法准确地确定或找到cookie生成的办法时,因为cookie会变,所以可以使用一些通用的办法,比如在每次启动爬虫时或在爬虫过程中检测cookie是否失效,失效可以使用selenium模拟访问通过浏览器对象获取cookie并写成请求所需的格式替换原有的cookie
driver.get('http://www.baidu.com/')
headers={}
headers['cookie'] = ';'.join([v['name'] + '=' + v['value'] for v in driver.get_cookies()])爬虫需要登录时,需要cookie验证
1.上述第三条、第四条可以完美解决
2.resquests对登录的操作
from requests import Session
#创建session实例对象,使用session对网站进行请求
s=Session()
data={"redata": "{"sendData":{"username":"**********","password":"******"}"}
s.post('https://***/login.html',data)
#获取个人中心信息
print(s.get('https://***/index.html').text)3.scrapy在setting中开启cookie即可
4.post请求参数加密
简单的加密可以根据加密后的字符串进行解密python有一些相应的加密解密或编码库
比如:
base64编码
1.标准base64只有64个字符(英文大小写、数字和+、/)以及用作后缀等号;
2.base64是把3个字节变成4个可打印字符,所以base64编码后的字符串一定能被4整除(不算用作后缀的等号);
3.等号一定用作后缀,且数目一定是0个、1个或2个。这是因为如果原文长度不能被3整除,base64要在后面添加�凑齐3n位。为了正确还原,添加了几个�就加上几个等号。显然添加等号的数目只能是0、1或2;
4.严格来说base64不能算是一种加密,只能说是编码转换。使用base64的初衷,是为了方便把含有不可见字符串的信息用可见字符串表示出来,以便复制粘贴;
md5加密
1.针对不同长度待加密的数据、字符串等等,其都可以返回一个固定长度的MD5加密字符串。(通常32位的16进制字符串);
2.对于一个固定的字符串,数字等等,MD5加密后的字符串是固定的,也就是说不管MD5加密多少次,都是同样的结果。
MD5免费在线解密破解_MD5在线加密-SOMD5一个免费的MD5解密网站
也可以直接复制加密后的字符串进行多接口尝试,如果不是动态的那更好了
5.浏览器环境检测(比如判断js运行环境是否为node.js)
麻烦点的话就要去js逆向,补环境、改原js代码(比如判断js运行环境的代码直接改为返回false)(数据量不是很大的话一般不建议)
可以使用selenium、splash配合requests、splash配合scrapy来获取数据
selenium的.text方法有时获取不到文本有的是元素页面不可见,可以参考下方链接
https://blog.csdn.net/qq_27900321/article/details/124241530?spm=1001.2014.3001.5501
