大家好,我是Python之眼。
最近有朋友们看了《爬取贝壳找房8万+二手房源,看看普通人在北京买房是有多难》之后,想爬取自己所在城市的成交房源数据做做分析之类的。
那么,今天我们就详情介绍下整个数据采集过程吧!
目录:
- 这是准备阶段
- 一如既往的页面分析
- 二话不说的数据请求
- 三复斯言的数据解析
- >>寻找数据字段所在节点
- >>re数据解析
- >>获取全部页面房源数据
- 四平八稳的数据清洗
- >>数据去重
- >>标题、朝向装修、楼层楼龄及位置信息清洗
- >>最终数据预览
注:贝壳网目前部分城市是不显示成交房源信息的,这里只对公开信息做采集!
这是准备阶段
本次我们的组合拳是基于python的requests+re+pandas。
引入需要用到的库:
import re
import requests
import pandas as pd了解我们需要采集的数据字段:
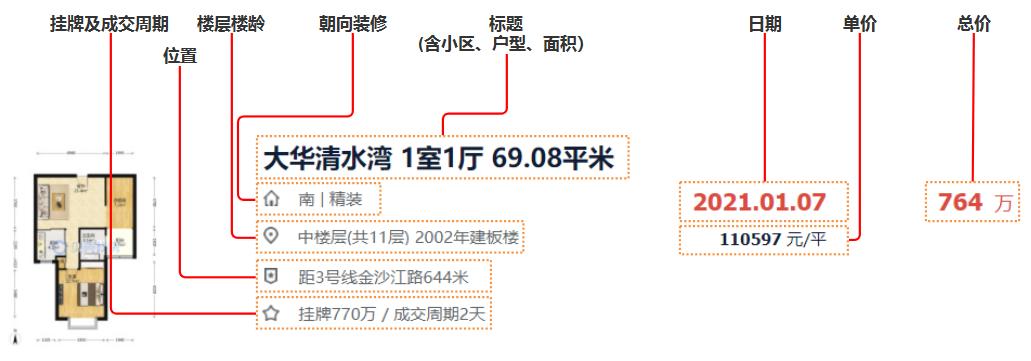 待采集数据字段
待采集数据字段
一如既往的页面分析
以上海为例,我们打开二手房成交房源页面,网址https://sh.ke.com/chengjiao/pg2/。sh是指上海,大家可以根据自己所在的城市调整。
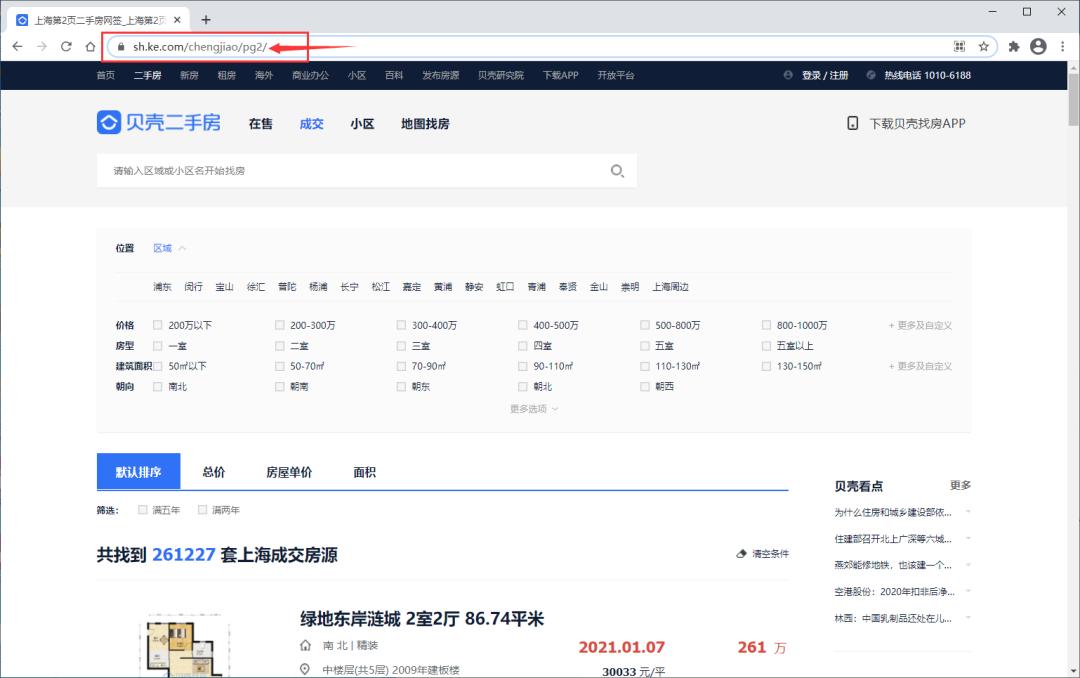 上海二手房
上海二手房
我们进行翻页操作,发现网址只有pg2部分的数字发生变化,而且和页码数是一致的。真好,基于这个简单的规律,我们可以组合出全部100页的url地址。
# 构建全部100个页面url地址
urls = []
for i in range(1,101):
urls.append(f'https://sh.ke.com/chengjiao/pg{i}/') urls
urls
二话不说的数据请求
直接请出requests.get(url)方法,由于我们这次采用re正则表达式来解析数据,所以可以将请求的网页数据中的非字符数据去掉备用。
def get_html(url):
headers = {
"Accept-Encoding": "Gzip", # 使用gzip压缩传输数据让访问更快
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36",
}
resp = requests.get(url, headers= headers)
html = resp.text