6.验证码 (使用selenium如果截图不正确的话,确保浏览器最大化、电脑显示布局百分百,点击坐标也是需要这些的,不然会出错)
推荐使用的github上的验证码识别项目(可能有验证码、滑块、文字顺序、坐标等验证)
GitHub - sml2h3/ddddocr: 带带弟弟 通用验证码识别OCR pypi版
1.图片验证码
现在的网站图片验证码已经大部分变为了动态的,就是使用同一个验证码图片链接去请求每一次返回的图片链接都不一样
使用selenium进行验证码图片进行截取,然后也可以使用识别验证码平台(比如超级鹰)
2.滑块、文字顺序、坐标等验证
验证用到的图片有的是链接,有的是许多顺序杂乱、位置杂乱小的图片拼起来的
看情况是链接就下载,是拼的截图
得到图片-识别-操作浏览器滑动或点击
截图代码
from PIL import Image
from selenium.webdriver import Firefox
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By
driver = Firefox()
driver.get('http://*********')
driver.get_screenshot_as_file('验证码截图/验证码.png')
# 获取指定元素位置
element = driver.find_element_by_id('6666')
left = int(element.location['x'])
top = int(element.location['y'])
right = int(element.location['x'] + element.size['width'])
bottom = int(element.location['y'] + element.size['height'])
# 通过Image处理图像
im = Image.open('验证码截图/验证码.png')
im = im.crop((left, top, right, bottom))
im.save('验证码截图/验证码.png')
#进行验证
ActionChains(driver).click_and_hold(on_element=driver.find_element(By.ID,'6666')).perform() # 点击鼠标左键,按住不放
ActionChains(driver).move_by_offset(xoffset=666, yoffset=0).perform() # 鼠标移动到距离当前位置(x,y)
ActionChains(driver).release(on_element=slid_ing).perform()#释放鼠标7.header中的一些其他属性
比如:
referer,用于指明当前流量的来源参考页面。通过这个信息,我们可以知道访客是怎么来到当前页面的。这对于web analytics非常重要,可以用于分析不同渠道流量分布、用户搜索的关键词等。
有的网站也会根据referer属性判断是否是正常用户发送的请求,需要在header中referer添加属性