html = re.sub('s', '', html) # 将html文本中非字符数据去掉
return html
片段数据预览
三复斯言的数据解析
我们使用的是re正则表达式进行数据解析,关于re正在表达式更详细的用法大家可以参考此前推文《对着爬虫网页HTML学习Python正则表达式re》。
>>寻找数据字段所在节点
- 由于每页有多个房源信息,我们先找到房源列表所在的节点区域
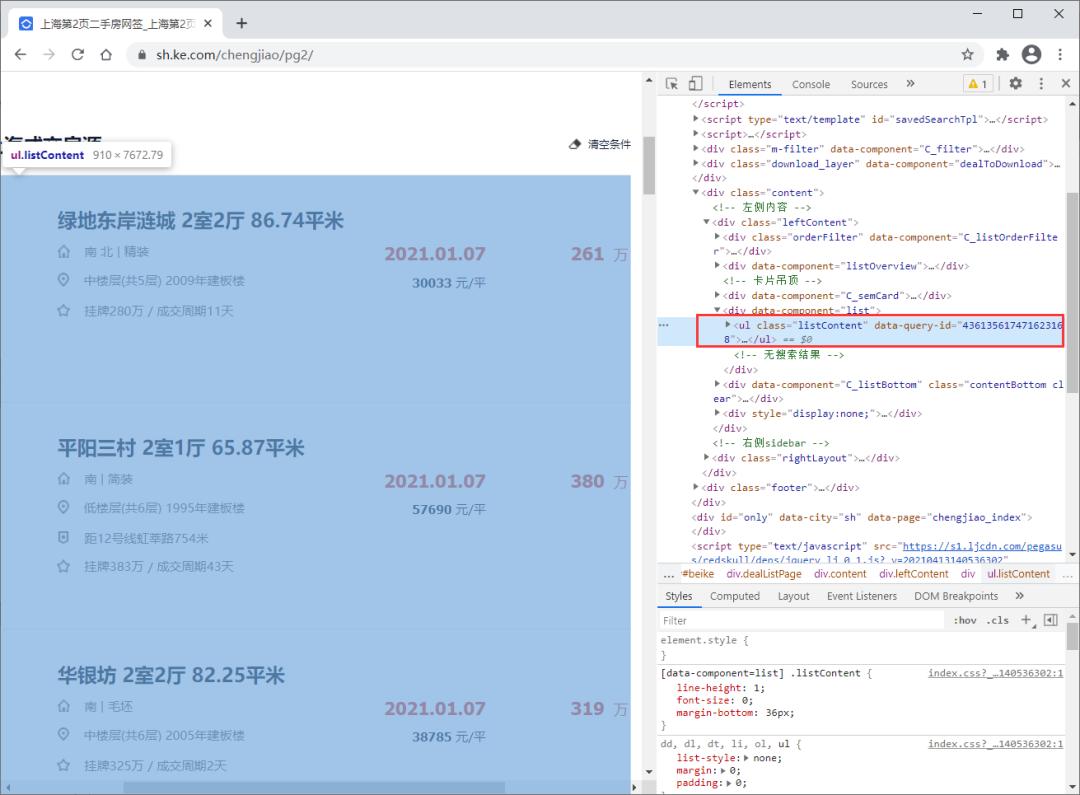 每页房源列表所在节点
每页房源列表所在节点
- 接着再看每个房源所在的节点区域,并确定每个数据字段所在的节点(比如标题信息、价格信息等)
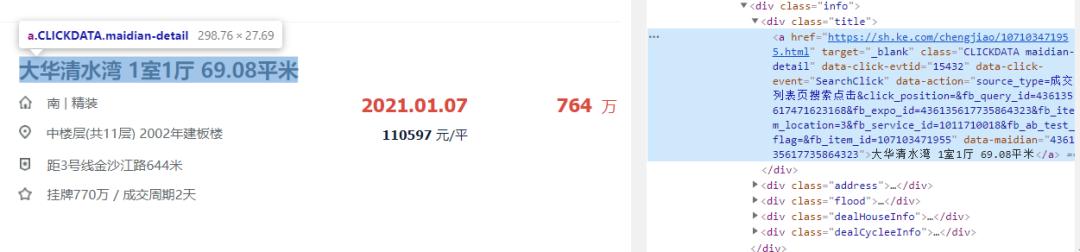 标题信息
标题信息
 总价信息
总价信息
>>re数据解析
为了更好的进行数据解析,可以先匹配到每页全部房源节点数据,然后再解析出每页全部房源信息列表。
解析获取房源列表数据:
ListContent = re.findall(r'<ulclass="listContent"data-query-id="d+">(.*?)</ul>', html)[0]
Lists = re.findall(r'<divclass="info">(.*?)</li>', ListContent) 房源列表数据预览
房源列表数据预览
解析获取单个房源数据:
根据单个房源信息数据字段,利用正则表达式一一解析,由于并非全部房源均有各个字段信息,所以这里采用findall后并没有直接切片获取字符串,我们放在后续数据清洗阶段处理。
List = Lists[3]
def get_house_info(List):
house_info = {
'房源ID' : re.findall(r'fb_item_id=(d+)',List),
'标题' : re.findall(r'<divclass="title"><ahref=".*?">(.*?)</a>',List),
'朝向装修' : re.findall(r'<divclass="houseInfo"><spanclass="houseIcon"></span>(.*?)</div>',List),
'日期' : re.findall(r'<divclass="dealDate">(.*?)</div>',List),
'总价' : re.findall(r'<divclass="totalPrice"><spanclass='number'>(.*?)</span>',List),
'楼层楼龄' : re.findall(r'<divclass="positionInfo"><spanclass="positionIcon"></span>(.*?)</div>',List),
'单价' : re.findall(r'<divclass="unitPrice"><spanclass="number">(.*?)</span>',List),
'位置' : re.findall(r'<spanclass="dealHouseTxt"><span>(.*?)</span>',List),
'挂牌价' : re.findall(r'<spanclass="dealCycleTxt"><span>挂牌(.*?)万</span>',List),
'成交周期' : re.findall(r'<span>成交周期(.*?)天</span>',List),
}
return house_info 房源数据信息
房源数据信息
>>获取全部页面房源数据
直接遍历全部url并解析每一个url下全部房源数据即可,有兴趣的可以采用多进程等加速处理。(需要注意的是,贝壳这边存在ip反爬,如果爬取数据量过大或者频率过高会请求不到想要的数据,可以设置请求间隔或者代理ip的方式处理,本文这里不做详细展开)
house_infos = []
num = 0
for url in urls:
html = get_html(url)
ListContent = re.findall(r'<ulclass="listContent"data-query-id="d+">(.*?)</ul>', html)[0]
Lists = re.findall(r'<divclass="info">(.*?)</li>', ListContent)
for List in Lists:
num = num+1
house_info = get_house_info(List)
house_infos.append(house_info)
print(f'r{num}个成交房源数据已采集...', end='')
df = pd.DataFrame(house_infos) 数据预览
数据预览
四平八稳的数据清洗
由于我们在数据解析的时候得到的每个字段的元素都是元素为1或0个的列表,这里需要解析为字符串,直接用explode()即可。
df = df.apply(lambda x : x.explode()) 初步解析