Token在计算机身份认证中是令牌(临时)的意思,
Token可以分析生成,也可以复制,或模拟浏览器直接获取
8.视频反爬
部分网站的视频爬取是很麻烦的,有的下载了还不能正常播放
这里需要换一下思路,可以解决一部分网站视频的爬取(有通用的办法,不需要多余的代码,只需要转换下思路)
解决办法就不写了(可能我也不会,哈哈哈)
9.其他
1.字体反爬,需要下载获取响应中对应的字体文件进行分析
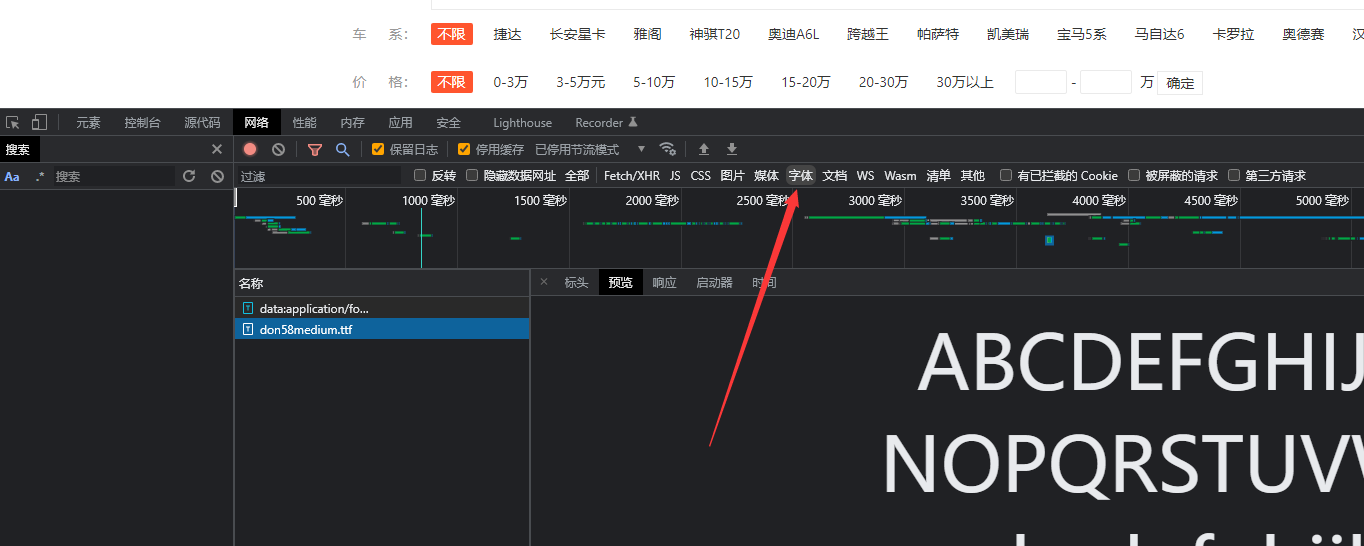
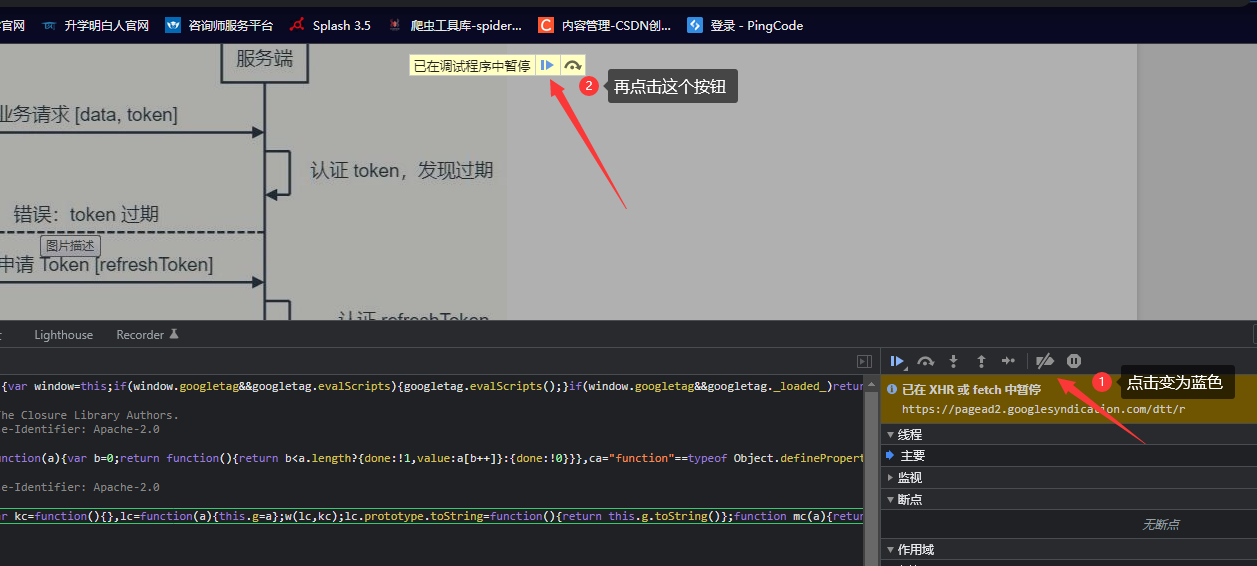
2.网站阻止调试,如果不进行js逆向调试,只是抓包可以这样操作,没有跳出调试模式,可多操作几下步骤2,直至正常
3.在使用selenium中的一些问题
①网页加载时间长,可以使用显性等待
②元素无法定位,部分原因是因为需要下拉滚动条
③现在许多网站使用前端UI框架,导致selenium很多情况,无法简单操作的元素,只能加入很多代码,模拟手动一步一步操作
4.网站中标签混乱或标签顺序层级不按套路出牌,导致数据按规则提取困难(不知道是因为网站做的不好还是因为反爬)
这是这时候就考验xpath和正则,一些其他方法的使用了,有时必须有很强的逻辑代码去整理数据(加油,打工人)
10.一些建议
1.爬虫爬取数据有时候思路很重要,爬虫重要的是要获取数据,对于初学者来说,有时可能想办法过各种验证,再去拿数据,会写一长串的代码,找接口识别,好在这一两年github上有许多免费的效果非常好的库,可以直接使用。
但其实有时候完全没必要,特别是只需要爬取一次数据的时候,完全可以手动过验证或登录,直接复制其请求头中的属性和请求体加进代码
2.有的网站查看数据是需要登录或开通会员的,这在爬取过程中需要写入相应的代码。
其中一部分网站是在请求接口是会发现完全不需要登陆后的一些验证信息,只是网页端阻止操作而已。这种网站还能省去会员的钱(哈哈哈哈)!!!
3.在获取页面数据列表时,需要携带页码和每页展示的数量
page=1,num=10有1000条数据需要循环100次
部分网站可以直接将参数改为page=1,num=10000,给个超出数量的每页展示数量,就能一次性获取到所有数据
4.selenium获取到的页面元素和看到的不完整或在定位报错无法定位
①.页面未加载完成,使用等待(隐性等待,显性等待,强制等待)
②.一个原因是网页有iframe标签,iframe是HTML标签,作用是文档中的文档,或者浮动的框架(FRAME)。iframe元素会创建包含另外一个文档的内联框架(即行内框架)。
只需要进入iframe标签就可以了
#切出
iframe_path = self.driver.find_element(By.ID, '666')
self.driver.switch_to.frame(iframe_path)
#切出
self.driver.switch_to.default_content()后续还会更新!!!!
最后
以上就是苹果机器猫最近收集整理的关于一些简单常见的网站反爬策略和解决办法的全部内容,更多相关一些简单常见内容请搜索靠谱客的其他文章。








发表评论 取消回复