初步解析
>>数据去重
按照房源ID进行去重即可。
df.drop_duplicates(subset='房源ID',inplace=True)>>标题、朝向装修、楼层楼龄及位置信息清洗
标题可以清洗出 小区、户型和面积三个字段,我们直接用extract()方法进行处理。
df.标题.str.extract(r'(?P<小区>.+?)(?P<户型>d+室.*?[厅]*)(?P<面积>d+.*d*?)平米')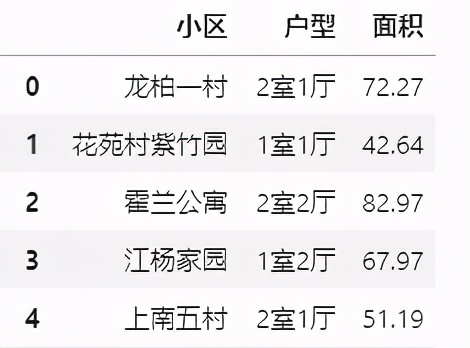 标题清洗
标题清洗
朝向装修 就是朝向和装修
df.朝向装修.str.extract(r'(?P<朝向>.*)|(?P<装修>.*)') 朝向装修
朝向装修
楼层楼龄 就是楼层(高中低)和建筑年龄
df.楼层楼龄.str.extract(r'(?P<楼层>.*)(.*?)(?P<楼龄>d+)年') 楼层楼龄
楼层楼龄
位置信息 就是 地铁线路、地铁及距离地铁距离
df.位置.str.extract(r'(?P<地铁线路>.*线)(?P<地铁>.*?)(?P<距离>d+)米')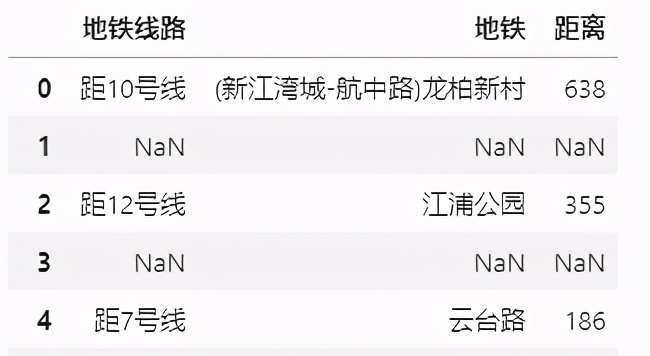 位置信息
位置信息
>> 最终数据预览
df[['房源ID', '日期', '小区','户型','面积','总价', '单价', '挂牌价', '成交周期',
'朝向', '装修', '楼层', '楼龄', '地铁线路', '地铁', '距离']]
 最终数据预览
最终数据预览
到这一步,我们就完成了全部数据采集与清洗,接着就可以对这些数据进行数据分析处理和可视化展示了。
关于本文全部代码,申请QQ群:705933274 免费领取
最后
以上就是干净唇膏最近收集整理的关于Python爬虫 | 手把手教你扒一扒贝壳网成交房源数据这是准备阶段一如既往的页面分析二话不说的数据请求三复斯言的数据解析>>寻找数据字段所在节点>>re数据解析>>获取全部页面房源数据四平八稳的数据清洗>>数据去重>>标题、朝向装修、楼层楼龄及位置信息清洗>> 最终数据预览的全部内容,更多相关Python爬虫内容请搜索靠谱客的其他文章。






![安居客[58租房]爬虫--解决ttf字体反爬解决安居客ttf字体反爬虫最终代码如下](https://www.shuijiaxian.com/files_image/reation/bcimg12.png)

发表评论 取消回复